前言
TensorFlow 是谷歌开源的深度学习工具包,它将深度学习复杂的计算过程抽象成了数据流图(Data Flow Graph),并提供简介灵活的高级抽象接口,让小白用户通过简单的学习就可以使用「高大上」的深度学习了。当谷歌被问到为什么要开源 TensorFlow 时,他们的回答是:「我们相信机器学习是未来创新产品和技术的关键因素」。其实目前我们生活的很多方面已经被机器学习深切的影响着了,从谷歌搜索到淘宝购物,以及在刚刚结束的老罗手机发布会上,引起台下欢呼不断的语音输入以及 「BigBang」,背后的核心技术都是机器学习。因此,我觉得广大程序员有必要学习下机器学习,以免被很快就会到来的「未来」所抛弃。
安装
官方的安装文档是最详细的,以我本人的电脑(MacBook Pro,python 2.7)为例,安装过程如下:
// 指定 TensorFlow 地址
export TF_BINARY_URL=https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-0.11.0rc1-py2-none-any.whl
// 使用 pip 安装(如果没有 pip,得先安装 pip)
sudo pip install --upgrade $TF_BINARY_URL
安装好后,可以进入 python 交互界面,执行以下代码确认是否安装成功:
$ python
>>> import tensorflow as tf
>>> hello = tf.constant('Hello, TensorFlow!')
>>> sess = tf.Session()
>>> print(sess.run(hello))
Hello, TensorFlow!
>>> a = tf.constant(10)
>>> b = tf.constant(32)
>>> print(sess.run(a + b))
42
简介
整体工作方式
TensorFlow 最基本的一次计算过程是这样的:接受 n 个固定格式的数据输入,通过给定的高级函数,转化为 n 个 Tensor 格式的输出。当然一次机器学习的过程会有很多次这样的计算,一次计算的输出可能是下一次计算的(部分或全部)输入,TensorFlow 将这一系列的计算过程抽象为了一张数据流图(Data Flow Graph),如图:
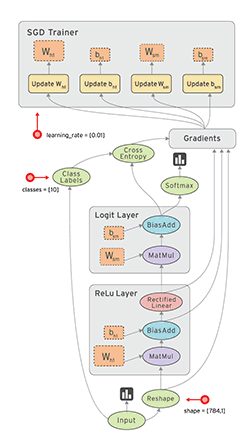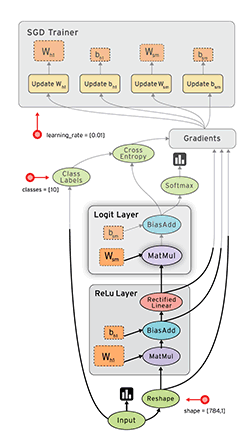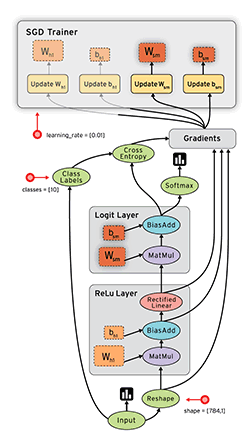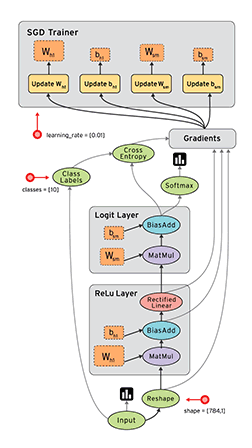
上图中从数据 Input 开始,沿着有向图进行计算,图中每个节点都是一次计算,称为 op(option),TensorFlow 中数据以 Tensor 为格式,输入一个 Tensor ,经过一次 op 后输出另一个 Tensor,然后根据数据流图进入下一个 op 作为输入,因此,整个计算过程其实是一个 Tensor 数据的流动过程,所以谷歌将这个系统形象的叫做 TensorFlow。
有了数据流图后下一个问题是如何在各种设备上很好的运行,TensorFlow 通过一个会话(Session)来控制整个数据流图的执行。TensorFlow 一个很大的优点是将复杂的运算(如矩阵运算,softmax)封装成了高级函数,用户只要使用就好了,在内部,TensorFlow 将这些函数转化成可以高效在 CPU 或 GPU 执行的机器码。Session 的主要作用是将这张数据流图合理的切分(尽量减少 Session 与 CPU 或 GPU 之间的交互,因为很慢),按照一定的顺序提交给 CPU 或者 GPU,然后(可能)还进行一些容错的机制,总之 Session 就是负责高效地让数据流图被 CPU 或 GPU 执行完成的。
如果读者对 spark 熟悉,看完以上介绍后会不会觉得其实 TensorFlow 的整个工作流程其实跟 Spark 有很多类似之处(我看完文档之后是这样认为的)。 TensorFlow 的数据流图对应于 Spark 的 DAG,TensorFlow 的 Tensor 对应于 Spark 的 RDD, TensorFlow 的 Session 对应于 Spark 的 SparkContext。待后面深入学习后再分析分析他们的异同。
基本概念
其实很多概念上面已经提到,这里统一介绍下,不过官网的文档是最详细的。
- 数据流图:用来逻辑上描述一次机器学习计算的过程。
- Session:负责管理协调整个数据流图的计算过程。
- op:数据流图中的一个节点,也就是一次基本的操作过程。
- Tensor:所有 TensorFlow 中计算的数据的格式,是一个 n 维的数组,如 t = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] 。
- Variable:这个在上面没有提到。之前我们说一个 Tensor 经过一次 op 后会转化为另一个 Tensor,完成之后上一步的输入 Tensor 就会被回收掉。如果有些数据(如模型)我们需要一直保存,每次迭代计算只是改变其值,这时我们就需要 Variable,Variable 本质上也是一个 Tensor,只不过他是不会被回收,常驻的 Tensor。
基本使用
关于 TensorFlow 的基本使用,其实还是建议看官网,我这边列一个小的 demo 大致看下一个最基本的 TensorFlow 是怎么写的。
// 导入 tensorflow
import tensorflow as tf
// 上面说了数据是从输入到 op 再到输出,用 tf.constant() 生成的是一个源 op,
// 是一个不需要输入(输入已经定义在代码里了),只有输出的 op。
// matrix1、matrix2 都是常量 op
matrix1 = tf.constant([[3., 3.]])
matrix2 = tf.constant([[2.],[2.]])
// 创建一个矩阵乘法 matmul op , 把 'matrix1' 和 'matrix2' 作为输入.
// 返回值 'product' 代表矩阵乘法的结果。
product = tf.matmul(matrix1, matrix2)
// 创建 session
sess = tf.Session()
// 使用 session 运算整个数据流图。这里我们可以看到,
// 定义整个计算过程的时候,我们是从数据输入的方向上往下定义的,
// 而给 session 运行的时候,我们只把最后我们想要结果的那个方法
// 给了 session,说明 session 会根据最终的那步,逆向去追溯计算
// 过程,从而构建整个数据流图(猜的)。
result = sess.run(product)
//输出 [[ 12.]]
print result
//运行结束,关闭 session
sess.close()
看到这里,其实会发现 TensorFlow 并不仅仅是一个训练深度神经网络的工具,它更像是一个计算框架,其实可以在其基础上实现各种算法,有朝一日,如果越来越多的开发者参与其中,构建出更丰富的机器学习库,替代 spark 也是有可能的(虽然我觉得可能性不高)。
一个简单的机器学习实例
官方文档 给出了一个利用 MNIST 数据集训练图像识别模型的入门例子,我这里做一些简单的分析。
MNIST 数据集包含了一个训练集和一个测试集,集合中包含一些 28 像素 X 28 像素的图片(这些图片是手写的 0-9 的数字),以及每张图片的真实数字,我们的目的是通过训练集训练出一个机器学习模型,用以预测任意的手写输入图片所对应的数字。
文档中给的入门示例是一个逻辑回归模型。输入是28 X 28 像素的图片,为了方便,我们将其转化为一个长度为 28 * 28=784 的数组;输出是用 softmax 回归后该图片属于 0-9 各个数字的概率数组。整个模型通过随机梯度下降的方法进行训练,详细的文档里都有,我就其代码简单分析一下:
// 导入 tensorflow
import tensorflow as tf
// 导入处理 MNIST 数据集的工具类
import input_data
// 加载 MNIST 数据集,获得一个封装好的对象 mnist
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
// 设置输入(即手写图像),placeholder 表示 x是一个占位符,
// shape 的 None 表示输入数据的第一维可以任意大小
x = tf.placeholder(tf.float32, shape=[None, 784])
// 设置针对输入图像,其期望的输出
y_ = tf.placeholder(tf.float32, shape=[None, 10])
// 定义 Variable,用于存储隐藏层的权重,W 是一个二维权重矩阵,
// W[i][j] 表示第 i 个像素属于第 j 个数字的概率;b 是一维数组,b[i]
// 表示第 i 个数字的偏移量。因此,要求输入 x 属于各个数字的概率
// 公式为:W * x + b
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
/** 定义好需要的参数变量后,就可以设置训练过程了,训练过程主要分为 3 步:
1. 定义隐藏层的输入输出过程
2. 定义损失函数
3. 选择训练方法开始训练 **/
// 1.定义隐藏层的输入输出过程 :
// 之前我们说用 softmax 回归模型来做隐藏层,TensorFlow 已经实现了
// softmax 的具体方法,所以我们只要一行代码就能表示整个前馈的过程
y = tf.nn.softmax(tf.matmul(x, W) + b)
// 2.定义损失函数:
// 我们使用交叉熵来衡量结果的好坏
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
// 3.选择训练方法开始训练:
// 由于我们已经知道了损失函数,我们的训练目的是让损失函数最小,
// 这里我们使用梯度下降的方法求最小值
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
// 定义好训练过程后,就可以开始真正的训练过程了
// 初始化 session
sess = tf.Session()
//加载所有 variable
init = tf.initialize_all_variables()
sess.run(init)
// 使用随机梯度下降的方法,分批次多次训练
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
//这里随机获取的 batch_xs, batch_ys 用来填充之前定义的占位符 x, y_
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
我们可以看到,只要告诉 TensorFlow 待训练参数、损失函数、具体的训练方法,区区三行代码,它就能自动地进行训练出一个图像识别模型。当然,这只是最简单的一个逻辑回归模型,要想获得好效果,需要用到 卷积神经网络(CNN),等后面深入学习后再跟读者分享。
总结
本文简单介绍了 TensorFlow 的一些基本的概念和工作方式,后面有精力的话再深入的学习下。另外,由于自己对机器学习不是很熟悉,对 TensorFlow 也是刚接触,所以文中可能会有比较多低级错误,望读者看到后指出。
