一、Scrapy架构图
Scrapy框架主要由六大组件组成,它们分别是调度器(Scheduler)、下载器(Downloader)、爬虫(Spider)、中间件(Middleware)、实体管道(Item Pipeline)和Scrapy引擎(Scrapy Engine)
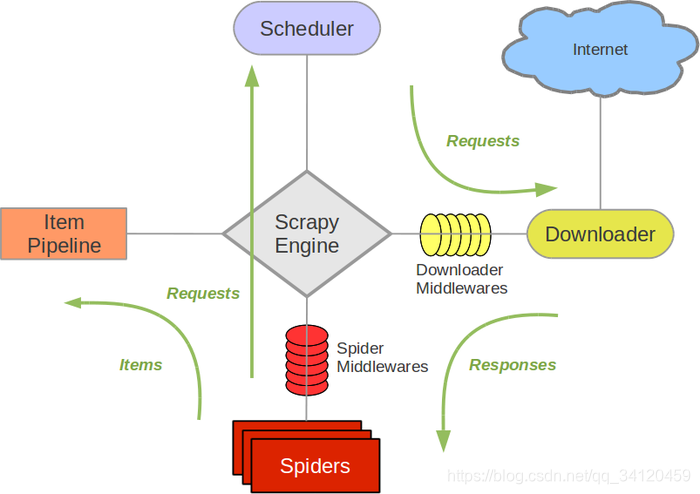
1、Scrapy Engine(引擎): 引擎负责控制数据流在系统的所有组件中流动,并在相应动作发生时触发事件。
2、Scheduler(调度器): 调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
3、Downloader(下载器): 下载器负责获取页面数据并提供给引擎,而后提供给spider。
4、Spider(爬虫): Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
5、Item Pipeline(管道): Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存储到数据库中)。
6、Downloader Middlewares(下载中间件): 下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
7、Spider Middlewares(Spider中间件): Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
二、scrapy工作流程
当我们通过scrapy框架写好代码并运行后,就会出现如下对话:

1、引擎: 怎么样,爬虫老弟,搞起来啊!
2、Spider: 好啊,老哥,来来来,开始吧。今天就爬xxx网站怎么样
3、引擎: 没问题,入口URL发过来!
4、Spider: 呐,入口URL是https://ww.xxx.com。
5、引擎: 调度器老弟,我这有request请求你帮我排序入队一下吧。
6、调度器: 引擎老哥,这是我处理好的request。
7、引擎: 下载器老弟,你按照下载中间件的设置帮我下载一下这个request请求。
8、下载器: 可以了,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
9、引擎: 爬虫老弟,这是下载好的东西,下载器已经按照下载中间件处理过了,你自己处理一下吧。
10、Spider: 引擎老哥,我的数据处理完毕了,这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
11、引擎: 管道老弟,我这儿有个item你帮我处理一下!
12、引擎: 调度器老弟,这是需要跟进URL你帮我处理下。(然后从第四步开始循环,直到获取完需要全部信息)
