Source: https://github.com/llSourcell/7_Research_Directions_Deep_Learning
Topics
- How does Backpropagation work?
- What are the most popular deep learning algorithms today?
- 7 Research Directions I've handpicked
In a recent AI conference, Geoffrey Hinton remarked that he was “deeply suspicious” of back-propagation, and said “My view is throw it all away and start again.”

The billion dollar question - how does the brain learn so well from sparse, unlabeled data?
Let's first understand how backpropagation works
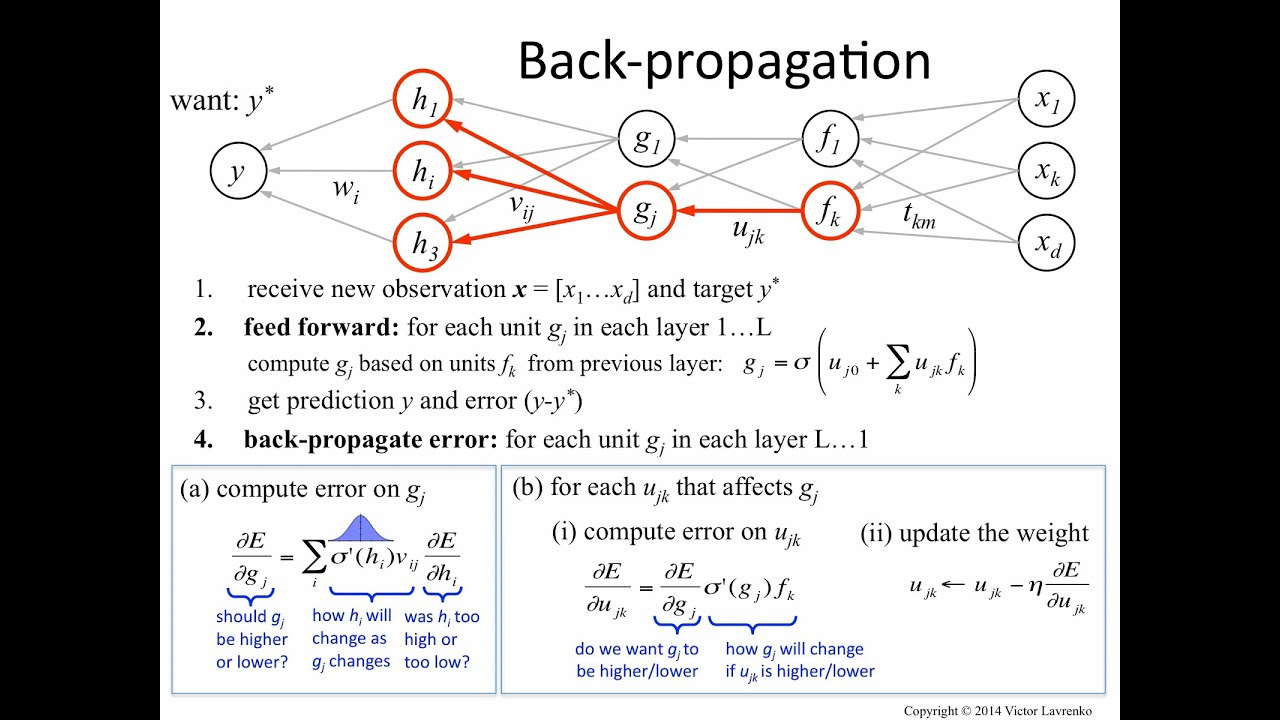
In 1986 Hinton released this paper detailing a new optimization strategy for neural networks called 'backpropagation'. This paper is the reason the current Deep Learning boom is possible.

import numpy as np
#nonlinearity
def nonlin(x,deriv=False):
if(deriv==True):
return x*(1-x)
return 1/(1+np.exp(-x))
#input data
X = np.array([[0,0,1],
[0,1,1],
[1,0,1],
[1,1,1]])
#output data
y = np.array([[0],
[1],
[1],
[0]])
np.random.seed(1)
# randomly initialize our weights with mean 0
syn0 = 2*np.random.random((3,4)) - 1
syn1 = 2*np.random.random((4,1)) - 1



3 concepts behind Backpropagtion (From Calculus)
-
Derivative
 alt text
alt text Partial Derivative

- Chain Rule

for j in xrange(60000):
# Feed forward through layers 0, 1, and 2
k0 = X
k1 = nonlin(np.dot(k0,syn0))
k2 = nonlin(np.dot(k1,syn1))
# how much did we miss the target value?
k2_error = y - k2
if (j% 10000) == 0:
print "Error:" + str(np.mean(np.abs(k2_error)))
# in what direction is the target value?
# were we really sure? if so, don't change too much.
k2_delta = k2_error*nonlin(k2,deriv=True)
# how much did each k1 value contribute to the k2 error (according to the weights)?
k1_error = k2_delta.dot(syn1.T)
# in what direction is the target k1?
# were we really sure? if so, don't change too much.
k1_delta = k1_error * nonlin(k1,deriv=True)
syn1 += k1.T.dot(k2_delta)
syn0 += k0.T.dot(k1_delta)
This is the method of choice for all labeled deep learning models

How do artificial & biological neural nets compare?
Artificial Neural Networks are inspired by the hierarchial structure of brains neural network
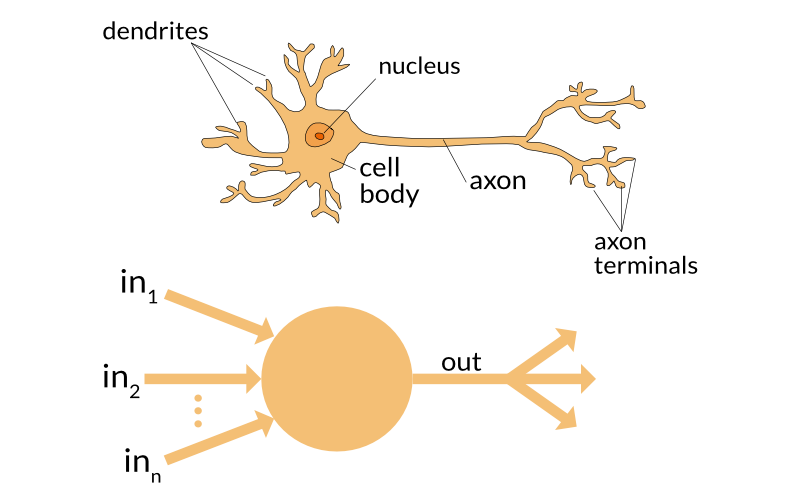
The brain has
-100 billion neurons
-- Each neuron has
- A cell body w/ connections
- numerous dendrites
- A single axon
- Parallel chaining (each neurons connected to 10,000+ others)
- Great at connecting different concepts
Computers have
- Not neurons, but transistors made in silicon!
- Serially chained (each connected to 2-3 others (logic gates))
- Great at storage and recall
Some key differences
- All sensory or motor systems in the brain are recurrent
- Sensory systems tend to have lots of lateral inhibition (neurons inhibiting other neurons in the same layer)
- There is no such thing as a fully connected layer in the brain, connectivity is usually sparse (though not random).
- brains are born pre-wired to learn without supervision.
- The Brain is low power. Alpha GO consumed the power of 1202 CPUs and 176 GPUs, not to train, but just to run. Brain’s power consumption is ~20W.

"the brain is not a blank slate of neuronal layers
waiting to be pieced together and wired-up;
we are born with brains already structured
for unsupervised learning in a dozen cognitive
domains, some of which already work pretty well
without any learning at all." - Steven Pinker
Where are we today in unsupervised learning?
For classification
- Clustering (k-means, dimensionality reduction, anomaly detection)

-
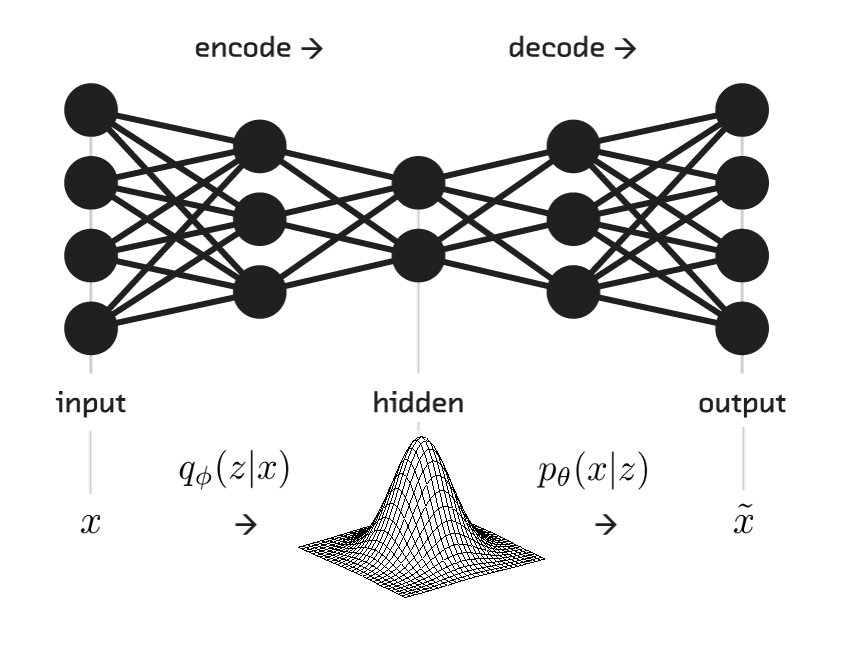
Autoencoders
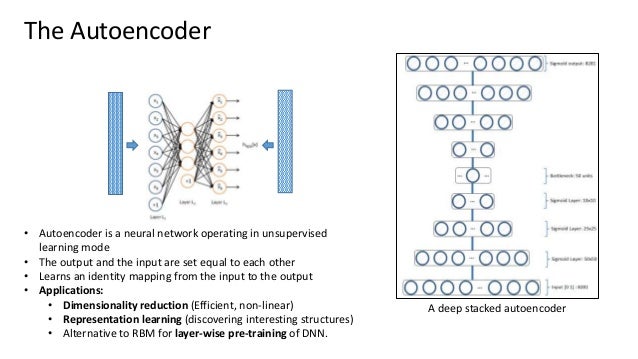 alt text
alt text
For Generation
- Generative Adversarial Networks
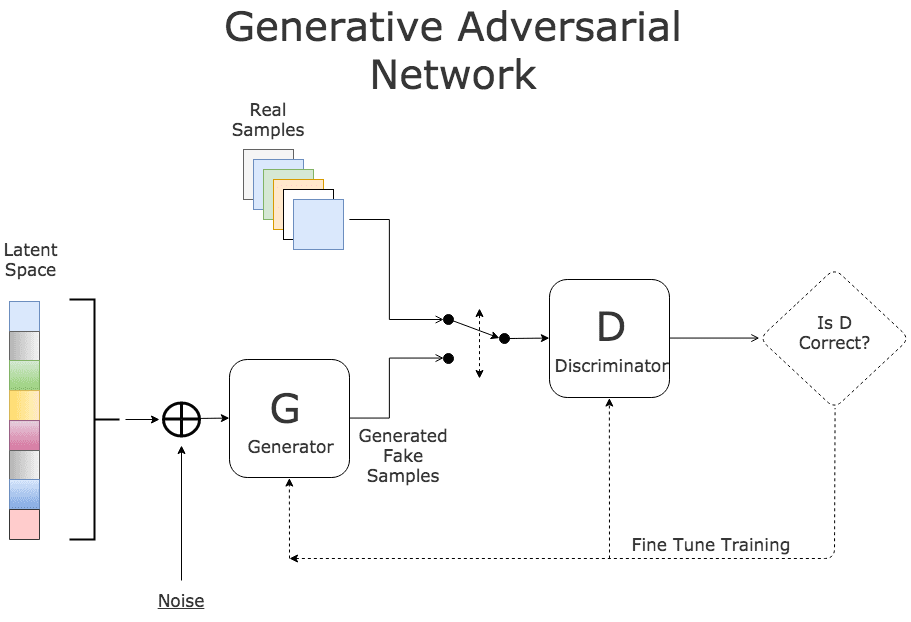
- Variational Autoencoders
- Differentiable Neural Computer
https://en.wikipedia.org/wiki/Differentiable_neural_computer


- The controller receives external inputs and, based on these, interacts with the memory using read and write operations known as 'heads'.
- To help the controller navigate the memory, DNC stores 'temporal links' to keep track of the order things were written in, and records the current 'usage' level of each memory location.
- DNCs were demonstrated, for example, how a DNC can be trained to navigate a variety of rapid transit systems, and then apply what it learned to get around on the London Underground. A neural network without memory would typically have to learn about each different transit system from scratch.
Basically, Many of the best unsupervised methods still require backprop (GANs, autoencoders, language models, word embeddings, etc.
So many GANs (https://deephunt.in/the-gan-zoo-79597dc8c347)
7 Research Directions
Thesis - Unsupervised learning and reinforcement learning must be the primary modes of learning, because labels mean little to a child growing up.
1 Bayesian Deep Learning (smarter backprop)

- Deep learning struggles to model uncertainty.
- Lets use Smarter weight initialization via Bayes Thereom
- So in a bayesian setting the weights of your neural network are now random variables (sampled from a distribution
- The parameters of this distribution are tuned via backpropagation.
2 Spike-Timing-Dependent Plasticity
STDP is a rule that encourages neurons to 'pay more attention' to inputs that predict excitation. Suppose you usually only bring an umbrella if you have reasons to think it will rain (weather report, you see rain outside, etc.). Then you notice that if you see your neighbor carrying an umbrella, even though you haven't seen any rain in the forecast, but sure enough, a few minutes later you see an updated forecast (or it starts raining). This happens a few times, and you get the idea: Your neighbor seems to be getting this information (whether it is going to rain) before your current sources. So in the future, you pay more attention to what your neighbor is doing.

- Suppose we have two neurons, A and B.
- A synapses onto B ( A->B ).
- The STDP rule states that if A fires and B fires after a short delay, the synapse will be potentiated (i.e. B will increase the 'weight' assigned to inputs from A in the future).
- The magnitude of the weight increase is inversely proportional to the delay between A firing and B firing.
- if A fires and then B fires ten seconds later, the weight change will be essentially zero. - - But if A fires and B fires ten milliseconds later, the weight update will be more substantial.
- The reverse also applies. If B fires first, then A, then the synapse will weaken, and the size of the change is again inversely proportional to the delay.
TL;DR - You cannot properly backpropagate for weight updates in a graph based network since it's an asynchronous system(there are no layers with activations at fixed times), so you are trusting neurons faster than you at the task.
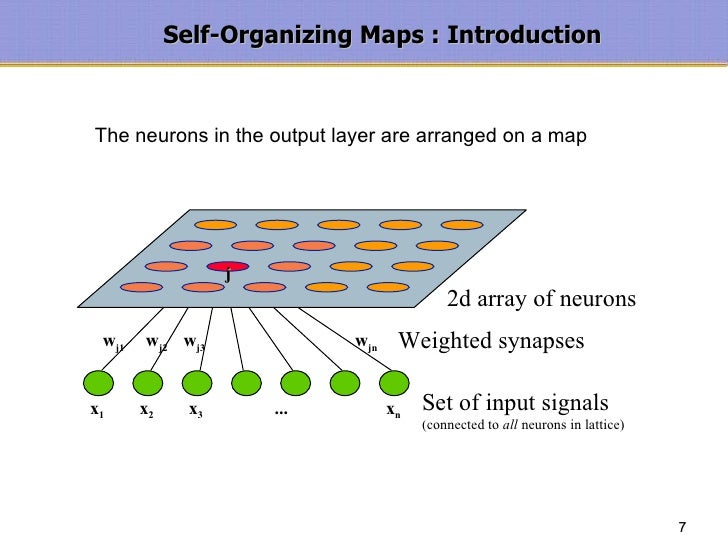
3 Self Organizing Maps

4 Synthetic Gradients https://iamtrask.github.io/2017/03/21/synthetic-gradients/
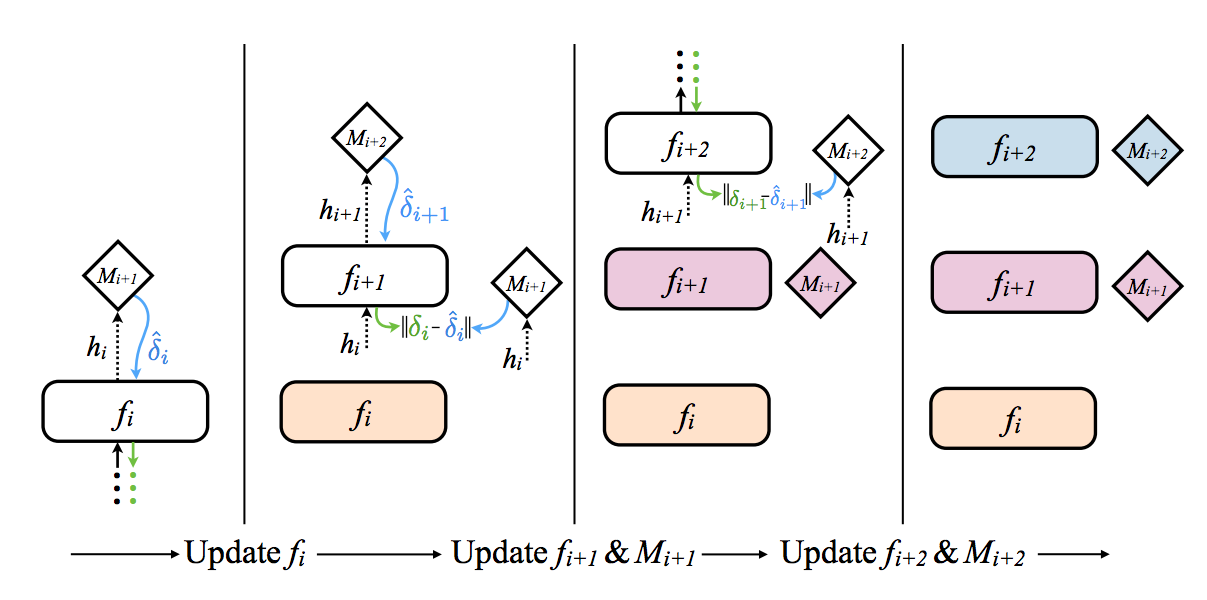
- The first layer forward propagates into the Synthetic Gradient generator (M i+1), which then returns a gradient.
- This gradient is used instead of the real gradient (which would take a full forward propagation and backpropagation to compute).
- The weights are then updated as normal, pretending that this Synthetic Gradient is the real gradient.
Synthetic Gradient genenerators are nothing other than a neural network that is trained to take the output of a layer and predict the gradient that will likely happen at that layer.
The whole point of this technique was to allow individual neural networks to train without waiting on each other to finish forward and backpropagating.
- Individual layers make a "best guess" for what they think the data will say
- then update their weights according to this guess.
- This "best guess" is called a Synthetic Gradient.
- The data is only used to help update each layer's "guesser" or Synthetic Gradient generator.
- This allows for (most of the time), individual layers to learn in isolation, which increases the speed of training.
5 Evolutionary Strategies (https://blog.openai.com/evolution-strategies/)
- Create a random, initial brain for the bird (this is the neural network, with 300 neurons in our case)
- At every epoch, create a batch of modifications to the bird’s brain (also called “mutations”)
- Play the game using each modified brain and calculate the final reward
- Update the brain by pushing it towards the mutated brains, proportionate to their relative success in the batch (the more reward a brain has been able to collect during a game, the more it contributes to the update)
- Repeat steps 2-4 until a local maximum for rewards is reached.
Code:
https://gist.github.com/karpathy/77fbb6a8dac5395f1b73e7a89300318d
- Mutation, selection, crossover via a fitness function
- ES only requires the forward pass of the policy and does not require backpropagation (or value function estimation), which makes the code shorter and between 2-3 times faster in practice.
- RL is a “guess and check” on actions, while ES is a “guess and check” on parameters.
6 Moar Reinforcement Learning

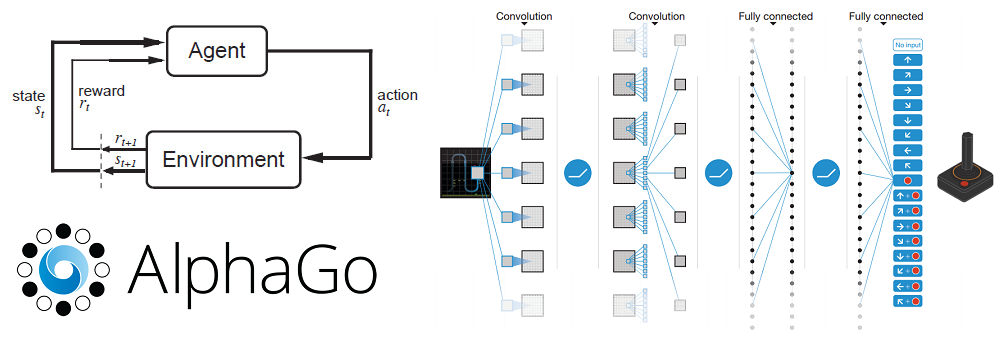
7 Better hardware.
- neuromorphic chips
- TPUs
-
Wiring up transistors in parallel like the brain!
 alt text
alt text.
My Conclusion? I agree with Andrej Karpathy
Let's create multi-agent simulated enviroments that heavily rely on reinforcement learning + evolutionary strategies


It's comes down to the exploration-exploitation trade-off. You need exploitation to refine deep learning techniques but without exploration (other technqiues) you will never get the paradigm shift we need to go beyond classifying cat pictures and beating humans in artificial games
