昨天在github上闲逛,发现了一个神器tpot。其操作简单,只需要简单几行代码就可以从原始数据集上生成机器学习代码,它会自动帮你生成整个算法代码,好激动啊有木有!。
TPOT github:https://github.com/rhiever/tpot
TPOT 官方文档:http://rhiever.github.io/tpot/
TPOT介绍
TPOT是Python编写的,使用遗传算法帮你对机器学习和数据挖掘问题进行特征选择和算法模型选择的工具。只要你写几行简单的算法就可以得到不错的结果,神器啊有木有!
众所周知,一个机器学习问题或者数据挖掘问题整体上有如下几个处理步骤:从数据清洗、特征选取、特征重建、特征选择、算法模型算法和算法参数优化,以及最后的交叉验证。整个步骤异常繁琐,但使用TPOT可以轻松解决特征提取和算法模型选择的问题,如下图阴影部分所示。

从下图对MNIST数据集进行处理的流程可以看到,TPOT可以轻松取得98.4%的结果,这个结果还是很不错的(在传统方法中,TPOT暂时没有添加任何神经网络算法,如CNN)。最最重要的是TPOT还可以将整个的处理流程输出为Python代码,好激动啊有木有!Talk is simple,show you the code。
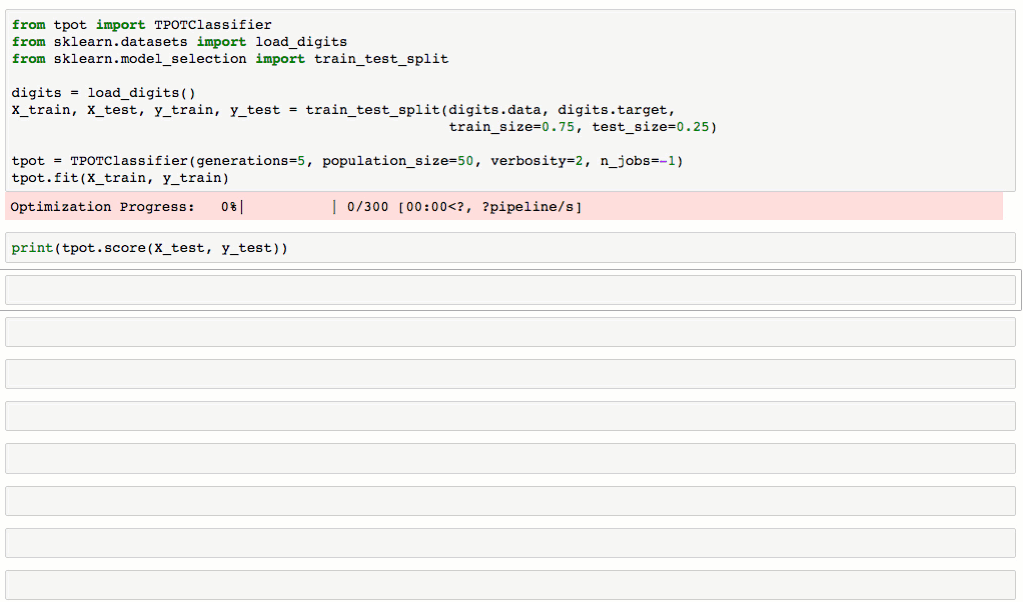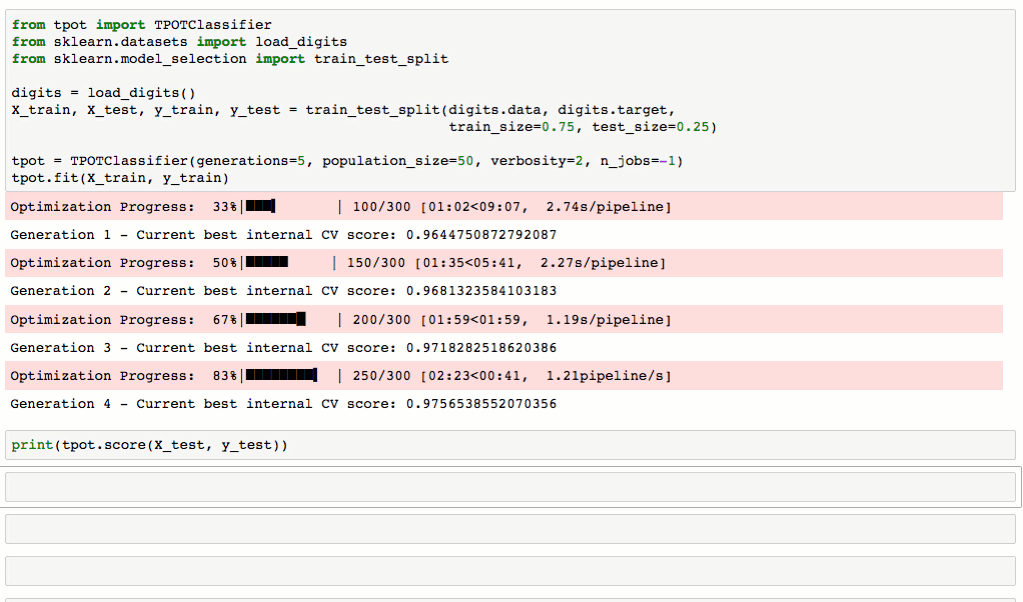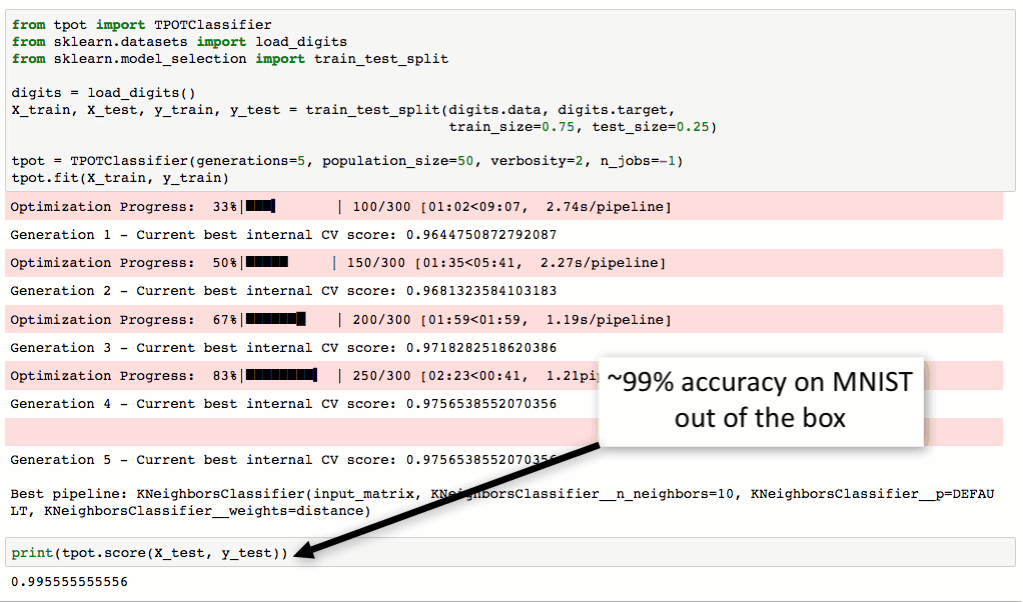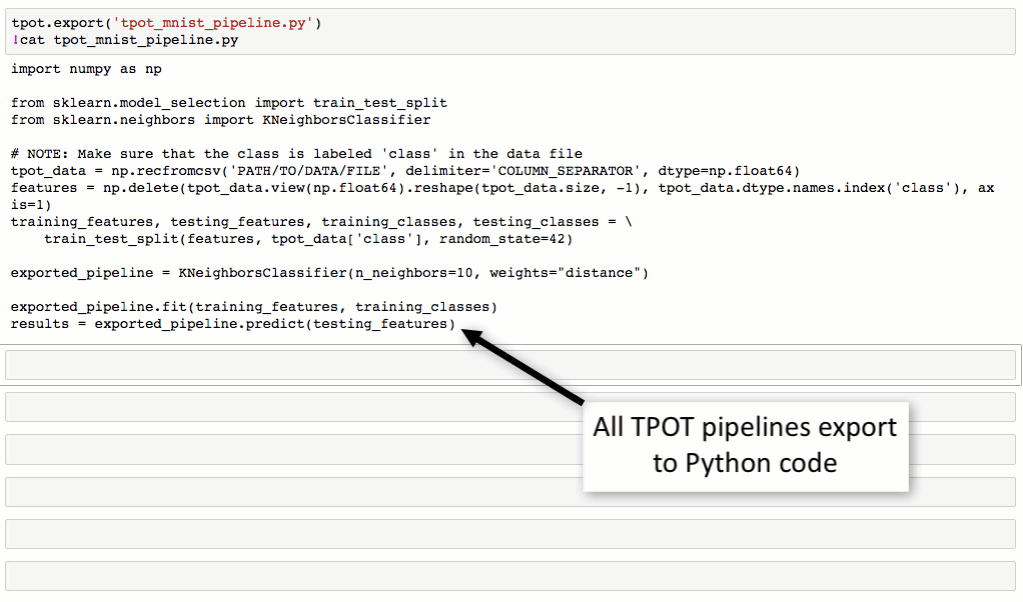
TPOT安装
TPOT是运行在Python环境下的,所以你首先需要按照相应的Python库:
- NumPy
- SciPy
- scikit-learn
- DEAP
- update_checker
- tqdm
此外TPOT还支持xgboost模型,所以你可以自行安装xgboost。
pip install xgboost
最后安装
pip install tpot
TPOT安装可以参考官方文档,也可以直接到github项目页面提交issue。
TPOT例子
1.IRIS
TPOT使用起来很简单:首先载入数据,声明TPOTClassifier,fit,最后export代码。
from tpot import TPOTClassifier
from sklearn.datasets import load_iris
from sklearn.cross_validation import train_test_split
import numpy as np
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data.astype(np.float64),
iris.target.astype(np.float64), train_size=0.75, test_size=0.25)
tpot = TPOTClassifier(generations=5, population_size=20, verbosity=2)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_iris_pipeline.py')
生成的tpot_iris_pipeline.py是这样的:
import numpy as np
from sklearn.cross_validation import train_test_split
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline, make_union
from sklearn.preprocessing import FunctionTransformer, PolynomialFeatures
tpot_data = np.recfromcsv('PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64)
features = np.delete(tpot_data.view(np.float64).reshape(tpot_data.size, -1), tpot_data.dtype.names.index('class'), axis=1)
training_features, testing_features, training_classes, testing_classes = \
train_test_split(features, tpot_data['class'], random_state=42)
exported_pipeline = make_pipeline(
PolynomialFeatures(degree=2, include_bias=False, interaction_only=False),
LogisticRegression(C=0.9, dual=False, penalty="l2")
)
exported_pipeline.fit(training_features, training_classes)
results = exported_pipeline.predict(testing_features)
2.Titanic Kaggle
由于TPOT并不包含数据清洗的功能,所以需要人工进行数据清洗,整个例子代码,最后生成的代码如下:
import numpy as np
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.ensemble import AdaBoostClassifier
from sklearn.preprocessing import PolynomialFeatures
# NOTE: Make sure that the class is labeled 'class' in the data file
tpot_data = pd.read_csv('PATH/TO/DATA/FILE', delimiter='COLUMN_SEPARATOR')
training_indices, testing_indices = train_test_split(tpot_data.index, stratify = tpot_data['class'].values, train_size=0.75, test_size=0.25)
result1 = tpot_data.copy()
# Use Scikit-learn's PolynomialFeatures to construct new features from the existing feature set
training_features = result1.loc[training_indices].drop('class', axis=1)
if len(training_features.columns.values) > 0 and len(training_features.columns.values) <= 700:
# The feature constructor must be fit on only the training data
poly = PolynomialFeatures(degree=2, include_bias=False)
poly.fit(training_features.values.astype(np.float64))
constructed_features = poly.transform(result1.drop('class', axis=1).values.astype(np.float64))
result1 = pd.DataFrame(data=constructed_features)
result1['class'] = result1['class'].values
else:
result1 = result1.copy()
result2 = result1.copy()
# Perform classification with an Ada Boost classifier
adab2 = AdaBoostClassifier(learning_rate=0.15, n_estimators=500, random_state=42)
adab2.fit(result2.loc[training_indices].drop('class', axis=1).values, result2.loc[training_indices, 'class'].values)
result2['adab2-classification'] = adab2.predict(result2.drop('class', axis=1).values)
TPOT Notes
- TPOTClassifier()
TPOT最核心的就是整个函数,在使用TPOT的时候,一定要弄清楚TPOTClassifier()函数中的重要参数。
-
generation:遗传算法进化次数,可理解为迭代次数 -
population_size:每次进化中种群大小 -
num_cv_folds:交叉验证 -
scoring:也就是损失函数
generation和population_size共同决定TPOT的复杂度,还有其他参数可以在官方文档中找到。
2.TPOT速度
TPOT在处理小规模数据非常快,结果很给力。但处理大规模的数据问题,速度非常慢,很慢。所以在做数据挖掘问题,可以尝试在数据清洗之后,抽样小部分数据跑一下TPOT,最初能得到一个还不错的算法。
