数据结构与对象
Redis的底层数据结构,了解Redis的底层数据结构有助于我们更好的运用Redis。
SDS
Redis在实现上使用了,自定义的SDS(simple dynamic string),来代替C语言传统的字符串表示方式。
- free 属性的值为 0 , 表示这个 SDS 没有分配任何未使用空间。
- len 属性的值为 5 , 表示这个 SDS 保存了一个五字节长的字符串。
- buf 属性是一个 char 类型的数组, 数组的前五个字节分别保存了 'R' 、 'e' 、 'd' 、 'i' 、 's' 五个字符, 而最后一个字节则保存了空字符 '\0' 。

SDS对比C语言传统的字符串有以下优点:
在常数时间复杂度获取字符串长度
因为在SDS结构中已经保存了字符串的长度信息,并且在修改字符串时,也会对其进行相应的修改,所以获取字符串长度,无需遍历整个字符串。-
杜绝缓存区溢出
在C字符串中如果你要对一个字符串进行扩展的话,就必须预先计算空间,如果空间不足久,就需要再申请一些内存空间。但要是忘记了预先分配空间的话,就会参数缓存区溢出。而使用SDS的API会自动的帮你计算并分配空间,从而杜绝了缓存区溢出的可能。
减少内存分配次数
相比于C字符串不记录长度信息,导致每次修改都需要进行内存重新分配(分配内存是一个相对耗时的系统调用) SDS就要灵活的多了,SDS的API通过 空间预先分配 和 惰性空间释放 这两个方式去减少空间的重新分配,其中空间预先分配 是指当第一次对SDS字符串进行修改时,SDS不止分配足够的空间,而且会根据分配策略,多分配一些空间以备下次使用。惰性空间释放就是在缩短SDS字符串时仅仅删除字符内容,并不回收剩余的内存空间。二进制安全
SDS 的 API 都是二进制安全的(binary-safe): 所有 SDS API 都会以处理二进制的方式来处理 SDS 存放在 buf 数组里的数据, 程序不会对其中的数据做任何限制、过滤、或者假设 —— 数据在写入时是什么样的, 它被读取时就是什么样。


链表
链表是Redis的列表键的底层实现之一。

可以由上图结构看出,redis的链表底层是双端链表,并且由一个list结构表示,list结构为链表提供了表头指针 head 、表尾指针 tail , 以及链表长度计数器 len , 而 dup 、 free 和 match 成员则是用于实现多态链表所需的类型特定函数。

总结:
redis 链表是一个无换的双端链表,并且通过list结构的表头和表尾指针,达到O(1)复杂度的首尾节点获取,利用len属性进行O(1)复杂度的链表长度获取。
字典
字典在Redis中被用于实现数据库本身和哈希键,当我们使用HSET,HGET的时候底层就是使用redis的字典实现。
实现
Redis的底层使用字典作为哈希表的实现,一个哈希表有多个哈希节点,每个节点保存一个键值对。

哈希表中,table属性是一个数组,size属性记录了哈希表的大小,也就是table数组的大小,而used属性则记录了哈希表目前已有节点(键值对)的数量。sizemask 属性的值总是等于 size - 1 , 这个属性和哈希值一起决定一个键应该被放到 table 数组的哪个索引上面。
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
哈希节点结构,是由键指针(key),联合体类型的值(v),和指向下一个哈希节点的指针next组成,其中值可以64位有,无符号数,或是任意指针类型。next是为了实现链地址解决冲突而存在的。

- type 属性是一个指向 dictType 结构的指针, 每个 dictType 结构保存了一簇用于操作特定类型键值对的函数, Redis 会为用途不同的字典设置不同的类型特定函数。
而 - privdata 属性则保存了需要传给那些类型特定函数的可选参数。
- ht属性是一个只有两个元素的哈希表类型的数组,h[0]用于正在的数据,h[-1]用于Rehash的中间过渡。
- rehashidx属性,用于表示哈希表rehash的状态
哈希算法
Redis使用MurmurHash2算法来计算哈希值,每次有新的键值对要被添加到字典中,redis会先使用 MurmurHash2哈希函数来计算出哈希值,然后在用哈希值与哈希表结构中的sizemask进行与运算,最后就会得出键值对要存储的下标位置了。
解决冲突
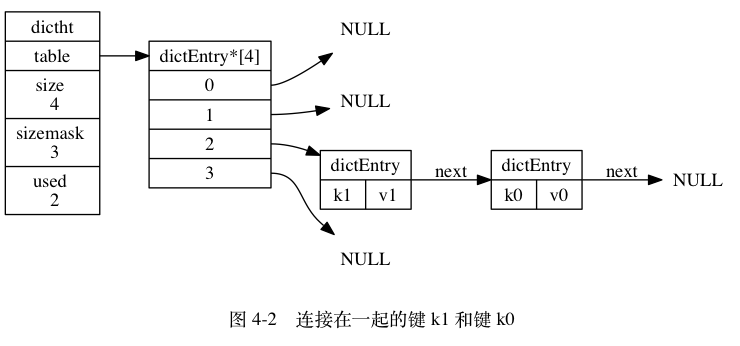
如上面的流程,当两个键值对最后计算出来的下标是一样的,那么Redis就会使用链地址法来解决冲突。

这里就使用到哈希节点中预留的next属性,指向下一个节点,后一个添加的节点,会被添加到头部,这样添加节点的复杂度就是O(1)了。
rehash
rehash(重新散列),被用于保证字典的负载因子在一个平衡的范围内(1-5之间),也就是需要根据哈希表的大小进行相应的扩展和收缩。
rehash的过程:
- 给字典ht[1]分配空间,分配空间大小的公式是$2^n$,其中在扩展时: n=ht[0].used * 2, 在收缩时: n=ht[0].used。
- 设置字典的rehashidx为0,开始rehash。
- 每当对字典执行添加、删除、查找或者更新操作时,将rehashidx作为下标,对应在h[0]的节点取出,然后重新计算哈希值和下标,保存的对应的h[1]的位置上,最后自增字典的rehasidx属性。
- 当h[0]中的所有节点都被rehash到h[1]后,释放h[0]的空间,将h[1]设置成h[0],再为h[1]设置一个空白哈希表,并且将字典的rehashidx设置为-1。
在rehash期间,如果添加键值对到字典的操作,都会被直接存储在h[1]中,而查找的时候会先从h[0]找,然后再到h[1],这样就保证了h[0]的元素只减无增。
当以下条件中的任意一个被满足时, 程序会自动开始对哈希表执行扩展操作:
服务器目前没有在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于 1
服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于 5
