# HIVE3 深度剖析 (上篇)
大家好,我是明哥!
HIVE3 相对于HIVE2,差异还是很大的,为方便大家了解这些差异点以更有效地使用HIVE,接下来我会通过几篇文章,重点剖析下这些差异点。
整个系列分为上下两篇文章,涵盖以下章节:
1. 从 HIVE 架构的演进看 HIVE 的发展趋势
2. 盘点下 HIVE3.X 和 HIVE2.X 的那些重大差异点
3. HIVE3.X 的 ORC 事务表详解
4. HIVE3.X 的 LEGACY 传统模式详解
5. 周边生态如 SPARK/DATAX 如何对接HIVE 3x
6. 大数据应用对接 HIVE3.x 的几点建议
本片文章是上篇,包含前三个章节,希望大家喜欢。
## 1. 从 HIVE 架构的演进看 HIVE 的发展趋势
***早期的 HIVE,按照 METASTORE SERVICE/DB 所处的位置,经常会提到三种模式:内嵌模式,本地模式,远程模式:***
- 内嵌模式:客户端和服务端还有底层存储元数据的数据库是同一个进程(使用的是derby这种jvm嵌入式数据库),是一体的(即不区分客户端和服务端);
- 本地模式:在内嵌模式的基础上,把存储元数据的数据库拆分了出来,但客户端和服务端还是同一个进程,是一体的(即不区分客户端和服务端);
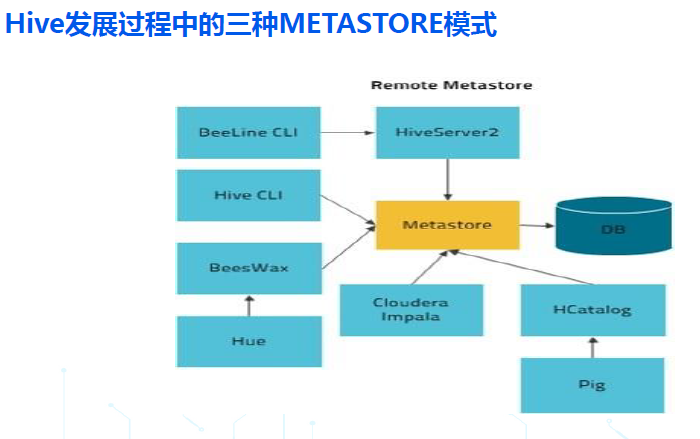
- 远程模式:在本地模式的基础上,把元数据服务 hms 也拆分出来作为一个单独的进程,有了真正意义上的客户端和服务端,从 HIVE1.X 开始,所有生产环境推荐使用的都是 remote metastore 模式;
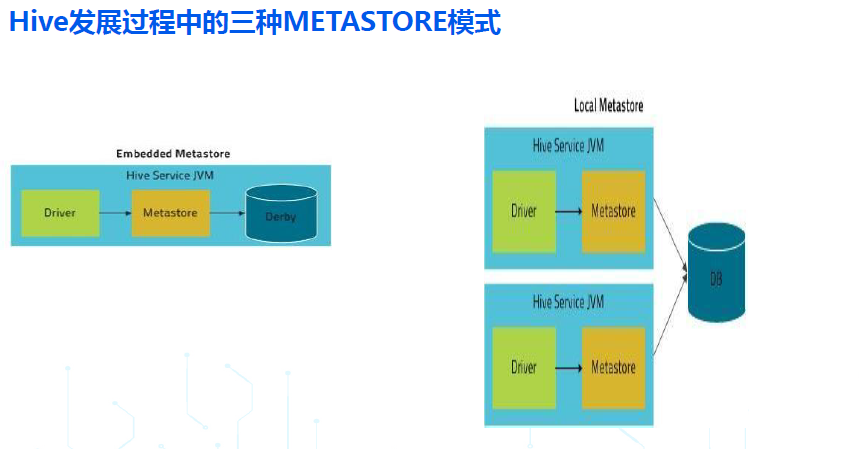
***我们重点看下从 HIVE1.X 开始,生产环境使用的 远程模式:***
- 远程模式,在服务端,包括一个或多个查询引擎 HiveServer2 和一个元数据引擎 HMS (Hive Metastore Service);
- 远程模式,从客户端使用方式来看,在 hive1.x 和 hive2.x 中又可以进一步分为两种方式:hive cli 的胖客户端模式,和 beeline 的瘦客户端模式;
- Hive cli 的胖客户端模式,客户端承载了 hiveserver2 的查询引擎角色,只需要访问服务端的元数据服务 hms 即可;
- Beeline 的瘦客户端模式,客户端需要访问服务端的 hiveserver2 ,并通过 hiveserver2 访问底层的 hms;
- 从 hive3.x 开始,hive 不再支持 cli 胖客户端模式, 仅仅支持 beeline 瘦客户端模式;
- 目前HIVE远程模式,完整的架构图如下:
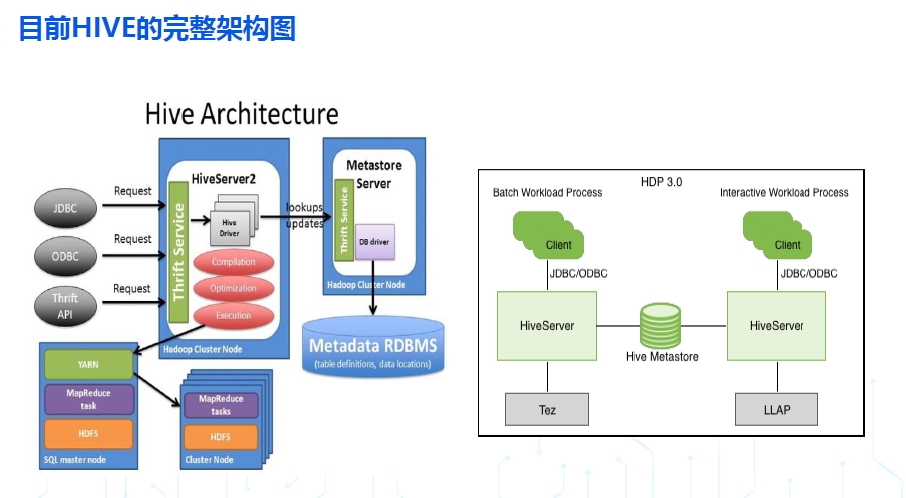
***从上述HIVE 架构的演进,可以看到 HIVE 如下发展趋势:***
- HIVE 将客户端与服务端分离,并在服务端进一步按照功能拆分出 hiveserver2 和 hms 两个服务,就可以应对多个客户端的并发访问,也能够适配大数据生态的其它计算引擎,如 spark/impala/presto/flink;
- 为了提高数据质量,也为了提高数据查询和分析的效率 Hive 社区还孵化出了列式存储 orc ,目前 Orc 已经是 apache 顶级项目;
- HIVE 进一步补强优化了 hiveserver2 服务端,通过 ORC 事务表提供了对增删改查的完善的 ACID 语义的支持,也通过 LLAP 加强了互动查询的效率,还通过 streaming 增强了实时流处理能力;
- 综上所述, HIVE 已经从早期一个简单的存储引擎之上的 SQL 解析层(单纯的 JAR 而没有服务),逐渐迭代优化,补齐功能短板,越来越像传统的关系型数据库,成为一个完善的数据仓库解决方案了!
- 注意 1: HIVE 是针对数据仓库的 OLAP 场景,不是针对事务交易的 OLTP 场景,不能当做 OLTP 数据库来 使 用!
- 注意 2:虽然 HIVE 做了大量性能方面的优化,但由于它是存算分离的架构,在执行时也需要向 YARN 等资源管理器动态申请资源,所以其查询性能一般比 OLAP 数据库还是要差些的,比如 GP/DORIS/CK 等。
***Cloudera 官方建议,为最有效地使用HIVE3,需要注意一下几点:***

## 2. 盘点下 HIVE3.X 和 HIVE2.X 的那些重大差异点
***HIVE3.X不再支持以下特性:***
- Hive cli: HIVE3.X 不再支持 胖客户端 Hive CLI, 仅支持瘦客户端 beeline;
- Hive on mr: HIVE3.X 底层执行引擎不再支持 hive on mr , CDP 中也不再支持 hive on spark 仅支持 hiveon tez (Hive on Tez 提供更好的 ETL 性能);
- Hive index: 通过 HIVE 18448 在 hive 3.x 中彻底移除了对 Index 的支持;(orc/parquet 列式文件存储格式本身提供了对 index 和 bloom filter 的支持, 相关参数 hive.optimize.index.filter 默认为 true; hive2.3.0 也增加了对物化视图 materialzed views 的 automatic rewriting 的支持,这些功能很好地替代了Index);
***在 DDL 执行效果上,HIVE3.X和HIVE2.X有以下差异:***
- HIVE3.X CREATE TABLE,不指定格式时,默认 为 ORC 格式,之前版本默认为 text 格式;
- HIVE3.X CREATE TABLE,不指定是否为事务表时,默认为 ORC 事务内表,之前版本默认为 ORC 非事务内表;
- Hive3.x 的 ORC 事务内表,支持高效 的 insert/update/delete/merge, 且不再需要进行分桶;
- Hive3.x 的 ORC 事务内 表,分为 full acid 事务内表,和 Insert only 事务内
表: TBLPROPERTIES(‘transactional’=‘true',transactional_properties='insert_only’或'default');
- HIVE3.X 增加了新的语法 CREATE MANAGED TABLE xyz(col1 type,...) type,...),来显示创建 managed table;
- HIVE3.X 中,external 外表有两种类型:external purge table 和 external non purge table: TBLPROPERTIES ('EXTERNAL'='TRUE',external.table.purge’=’TRUE;
- Hive3.x 中,内表和外表的默认存储路径,分别由参数 hive.metastore.warehouse.dir 和hive.metastore.warehouse.external.dir 控制,在 cdp 中默认值分别为 /warehouse/ tablespace/managed/hive 和 /warehouse/ tablespace/external/hive;
- HIVE3.X 中,内表和外表的存储路径,分别可以在 DATABASE” 级别和 “TABLE” 级别通过 location 参数来修改;
- HIVE3.X CREATE TABLE 创建 managed table 时,推荐不在 TABLE 级别指定 location ,此时会使用 hive.metastore.warehouse.dir 指定的默认值或 DATABASE 级别覆盖的值;(如果指定路径,路劲的值必须是 managed
warehouse root dir 或 database 的 managedLocationUrI 之下的路径);
- HIVE3.X CREATE TABLE 创建 external table 时, 也推荐不指定 location,此时会使用参数 hive.metastore.warehouse.external.dir 指定的默认值 (也可以在 TABLE 级别来指定);
- HIVE3.X Drop external table 时,会不会删除表底层实际的数据,取决于参数 external.table.purge;
- HIVE3.X truncate table,只能对内部 表,或‘external.table.purge’=’TRUE' 的外部表,才能被 truncate ;(否则会报错);

***HIVE3.X相比HIVE2.X,重大参数变化如下:***
- hive.default.fileformat.managed:升级前None,升级后ORC;
- hive.metastore.disallow.incompatible.col.type.changes:控制是否允许更改不兼容的列类型,比如将 STRING 列更改为 INT 列;升级前FALSE,升级后TRUE;
- hive.metastore.warehouse.dir:升级前 /user/hive/warehouse,升级后/tablespace /managed/hive;
- hive.server2.enable.doAs:升级前TRUE (in case of unsecure cluster only),升级后FALSE;
- hive.txn.manager:升级前org.apache.hadoop.hive.ql.lockmgr.DummyTxnManager ,升级后 org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
- hive.execution.engine:升级前mr,升级后tez;
- hive.cbo.enable: 升级前 FALSE,升级后 TRUE;
- hive.auto.convert.sortmerge.join/hive.auto.convert.sortmerge.join.reduce.side: 升级前: FALSE in the old CDH,TRUE in the old HDP; 升级后TRUE;
- hive.auto.convert.sortmerge.join.to.mapjoin: 升级前FALSE,升级后TRUE;
- hive.exec.dynamic.partition.mode:升级前strict,升级后nonstrict;
- hive.exec.max.dynamic.partitions:升级前1000,升级后5000;
- hive.exec.max.dynamic.partitions.pernode:升级前100,升级后2000;
## 3. HIVE3.X 的 ORC 事务表详解
***如上文所说,HIVE的一个最主要的发展趋势,就是已经从早期一个简单的存储引擎之上的SQL解析层(单纯的JAR而没有服务),逐渐迭代优化,补齐功能短板,越来越像传统的关系型数据库,成为一个完善的数据仓库解决方案了!这其中最显眼的功能点,就是 HIVE 推出的 ORC ACID 事务表,通过该特性,HIVE可以向其它流行的数据湖框架 deltaLake/hudi/iceberg 一样,通过 ACID 事务特性,提供对并发读写的支持,提供记录级别的增删改查。***
- 在默认情况 下 HIVE3.X CREATE TABLE 语句会在 Hive Metastore 中创建一个 ORC 格式的 Full ACID v2 事务内表;
- Hive 严格控制对 ORC 事务表的访问,并定期在后台对表执行压缩 compaction 操作 当然, Spark 和其他客户端访问 Hive ORC 事务表的方式也相应地需要作出变化);
- 与 Non ACID 表相比, Hive Full ACID v2 (事务内表)提供了更好的批量性能、安全保障和用户体验
- Full ACID v2 Hive 表有以下四个特点:
- 支持 Insert/Update/Delete/Merge 操作;
- ETL 性能与 Non ACID 表一样好;
- 无需进行分桶操作;
- 与 S3 等云端对象存储完全兼容;
- 与 Non ACID 表相比, Hive Full ACID v2(事务内表 )提供了 row 级别的 ACID 语义,而不再仅仅是 table或 partition 级别的 ACID ,并基于此支持了以下场景:
- 提供了多任务并发读写同一个表或同一个分区的能力: one application can add rows while another reads from the same partition without interfering with each other;
- 提供了对 Streaming ingest of data 的支持:不再引起 dirty read 和 小 文件问题;(可以更好地对接 flink/kafka/flume)
- 提供了对数仓的 SCD Slowly changing dimensions 的支持:HIVE ACID 通过提供记录级别的 inserts/delete,可以完善地支持数仓星型模型的缓慢渐变维度;
- 提供了记录级别的数据修复 data restatement 功能:HIVE ACID 通过提供记录级别的Insert/Update/Delete,支持了数据修复和删除功能;
- 提供了批量更新功能:通过 Merge 提供了批量更新功能;
***HIVE 官方文档对 ORC ACID 事务内表的实现机制,有详细的描述,建议大家翻阅下,部分要点概括如下:***
- HDFS 文件不支持原地更新,在APPEND追加写入文件时也不支持对该文件并发读取时的数据一致性;
- 为了在 HDFS 文件系统的以上特性基础上提供 ACID 语义,HIVE 对 ACID 事务表(或表分区)底层的 HDFS 目录,做了类似 deltalake/hudi/iceberg 一样的精细化管理,在该目录底层又创建了两个子目录,一个是 base 子目录,一个是 delta 子目录:
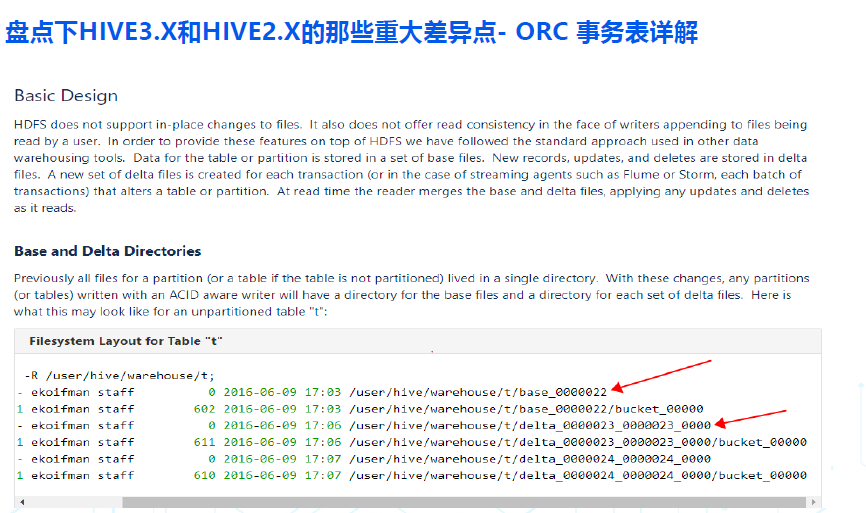
- 表或表分区的大部分数据,都以文件形式存储在 base 子目录下;
- 每次对表或表分区的增删改操作,都对应一个事务,都会创建一个对应的 delta 子目录,并将这些增量操作产生的数据,以文件形式存储在该 delta 子目录下;
- 读取表或分区数据时,会合并 base 子目录和 delta子目录下的所有文件,以呈现完整的数据;
- 在后台 hms 中有一系列 compactor 线程,会合并/压缩 base 和 delta子目录下的众多文件,以优化读取性能;
- compactor 在后台的执行,不会影响前台用户对表或分区的并发读取操作;
- compactor 分为 major 和 minor 两种类型,类似 hbase 的 compactor;

***事务表主要参数如下:***
- ORC事务表客户端相关参数:
- hive.support.concurrency:true
- hive.enforce.bucketing: true (Not required as of Hive 2.0
- hive.exec.dynamic.partition.mode: nonstrict
- hive.txn.manager:org.apache.hadoop.hive.ql.lockmgr.DbTxnManager
- ORC事务表服务端相关参数(hms):
- hive.compactor.initiator.on:true
- hive.compactor.worker.threads: a positive number on at least one instance of the Thrift metastore service
***HIVE3对事务表新增了一些命令,主要有以下这些:***
- 提供了对以下 DML 命令的支持: INSERT…VALUES, UPDATE,DELETE,merge into;
- 可以通过以下命令查看压缩任务,事务,锁等:SHOW TRANSACTIONS/COMPACTIONS/LOCKS;
- 可以通过以下命令手动触发对表的压缩:Alter table xxx compact ‘minor/ major’and wait (自动压缩之外的补充)
- MERGE INTO 是一个很方便的命令,其语法如下:
~~~java
MERGE INTO <target table> AS T USING <source expression/table> AS S
ON < boolean expression1>
WHEN MATCHED [AND < boolean expression2>] THEN UPDATE SET <set clause list>
WHEN MATCHED [AND < boolean expression3>] THEN DELETE
WHEN NOT MATCHED [AND < boolean expression4>] THEN INSERT VALUES<value list>
~~~
