背景
时至今日,C++的核心战场在于:对于性能,空间和实时性有高要求的系统。
而在这类系统上,也有其特定的约束和挑战:
在这类系统上,内存管理始终是个需要关注的问题。而通用内存管理算法,要么容易导致内存碎片,要么会导致内存浪费。而为了避免这样的问题,最好是自己定义内存管理器。
内存分配是可能失败的。为了避免这样的问题,高可靠系统的做法一般是按照系统定义的规格预先分配内存。比如,系统承诺的规格是
10000个Session,那么Session Instance相关的内存,会按照规格,在系统启动时就预先分配10000个Session Object需要的内存。其背后的原则是:如果失败,则尽早失败(fail fast);如果内存不足,就应该在未发布时,通过系统加载就可以及时发现;而不是把风险留到在业务现场运行时发生失败。对于需要大量销售的设备,成本很重要。而内存作为成本构成,也是非常宝贵的资源。另外,由于竞争对手的存在,如何在让客户付出相同的成本下,能够支撑更多的业务,始终是一个重要的指标。
对于高性能计算系统,所有的领域对象,尽管部分数据也可能会持久化,但在运行时,都会放在内存之中,与另外一些纯粹的运行时状态一起,构成了运行时领域对象的整体。而对于有高可靠性要求的系统,运行时依然会对需要持久化的状态进行持久化——那怕只是采用主备方式其实也是一种持久化——所以系统事实上是无状态的。
该如何在这类系统上应用小类,大对象的设计模式,将是本文随后讨论的内容。
委托
回到《小类,大对象》的文章里的例子,我们首先角色实现分割到了不同的类中,从而得到了四个类:
struct ConcreteChild : Child
{
// 子女角色相关接口
void getAdviceFromParent() {...}
// ...
private:
// 子女角色所需的数据成员
// ...
};
struct ConcreteParent : Parent
{
// 父母角色相关接口
void tellStory() {...}
void playGameWithChild() {...}
// ...
private:
// 父母角色所需的数据成员
// ...
};
struct ConcreteBoss : Boss
{
// 老板角色相关接口
public void assignTask() {...}
public void motivate() {...}
// ...
private:
// 老板角色所需的数据成员
// ...
};
struct ConcreteUnderling : Underling
{
// 下属角色相关接口
public void acceptTask() {...}
public void reportStatus() {...}
// ...
private:
// 下属角色所需的数据成员
// ...
};
然后,我们根据不同对象的需要对这四个对象进行组合。而首先进入我们视野的,是我们最熟悉的委托(Delegation):
struct TypeAPerson
{
// 父母角色相关接口
void tellStory()
{
parent.tellStory();
}
void playGameWithChild()
{
parent.playGameWithChild();
}
// 孩子角色相关接口
void getAdviceFromParent()
{
child.getAdviceFromParent();
}
// 下属角色相关接口
void acceptTask()
{
subordinate.acceptTask();
}
void reportStatus()
{
subordinate.reportStatus();
}
private: // 通过委托关系进行组合
ConcreteParent parent;
ConcreteChild child;
ConcreteSubordinate subordinate;
};
毫无疑问,这是令人生厌的中间人(MiddleMan)实现(参见《重构》)。
另外,TypeAPerson将自己作为一个整体展现给了所有客户;而不同客户真正需要的却是不同的角色,因而,无论从依赖范围角度,还是依赖稳定度角度,都无疑增大了系统的耦合度(参见《变化驱动:正交设计》)。
因而,按照我们最初的意图,如下的实现方式才是我们真正想要的:
struct TypeAPerson
{
Parent& getParent()
{
return parent;
}
Child& getChild()
{
return child;
}
Subordinate& getSubordinate()
{
return subordinate;
}
private:
// 通过委托关系进行组合
ConcreteParent parent;
ConcreteChild child;
ConcreteSubordinate subordinate;
};
TypeAPerson仅仅应该聚合(组合)其所需的角色实现,其唯一的职责是当做一个角色工厂,面对不同的客户,将对象转化为不同的角色:
// client of Parent
void f(Parent& parent)
{
// ...
parent.tellStory();
// ...
parent.playGameWithChild();
// ...
}
// ...
// client of Subordinate
void g(Subordinate& subordinate)
{
// ...
subordinate.acceptTask();
// ...
subordinate.reportStatus();
// ...
}
// object
TypeAPerson person1;
// cast to Parent role
f(person1.getParent());
// cast to Subordinate role
g(person1.getSubordinate());
从这段示例代码,我们可以清晰的看出,f和g是完全不依赖TypeAPerson的,而只依赖自己真正需要依赖的角色。因而,如果TypeBPerson也实现了相关角色的话,它也可以和f,g配合。如下:
struct TypeBPerson
{
Parent& getParent()
{
return parent;
}
Subordinate& getSubordinate()
{
return subordinate;
}
private:
// 通过委托关系进行组合
ConcreteParent1 parent; // 与TypeAPerson的Parent实现不同
ConcreteSubordinate subordinate;
};
// object
TypeBPerson person2;
// cast to Parent role
f(person2.getParent());
// cast to Subordinate role
g(person2.getSubordinate());
通过这个例子,我们可以清晰的看出:将上帝类根据自己的上下文需要,分拆成多个角色类的好处:
- 客户代码仅仅依赖的自己所需要依赖的角色,而不关心提供角色服务的对象,这解开了客户与具体对象之间的耦合; 这不仅缩小了依赖范围,也让客户向着稳定的方向依赖;
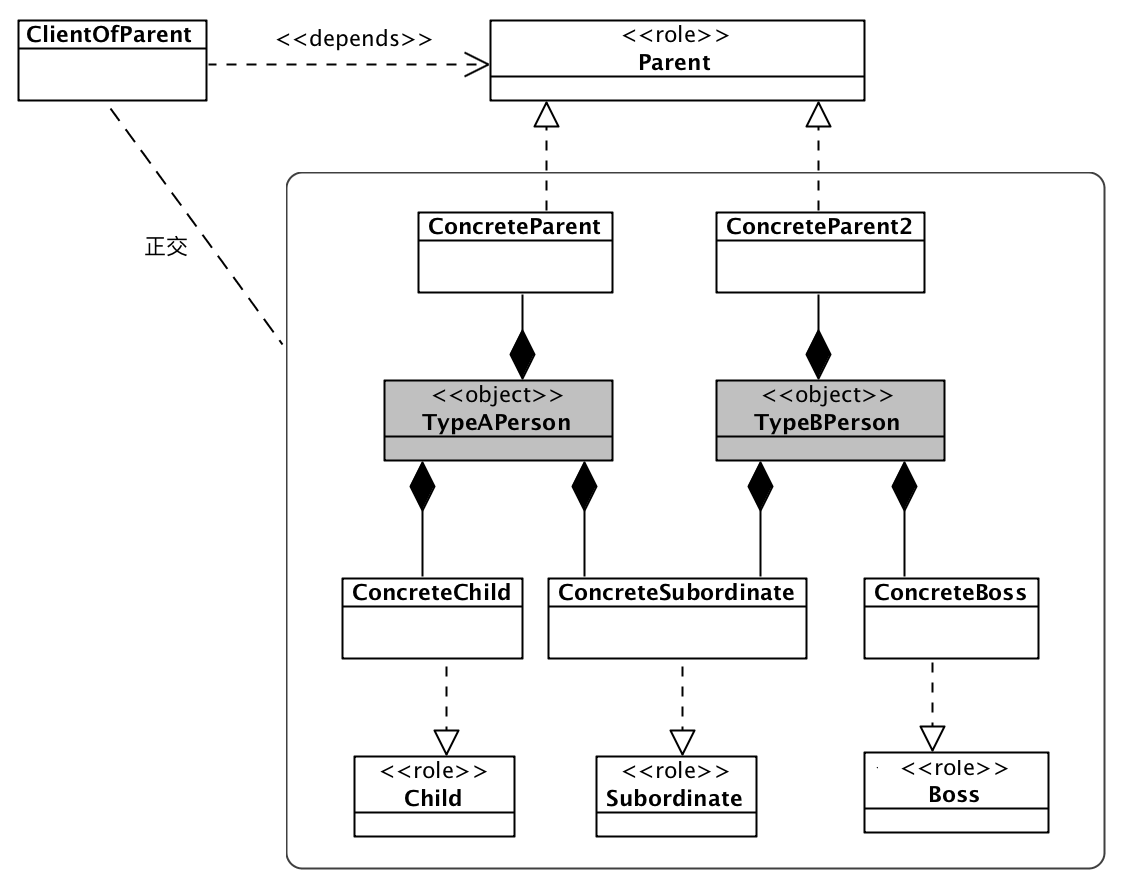
每个对象自身的不同角色实现是更加高内聚,更加单一职责。角色与角色之间的耦合也从上帝类那种缺乏封装,从而更容易导致高耦合的方式中解脱出来。让各个角色代码都更加正交;
不同对象间的角色,如果实现是相同的,可以直接复用,这让代码复用更加容易;
对象对多重职责的实现更加简单,只需要通过一个承担角色工厂职责的类来实例化对象。
Can We Do Better?
从委托的实现方式看,已经基本上达到了我们的意图。
但是,我们也注意到:我们不得不让TypeAPerson提供一组get接口,来暴露自己实现的角色。这些get接口,像Singleton的getInstance()一样。因而,上述的实现模式也是一种创建者模式。这也正是我们将其称之为角色工厂的原因。
那么,是否还有更为简便的方法来实现角色工厂的职责?
我们不难发现:TypeAPerson与它所承担的角色之间存在IS-A关系;而且,由于TypeAPerson没有任何业务逻辑代码,从而也没有改写任何一个父类(角色)的行为,因此这种IS-A关系必然是满足里氏替换原则。那我们为何不试试多重继承:
struct TypeAPerson
: ConcreteParent
, ConcreteChild
, ConcreteSubordinate
{
};
这样的方式,在组合TypeAPerson时,明显比委托的实现方式更为简洁。
而在调用侧使用角色时,由于IS-A这种关系的存在,其角色转换也可以自动完成,从而也更为简洁:
// object
TypeAPerson person1;
// naturally cast to Parent role.
f(person1);
// naturally cast to Subordinate role.
g(person1);
当然,多重继承的实现方式,相对于委托方式,还是存在一点缺点:你无法阻止ParentAPerson可以向ConcreteParent这个更具体的角色转化;但在委托方式下,由于ParentAPerson的具体组合的对象都作为了私有实现细节,然后通过getter这种更有弹性的函数方式,将具体的角色实现,比如ConcreteParent,转化为更抽象的角色Parent;从而具备更好的封装性。
对于这类问题,其解法有二:一则可以通过语言提供的机制进行强制约束,二则通过人为的约定。多重继承的方式,在C++里没有强制禁止向一个代表某种具体实现的父类进行转换的手段,但站在便利性的角度,我们更倾向于选择通过人为的约定。毕竟我们清晰的知道我们的设计意图是什么。
角色依赖
在之前的例子中,为了突出要点,给出的各个角色的实现都是孤立的。但在实际项目中,角色之间存在依赖关系,也是一种常见的现象。
比如,在我们的例子中,TypeBPerson的下属角色的某个实现,需要调用上司角色所提供的服务。如下图所示:
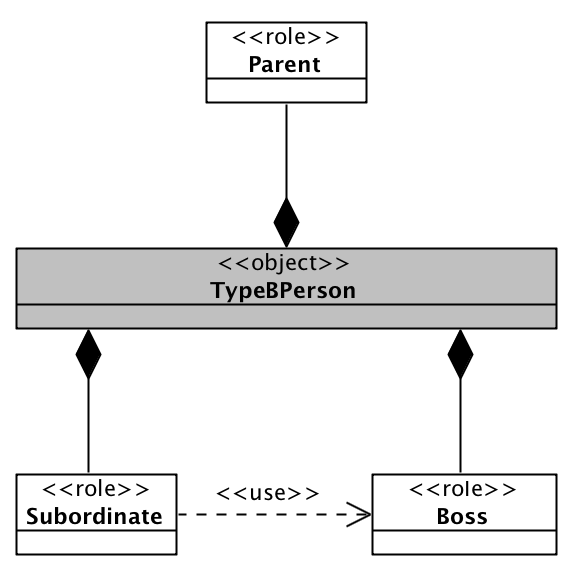
这个难不倒我们,我们可以让下属角色持有一个指向上司角色的指针,然后在构造下属角色时进行依赖注入。如下是一种委托方式的实现:
struct ConcreteUnderling : Underling
{
ConcreteUnderling(Boss& boss)
: boss(boss)
{}
void acceptTask()
{
boss.assignTask();
// ...
}
// ...
private:
Boss& boss; // 引用会消耗一个指针宽度的内存
};
struct TypeBPerson
{
TypeBPerson()
: underling(boss)
{}
Boss& getBoss()
{
return boss;
}
Underling& getUnderling()
{
return underling;
}
private:
ConcreteBoss boss; // 确保 Boss 在 Underling 之前
ConcreteUnderling underling;
// ...
};
这样的实现,存在如下问题:
首先,需要确保不同角色的构造顺序,一旦角色Underling依赖了角色Boss,那么,在TypeBPerson里,就最好确保boss定义在Underling之前,以免由于构造顺序所造成的调用问题。
其次,一旦一个角色引用了另外一个角色,那就需要通过引用进行依赖注入。这会增加由于引用所消耗的内存,对象间的关联越多,那么指针消耗的空间就越大。
尤其是当我们追求高内聚,低耦合的设计时,伴随而生的是很多很小单一职责的类,类与类之间会通过引用进行职责委托。这对于那些内存不是一个重要问题的系统而言,或许并不重要。在内存珍贵的嵌入式设备上,这会是一个问题。
而这个问题,也会反过来约束C++程序员即便知道高内聚,低耦合是正确的,在内存约束面前,也只能采取更糟糕的实现方式。
How About Inheritance?
对于角色关联所导致的问题,换成多重继承也不会让情况变得更好:
struct TypeBPerson
: ConcreteBoss // 确保 Boss 在 Underling 之前
, ConcreteUnderling
,
{
TypeBPerson()
: ConcreteUnderling(*this)
{}
};
这两种实现,差别在于从成员变量便为继承,而不变的是:都要注意声明顺序,都会造成由引用带来的内存消耗。
工厂方法
幸运的是,相对于委托,通过继承,我们可以拥有更多的武器。
对外部的依赖,在继承体系下,我们可以通过著名的工厂方法来引入,而不是通过经典的构造时依赖注入方式。比如:
struct ConcreteUnderling : Underling
{
void acceptTask()
{
getBoss().assignTask();
// ...
}
private:
// 通过工厂方法引入依赖
virtual Boss& getBoss() = 0;
};
struct TypeBPerson : ConcreteBoss
, ConcreteUnderling
{
Boss& getBoss() override
{
return *this;
}
};
通过这样的方法,首先解决了角色构造顺序的问题。因为,一个角色对于另外一个角色的引用,只有到整个对象构造结束后,运行时才会进行获取。当然你需要避免任何在构造函数里对于其它角色的引用,而事实上,根据多个项目的实践,这种构造时引用关系都可以合理的避免。
内存优势
但这个例子还不能彰显工厂方法的内存优势。让我们换个例子:
struct Role1
{
Role1
( Role2& role2
, Role3& role3
, Role4& role4)
: role2(role2)
, role3(role3)
, role4(role4)
{}
// methods
private:
Role2& role2;
Role3& role3;
Role4& role4;
};
struct Object : Role1
, Role2
, Role3
, Role4
{
Object()
: Role1(*this, *this, *this)
{}
};
这种通过直接引用的方式,让Role1需要消耗三个引用的空间开销。
现在将其换成基于工厂方法的实现:
struct Role1
{
// methods
private:
virtual Role2& getRole2() = 0;
virtual Role3& getRole3() = 0;
virtual Role4& getRole4() = 0;
};
struct Object : Role1
, Role2
, Role3
, Role4
{
Role2& getRole2() override { return *this; }
Role3& getRole3() override { return *this; }
Role4& getRole4() override { return *this; }
};
现在我们可以清晰的看出,对于Role1,无论其对外部有多少个角色引用,都只需要耗费一个指针内存的开销,那就是虚表指针(vptr)。如果Role1本来就存在其它virtual函数,那么这些外部引用,无论存在多少,都没有增加任何额外的空间开销。
简化工厂管理成本
我们知道,按照高内聚,低耦合的实现方式,会导致一堆小类。如果不用小类,大对象的方式,而是让一个个小类可独立实例化。那么这些小类之间如果存在引用关系,一则需要更多的内存消耗,二则,你还不得不需要写很多工厂来对这些小对象进行构造和关联。比如:
struct A
{
A(B* b, C* c) : b(b), c(c) {}
// ...
private:
B* b;
C* c;
};
struct AFactory
{
static A* create()
{
B* b = ... // get b;
C* c = ... // get c;
return new A(b, c);
}
}
当对象种类很多时,这样的承担工厂职责的代码就会很多。而这类的代码是极其无趣而令人厌烦的。
当然对于其它应用语言,往往会提供一个框架,来管理这类工厂职责。比如Java的Spring。程序员需要做的是:将对象,及对象间的关联关系,通过xml配置文件进行描述,Spring框架会根据这个配置文件来履行工厂职责。
可是,这样的方法在嵌入式C++下不是一个可行的途径,程序员们还是不得不亲自去实现。
而在小类,大对象的实现模式下,固定模式的工厂方法就完成了这些,程序员不会比Java下用XML进行配置,需要付出的努力更多。
struct Object
: Role1
, Role2
, Role3
, Role4
{
// 这些工厂方法即属于工厂职责的实现
Role2& getRole2() override { return *this; }
Role3& getRole3() override { return *this; }
Role4& getRole4() override { return *this; }
};
Once For All
更妙的是,在一个对象上,无论一个角色被多少其它角色引用,最后都只需要实现一次。比如:
struct Role1
{
// ...
private:
virtual Role4& getRole4() = 0;
};
struct Role2
{
// ...
private:
virtual Role4& getRole4() = 0;
};
struct Role3
{
// ...
private:
virtual Role4& getRole4() = 0;
};
struct Object
: Role1
, Role2
, Role3
, Role4
{
private:
// 只实现一次,就满足了Role1,Role2,Role3的需要。
Role4& getRole4() override { return *this; }
};
即便对于一个来自于外部的角色,也是如此:
struct Object
: Role1
, Role2
, Role3
{
// Role4是External Role,因而需要在对象构造时注入
Object(Role4& role4) : role4(role4) {}
private:
// 只实现一次,就满足了Role1,Role2,Role3的需要。
Role4& getRole4() override { return role4; }
Role4& role4;
};
更清晰的依赖语义描述
使用工厂方法来表达依赖的例子如下:
struct Role1
{
void f()
{
// ..
// 对依赖的引用
getRole2().doSth();
// ...
getRole3().blah();
// ...
}
private:
// 对依赖的声明
virtual Role2& getRole2() = 0;
virtual Role3& getRole3() = 0;
};
不难看出,这段代码的语义如下:
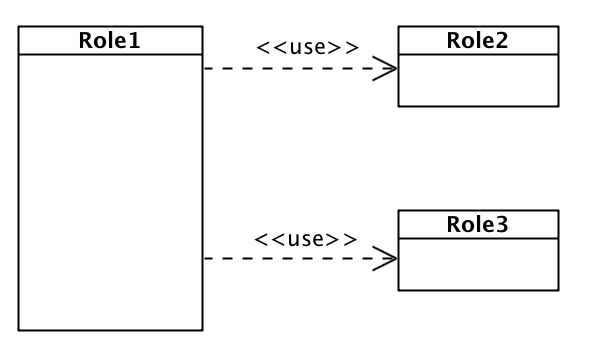
并且这样的实现方式也是完全模式化的,因而我们定义如下两个宏:
#define USE_ROLE(RoleType) \\\\
virtual RoleType& get##RoleType() = 0
#define ROLE(RoleType) get##RoleType()
通过它们,之前的例子就可以修改为:
struct Role1
{
void f()
{
// 对依赖的引用
ROLE(Role2).doSth();
// ...
ROLE(Role3).blah();
}
private:
// 对依赖的声明
USE_ROLE(Role2);
USE_ROLE(Role3);
};
不难发现,一个角色,通过USE_ROLE语义,仅仅声明自己对另外一个角色的依赖,却完全无需关心这个角色的实现来自何处,也完全无需关注谁会注入给它。这实现了与经典依赖注入方式完全相同的语义,达到了完全相同的解耦效果。
而对于工厂的实现,同样也有明确的模式和清晰的语义:
struct Object
: Role1
, Role2
, Role3
, Role4
{
// 这些工厂方法即属于工厂职责的实现
Role2& getRole2() override { return *this; }
Role3& getRole3() override { return *this; }
Role4& getRole4() override { return *this; }
};
因而,我们可以定义如下的宏:
#define IMPL_ROLE(RoleType) \\\\
RoleType& get##RoleType() override { return *this; }
利用它,我们就可以将工厂代码改写为:
struct Object
: Role1
, Role2
, Role3
, Role4
{
private:
IMPL_ROLE(Role2);
IMPL_ROLE(Role3);
IMPL_ROLE(Role4);
};
直接引用,还是工厂方法
直接引用,相对于工厂方法,会带来更多的内存成本,以及工厂管理成本。
但直接引用,会存在微弱的性能优势。根据我们的项目经验,这些性能优势微乎其微。但如果在你的项目中,经过事后测量,确实发现热点处可以通过直接引用提升性能,那就可以在那个点,将工厂方法,改为直接引用的方式。而这个改动,并不困难。
继承树倒置
当使用单根继承时,如果子类没有任何代码,这样的继承是没有太多意义的。比如:
struct Base
{
void foo();
void bar();
private:
int a;
int b;
};
// 这样的继承,由于子类没有任何代码,
// 如果不是出于某些特定的目的,是没有任何意义的。
struct Derived : Base
{};
但是,当使用多重继承时,子类没有任何实现代码,却表达了一个非常有价值的语义:组合。
TypeAPerson有效的将多个类的数据和行为都组合到一个对象上。最重要的是,这个没有任何实现代码的子类,恰恰是我们设计时所追求的单一职责 —— TypeAPerson的唯一职责是:将所有角色组合到一个对象身上。
这样的设计是一种以组合的方式,最终聚合到单个对象类。它和经典的单根继承方式所导致的继承树正好相反。因而,我们也称它为继承树倒置模式。下图是来自于一个项目的例子:
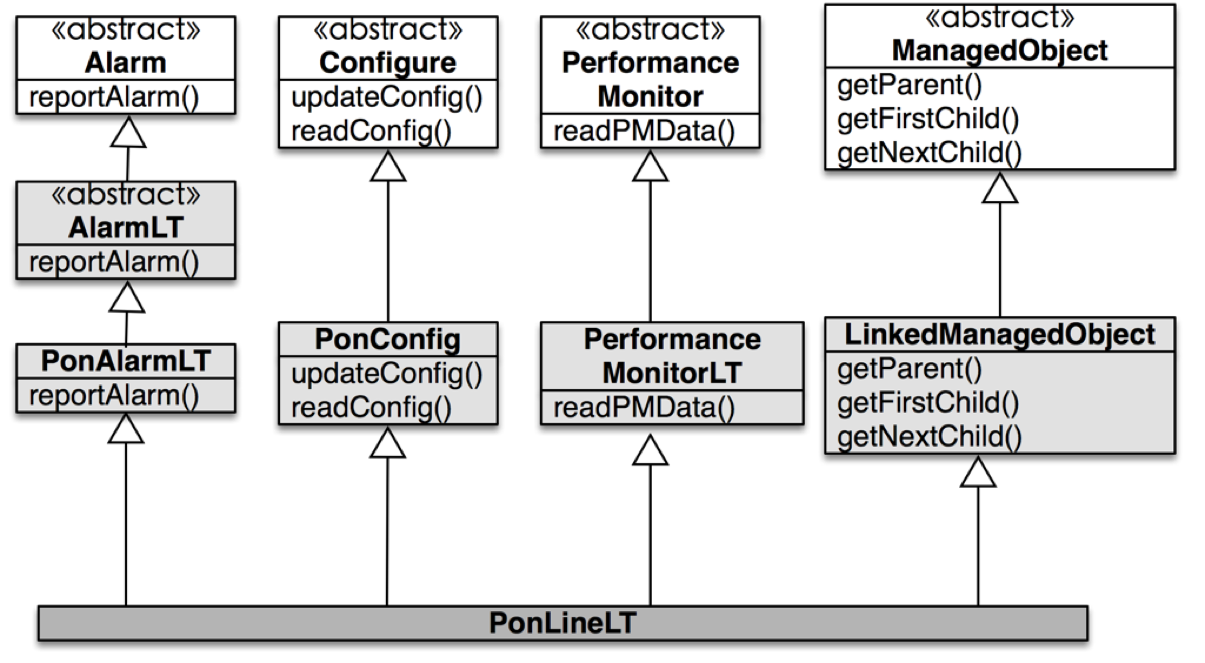
继承优于委托
通常在设计中,我们得到的建议往往是:委托优于继承。其原因在于:委托是黑盒复用,而继承是一种白盒复用。
但正如我们之前讨论的,在多角色对象的实现中,最终的对象类,没有任何业务实现代码,因此不会对父类产生任何实现上的依赖。角色类的所有实现,对对象类类而言,在逻辑上和一个黑盒无异。
而反过来,继承式组合,相对于委托式组合,至少有如下优势:
- 简化了组合方式;
- 大大降低了内存开销;
- 消除了角色构造顺序问题;
- 大大简化了依赖管理问题;
- 对象到角色的自动转换;
因而,在多角色对象的场景下,继承式组合要优于委托式组合。
为何这样的多重继承不邪恶
过去,多重继承在面向对象社区内一直颇有争议。大多数书籍都会建议:尽量避免使用多重继承,要谨慎的使用多重继承。于是多重继承就逐渐变为程序员唯恐避之不及的东西。
多重继承的邪恶之处主要体现在几个方面:
菱形继承所带来的数据重复,以及名字二义性。因此,
C++引入了virtual继承来解决这类问题;即便不是菱形继承,多个父类之间的名字也可能存在冲突,从而导致的二义性;
如果子类需要扩展或改写多个父类的方法时,造成子类的职责不明,语义混乱;
相对于委托,继承是一种白盒复用,即子类可以访问父类的
protected成员, 这会导致更强的耦合。而多重继承,由于耦合了多个父类,相对于单根继承,这会产生更强的耦合关系。
但我们看看TypeAPerson,它没有任何代码。因而它没有操作任何父类的数据和方法,所以,第3点和第4点的缺点并不存在。
关于第2点所描述的二义性问题,这需要从两个方面来看:子类的内部和外部。
从子类内部的角度,由于无需访问父类,所以,多个父类之间即便存在名字冲突,在子类内部也不会造成二义性问题。
而从子类外部来看,如果直接通过子类的实例来调用成员函数,这种二义性确实可能存在。但对于一个多角色对象,所有外部访问都应该是基于角色的。而对于每个角色,名字的对应关系是明确的,没有任何二义性。所以,多角色对象特定的访问模式,决定了在外部也不会造成二义性。
至于第1点,菱形继承带来的两个问题:数据重复和二义性。
我们首先应该避免不符合我们需要的菱形继承。
对于由设计而自然产生的菱形继承,我们无需使用virtual继承来避免数据重复。这分为两种情况:
基类数据的重复正是每个角色实现的需要。对于每个角色,它确实需要有自己的一份数据拷贝,即便这些数据和另外一个角色是重复的。这些“重复数据”在每个角色那里都有自己的不同状态。另外,由于外部访问是基于某个具体角色的,所以不会造成二义性问题。
如果基类数据是共享的,那也不应该使用
virtual继承,而是通过委托关系来共享数据。这样,就可以更加合理的避免数据重复。
至于行为重复,由于角色与角色之间的需求是不应该重叠的。所以,对于同一个对象,很难出现两个角色之间有相同的行为子集。如果出现,则说明这两个角色的职责都不单一。将重叠的行为子集定义为一个新的角色,是一个更合理的设计选择。
综上所属,对于多角色对象而言,这种组合方式不会从实质上带来多重继承所引起的任何问题。
简化内存管理成本
在开篇时,我们已经提到:很多通信设备,为了避免内存管理所导致的问题:比如碎片化,浪费,以及运行时内存分配失败,会对领域对象自定义自己的内存管理器,并在系统加载时,就会预先分配所需的所有内存。如下:
struct Object
: Role1
, Role2
, Role3
, Role4
{
// 重载 new, delete
void* operator new(size_t);
void free(void* p);
private:
IMPL_ROLE(Role2);
IMPL_ROLE(Role3);
IMPL_ROLE(Role4);
};
namespace
{
// 定义数量为500的Object对象池。
ObjectAllocator<Object, 500> allocator;
}
// 大对象从自己的对象池分配
void* Object::operator new(size_t)
{
return allocator.alloc();
}
void Object::free(void* p)
{
return allocator.free(p);
}
但如果系统由于高内聚低耦合的方式而导致了很多小对象,就不得不为每个小对象都定义自己的内存管理器,并且要按照其最大数量来预先分配,这会随着小对象种类的增多,而大大加重内存管理的负担。
另外,在高性能计算领域,为了降低cache miss rate,一般的做法是将关联访问数据都尽可能的放在一起。如果分隔为很多小对象,它们都从不同的内存区域进行存放的话,对于性能会造成不同程度的负面影响。
而通过大对象的方式,所有的数据最后都聚集在一个对象身上,它们的内存是连续的。这对于性能及性能优化都有帮助。
其它问题
数据该怎样存放
数据按照高内聚,低耦合的原则,归属于各个不同的角色。然后,角色间根据需要,引用并访问对方的接口。
私有角色
有些角色,纯粹是因为一个对象自身的需要,并不需要公开给外部,则可以通过private继承(参见《The Virtues Of Bastard》)进行组合。其它角色对它的引用,依然通过USE_ROLE(Role)的方式获取。
总结
本文介绍了使用C++,在高性能计算领域,内存受限系统下,对于小类,大对象实现方式的主要方面。
对于这类系统,小类,大对象,会带来各方面的帮助:
- 清晰:有助于建立与领域清晰映射的领域模型;
- 弹性:在满足性能,空间的约束前提下,遵从高内聚低耦合的设计原则,让软件易于理解,易于变化;
- 简单:在满足领域特定约束的前提下,降低了诸多偶发成本。
因此,小类,大对象设计模式,成为我们最近几个电信产品的设计的基石。几年前,我当时所在的团队,设计了一款t-shirt,表达了小类,大对象对于我们那个项目的重要性,以及我们对它的喜爱:

