
从今天起,我们要开始学习用工程化的思想去解决问题。之前,我们总是把所有的代码写在一个源文件中,这样看起来比较方便。不过这些代码中,有些在逻辑上关系并不紧密。对于这种情况,我们往往用独立的文件去管理。就像我们之前总把程序划分为几个相对独立的子功能,如果把这些不同的子功能分别用独立的文件管理起来,就能帮助我们更容易理解代码的逻辑结构。
很多同学觉得这个系列越往后代码越多,越难理解。其实,一个大的问题在被拆成若干个小程序之后,都是非常容易的。如果拿出任何一个子功能出来,大部分人都能顺利完成,那为什么放在一起就觉得难了呢,原因就在于缺乏一种工程化的编程思想。
今天,我们就模拟一下团队合作,看看如何通过多人协作的方法来解决上一篇中的习题。
1. 题目
编程统计出input.txt文件保存的文章中,每个单词出现的次数。文章内容如下:
In this chapter we will be looking at files and directories and how to manipulate them. We will learn how to create files, open them, read, write and close them. We'll also learn how programs can manipulate directories, to create, scan and delete them, for example. After the last chapter's diversion into shells, we now start programming in C.
Before proceeding to the way UNIX handles file I/O, we'll review the concepts associated with files, directories and devices. To manipulate files and directories, we need to make system calls (the UNIX parallel of the Windows API), but there also exists a whole range of library functions, the standard I/O library (stdio), to make file handling more efficient.
这段文字来自网络。为了统计更有意义,加入两个条件:
- 统计过程中不考虑空格和标点符号
- 不区分大小写(可以把所有字母转成小写后参与统计)
2. 分析
首先,我们思考一下,程序流程大概如下:
- 依次扫描每个单词
- 把单词做简单的处理
- 查找单词计数
- 结果排序整理
- 打印输出
用这五个功能就能够组成最终的程序。假如我们有一个5个人团队来完成这个工作,那就可以让这5个人分别负责一个部分。对于每个人而言,他的工作量仅仅是实现一个非常简单的小程序。下面我们来看看这几个小程序。
3. 小程序一 : 文件读取
题目:
请编程实现把input.txt文件中的每个单词打印在屏幕上。
看到这个题目,我们很容易想到天花板编程手把手计划-第1期-第6天中从文件中读取表达式的方法。我们依然希望像读键盘输入那样读取文件内容。这个问题我们交给小A同学做,他的代码如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#define MAX_SIZE 50
int main()
{
char str[MAX_SIZE];
freopen("input.txt", "r", stdin);
while (1)
{
str[0] = 0;
scanf("%s", str);
if (str[0] == 0)
{
break;
}
printf("%s\n", str);
}
}
有了前面的基础,这段代码应该很好理解。通过循环调用scanf函数来读取每一个字符串。需要注意的是在scanf函数之前,我们用了str[0] = 0;这句话对str数组进行了初始化。这样在文件结尾处,str不会发生变化。这时我们就知道循环可以结束了。
这段代码的执行结果如下:

现在,问题来了。如果小A同学最终给你提交的是这份代码,你能方便地使用吗?换句话说,你希望怎样使用他写好的代码呢?如果是我,我希望他能够封装成API函数给我。了解了我的需求,小A同学给我提供了两个文件:
- 文件:FileOper.h
// File : FileOper.h
// Author : 小A
#ifndef __FILE_OPER_H__
#define __FILE_OPER_H__
#include <stdio.h>
void FileInit();
int FileGetString(char* pBuf);
void FileDispose();
#endif
- 文件FileOper.c
// File : FileOper.c
// Author : 小A
#define _CRT_SECURE_NO_WARNINGS
#include "FileOper.h"
void FileInit()
{
freopen("input.txt", "r", stdin);
}
int FileGetString(char* pBuf)
{
pBuf[0] = 0;
scanf("%s", pBuf);
if (pBuf[0] == 0)
{
return 0;
}
else
{
return 1;
}
}
void FileDispose()
{
fclose(stdin);
}
于是,我在文件main.c中只需要调用者三个函数即可。
#include <stdio.h>
#include "FileOper.h"
#define MAX_SIZE 50
int main()
{
char str[MAX_SIZE];
FileInit();
while (FileGetString(str) == 1)
{
printf("%s\n", str);
}
FileDispose();
}
现在小A的任务已经完成了。也许有人会说,这么一来代码行数会变多,那是因为我们的程序实在太简单了,如果业务逻辑稍微复杂一些,你就会发现这么拆开变得豁然开朗了。
4. 小程序二 : 字符处理
我们从文件中得到了一组单词,但由于有标点符号和大小写字母,影响了我们的统计。于是小B同学领导了这个小程序。
题目:
实现一个字符串过滤函数,滤掉字符串中的无用字符,并把所有的大写字母转换成小写字母。
仔细分析一下,这个小程序包括两个功能,一个是大小写字母的转换,另外一个是删除符号。小B给出了下面两个文件:
- Filter.h
// File : Filter.h
// Author : 小B
#ifndef __FILTER_H__
#define __FILTER_H__
void Filter(char* pBuf);
#endif
- Filter.c
// File : Filter.c
// Author : 小B
#include "Filter.h"
void ToLower(char* pBuf)
{
int i;
for (i = 0; pBuf[i] != 0; i++)
{
if (pBuf[i] >= 'A' && pBuf[i] <= 'Z')
{
pBuf[i] += 32;
}
}
}
void Remove(char* pBuf, int index)
{
int i;
for (i = index; pBuf[i] != 0; i++)
{
pBuf[i] = pBuf[i + 1];
}
}
void FiltSymbols(char* pBuf)
{
int i;
for (i = 0; pBuf[i] != 0; i++)
{
switch (pBuf[i])
{
case '(':
// go to next
case ')':
// go to next
case ',':
// go to next
case '.':
Remove(pBuf, i);
i--;
break;
default:
// Do nothing
break;
}
}
}
void Filter(char* pBuf)
{
ToLower(pBuf);
FiltSymbols(pBuf);
}
ToLower函数负责把传入字符串的大写字母转成小写字母。由于在ASCII码表中,大写字母和它对应的小写字母的值差32,所以直接计算即可。Remove函数的功能是删除一个字符,实现过程是把它后面的每一个字符向前移动。FiltSymbols的功能是删掉符号,这里用了switch的一种特殊用法,需要注意的是在不使用break的时候要用注释说明你是故意不写的。
有人会说,头文件只有一个函数声明,是否有必要专门写一组文件呢?其实这才是重点,通过这种方法,小B同学有效地帮我们过滤掉了冗余信息,只提供给我们必要的Filter函数。极不容易引起混淆,也最大限度的降低了耦合性。在main函数中,我们只需要做简单修改就好。
#include <stdio.h>
#include "FileOper.h"
#include "Filter.h"
#define MAX_SIZE 50
int main()
{
char str[MAX_SIZE];
FileInit();
while (FileGetString(str) == 1)
{
Filter(str);
printf("%s\n", str);
}
FileDispose();
}
看看效果,是不是工整多了。
5. 小程序三 :单词统计
下面到了小C出场了,他遇到的题目是。编程统计出一组字符串中每个字符串出现的次数。
首先,为了实现统计功能,首先要设计一个合适的数据结构。
- 文件Word.h
// File : Word.h
// Author : 小C
#ifndef __WORD_H__
#define __WORD_H__
#define CHAR_SIZE 50
typedef struct _tagWord
{
char m_arr[CHAR_SIZE];
int m_cnt;
}Word;
void WordSet(Word* pWord, char* pStr, int cnt);
void WordCpy(Word* pDest, Word* pSrc);
#endif
这个头文件定义了一个结构体Word,它保存了一个字符串和它的次数。为了方便使用,还提供了两个函数用来给结构体赋值和拷贝。这两个函数的实现如下:
- 文件Word.c
// File : Word.c
// Author : 小C
#define _CRT_SECURE_NO_WARNINGS
#include "Word.h"
#include <string.h>
void WordSet(Word* pWord, char* pStr, int cnt)
{
strcpy(pWord->m_arr, pStr);
pWord->m_cnt = cnt;
}
void WordCpy(Word* pDest, Word* pSrc)
{
strcpy(pDest->m_arr, pSrc->m_arr);
pDest->m_cnt = pSrc->m_cnt;
}
接下来,小C又设计了一组统计方法,声明如下:
- 文件Dict.h
// File : Dict.h
// Author : 小C
#ifndef __DICT_H__
#define __DICT_H__
#include "Word.h"
void DictInit(); // 创建字典
void DictInsert(char* pStr); // 插入字符串
Word* DictSearch(char* pStr); // 查找字符串
void DictSort(); // 字典排序
void DictPrint(); // 字典打印
#endif
这个文件声明了五个函数,它们都以Dict开头,表明它们的存在是为了解决同一个问题,维护了一个字典的使用。
- 文件Fille.c
// File : Dict.c
// Author : 小C/小D/小E
#include "Dict.h"
#include <string.h>
#define SIZE 200
Word g_arrWords[200];
int g_index;
void DictInit()
{
g_index = 0;
}
void DictInsert(char* pStr)
{
WordSet(&g_arrWords[g_index], pStr, 1);
g_index++;
}
Word* DictSearch(char* pStr)
{
int i;
for (i = 0; i < g_index; i++)
{
if (strcmp(g_arrWords[i].m_arr, pStr) == 0)
{
return &g_arrWords[i];
}
}
return NULL;
}
小C只实现了三个函数:
- DictInit()
字典初始化函数,它负责初始化数组g_arrWords。
- DictInsert()
它负责把一个字符串保存进字典。
- DictSearch()
这个函数负责在字典中寻找一个字符串的位置。找到了返回这个Word的指针,找不到返回NULL。这里用了最简单的方法,遍历所有的元素,比较每一个字符串看看是否匹配。比较的动作使用了字符串的库函数strcmp。
6. 小程序四 :字符串排序
小D负责实现DictSort函数,他在文件Dict.c中添加了下面的内容:
void DictSort()
{
int i, j;
Word wordT;
for (i = 0; i < g_index - 1; i++)
{
for (j = i + 1; j < g_index; j++)
{
if (strcmp(g_arrWords[i].m_arr, g_arrWords[j].m_arr) > 0)
{
WordCpy(&wordT, &g_arrWords[i]);
WordCpy(&g_arrWords[i], &g_arrWords[j]);
WordCpy(&g_arrWords[j], &wordT);
}
}
}
}
这里用了最常用的冒泡排序算法,通过字符串的比较实现排序。里面用到了WordCpy函数用来复制Word。
7. 小程序五 :打印输出
最后出场的是小E,他的任务很简单,把字典中的内容打印在屏幕上。
void DictPrint()
{
int i;
for (i = 0; i < g_index; i++)
{
printf("%12s - %d\n", g_arrWords[i].m_arr, g_arrWords[i].m_cnt);
}
}
8. 功能整合
五个小程序都已经完成了,现在作为项目的最终功能实现者,你拥有了四组API函数,看看如何利用这些代码来完成这个程序。打开文件main.c,代码如下:
#include <stdio.h>
#include "FileOper.h"
#include "Filter.h"
#include "Dict.h"
#define MAX_SIZE 50
int main()
{
char str[MAX_SIZE];
Word* pWord;
FileInit();
DictInit();
while (FileGetString(str) == 1)
{
Filter(str);
if ((pWord = DictSearch(str)) == NULL)
{
DictInsert(str);
}
else
{
pWord->m_cnt++;
}
//printf("%s\n", str);
}
DictSort();
DictPrint();
FileDispose();
}
执行结果:
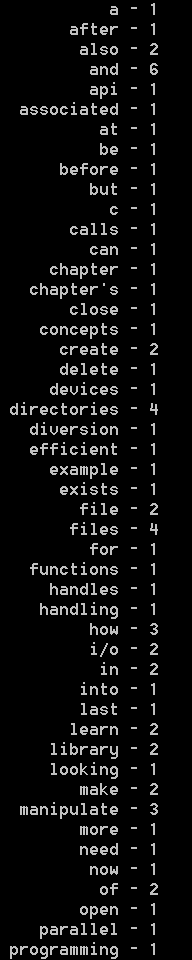
今天这个题目是一个比较简单的练习,我在某本C语言教科书的课后习题中看到的。但我们用了一个相对复杂的工程方式来设计代码,希望大家在看懂代码的同时重点思考这个项目的逻辑结构和设计思想。如果有什么问题,可以在群里讨论。
这部分源码如果不清楚,请在GitHub中下载。
9. 课后练习
今天的练习题我们做一道简单的开发性程序。请编程实现一个功能,输入任意一个日期,计算出那一天是星期几。这道题没有任何限制,你可以设计任何自己喜欢的交互形式,可以使用任何自己能想到的算法。
我是天花板,让我们一起在软件开发中自我迭代。
如有任何问题,欢迎与我联系。
