一
前两天,有人专程跑到我的文章《类与封装》留言,说数据结构更加抽象,更加稳定,因而OO的封装不make sense。为了证明其观点,还专门引用了Fred Brooks在《人月神话》里的叙述:
Show me your flowcharts, and conceal your tables, and I shall continue to be mystified; show me your tables and I won't usually need your flowcharts: they'll be obvious.
-- Fred Brooks, "The Mythical Man Month", chapter 9
这位朋友的观点其实并不鲜见:我已经见过太多的反OO码农,以此为证据,来支持其“OO无用,封装无用,对数据结构的直接依赖更好...”诸如此类的结论。而那位朋友更是在回复中对众人呼吁:作为程序员,不要学什么OO,SOLID……
而每次听到这类宗教战争般的言论,我都会一边苦笑,一边心里嘀咕:这些人真正负责过复杂一点的系统开发,交付和维护么?
二
事实上,强调数据结构比算法更重要的观点,我还可以举出更多。
比如Linus Torvalds在一封邮件里所表达的观点:
(*) I will, in fact, claim that the difference between a bad programmer
and a good one is whether he considers his code or his data structures
more important. Bad programmers worry about the code. Good programmers
worry about data structures and their relationships.
再比如,在《The Art of Unix Programming》里,也表达了类似的观点:
Rule of Representation: Fold knowledge into data so program logic can be stupid and robust.
Even the simplest procedural logic is hard for humans to verify, but quite complex data structures are fairly easy to model and reason about. To see this, compare the expressiveness and explanatory power of a diagram of (say) a fifty-node pointer tree with a flowchart of a fifty-line program. Or, compare an array initializer expressing a conversion table with an equivalent switch statement. The difference in transparency and clarity is dramatic. See Rob Pike's Rule 5.
Data is more tractable than program logic. It follows that where you see a choice between complexity in data structures and complexity in code, choose the former. More: in evolving a design, you should actively seek ways to shift complexity from code to data.
The Unix community did not originate this insight, but a lot of Unix code displays its influence. The C language's facility at manipulating pointers, in particular, has encouraged the use of dynamically-modified reference structures at all levels of coding from the kernel upward. Simple pointer chases in such structures frequently do duties that implementations in other languages would instead have to embody in more elaborate procedures.
如果愿意,我还可以举出更多。
我从未怀疑过这些观点的正确性,而这也正是我的观点。
三
首先,所有这些被引用的观点,其实都是在强调:数据的清晰性。
任何一个有经验,有sense的程序员,都会承认数据结构的重要性。一个良好定义的数据结构以及它们之间的关系,往往比算法更清晰。
这是因为,一个良好的数据结构定义所要表达的概念,以及概念之间的关系,是一种高度结构化的信息。而我们人类的大脑,最善于理解的就是这类信息。相对于不那么结构化的,代表算法的流程图,实体关系图所需的智商指数要低的多。
而反过来,有了这些高度结构化的数据结构之后,我们就更容易推理和理解围绕这些数据结构的算法。
这也正是我们在分析一个业务领域,建立其领域模型时,静态视图:包含类(概念实体)以及类与类之间的关系,对于理解一个领域至关重要的原因。
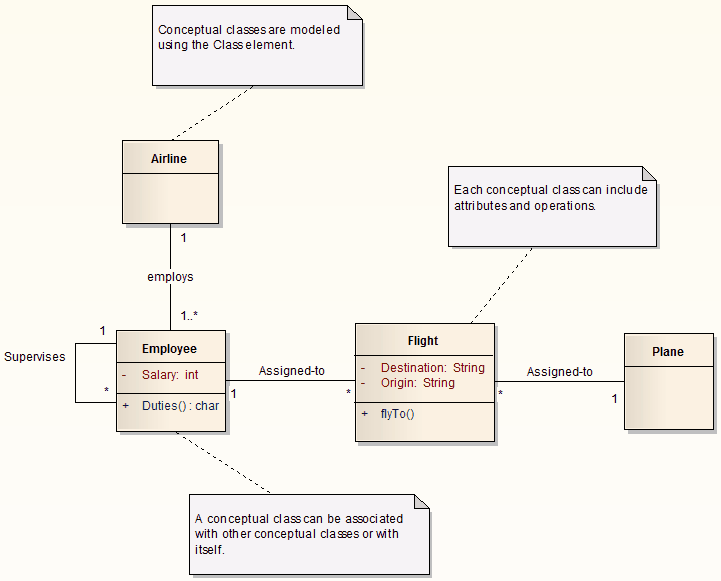
当然,这一切,都是建立在一个良好的领域分析基础上的。作为咨询师,我见过太多团队,根本不重视数据结构的定义,完全不考虑数据结构所代表的概念,也不考虑数据的内聚性,只见到系统堆满了随机而凌乱的数据结构,从而让系统极难理解。
这也正是为何Linus强调:糟糕的程序员更关注代码(算法);而优秀的程序员更关注数据结构和它们之间的关系。
数据结构定义的重要性,怎么强调都不为过。
四
数据结构,相对于算法,不仅更清晰,在大多数情况下甚至会更稳定。
首先,我们先看一个简单的例子。如下代码定义了一个数据结构Rectangle:
struct Rectangle
{
unsigned int height;
unsigned int width;
};
不难发现,这个用来表现矩形的数据结构,是非常清晰的。
而围绕它的算法,相对于它的数据,却更加不稳定。比如,现在某个需求需要求它的周长,因而,我们需要提供一个算法:
unsigned int calcPerimeter(Rectangle* rect)
{
return (rect->height + rect->width) * 2;
}
当然,也可以将算法实现为:
unsigned int calcPerimeter(Rectangle* rect)
{
return rect->height * 2 + rect->width * 2;
}
或者:
unsigned int calcPerimeter(Rectangle* rect)
{
return rect->height + rect->height + rect->width + rect->width;
}
不难看出,对于同一个需求,我们可以基于同一个数据结构,给出不同的算法实现。因而,在这个例子中,数据结构比算法更清晰,也更稳定。
但这是否就意味着,封装对于Rectangle就没有意义?
五
对于一个软件系统,单纯的数据结构是没有太多意义的(除非它只是一个数据展现系统)。数据结构和算法,都是为客户的根本需要而服务。没有客户的需要,则数据结构和算法,无论谁更清晰,更稳定,都没有任何意义。一个数据结构该怎么定义,一个算法该如何设计,这一切都是从客户的需要出发,结合各种约束,程序员作出的选择而已。
比如,同样都是矩形,如果现在我们正在做的是一个画图系统,则其数据并不必然使用width和height来表示,这时候,使用坐标位置,或向量来表示矩形,会是更合理的选择。
因而,尽管在不同领域里,有可能都能挖掘出相同的领域概念,以及相同的领域概念间关系。但其具体数据(属性),却会伴随着不同领域的需求不同而不同。
另外,即便在同一个领域,对于同样的业务需求,当定义数据结构时,往往也会由于性能,空间,便利性等非功能性需求和设计约束,而作出不同的决定。比如,同样都是1..N的关系,我究竟该选择Array还是List?如果选择List,改选单向,还是双向?对于每个有经验的C,C++开发者,这都是做一个真实系统时经常需要考虑的问题。
我们已经知道,Linus极其重视数据结构的定义,如果我们去看Linux Kernel的设计,就能知道,其数据结构的选择,和数据间的关联选择,会多大程度上受到非功能因素的影响。否则,那些数据结构的定义会更加清晰,稳定和简单。
但你无论如何选择,最终都是为了满足客户的业务需要。
六
回到我们的Rectangle。从需求出发,我们的系统存在Rectangle这个概念,那么客户需要这个概念的真正原因是什么?是Rectangle的数据结构,还是calcPerimeter内部的算法?
答案是:都不是。
客户真正需要,也真正依赖的是API: unsigned int calcPerimeter(Rectangle* rect),而不是Rectangle的数据结构,更不是calcPerimeter的算法实现。
虽然数据结构比算法实现更稳定,但它再稳定,相对于API,也依然只是一种实现细节。
而让客户向着更稳定的方向依赖(参见《变化驱动:正交设计》),从而依赖API,而不是直接依赖数据结构,这就是封装的核心价值。
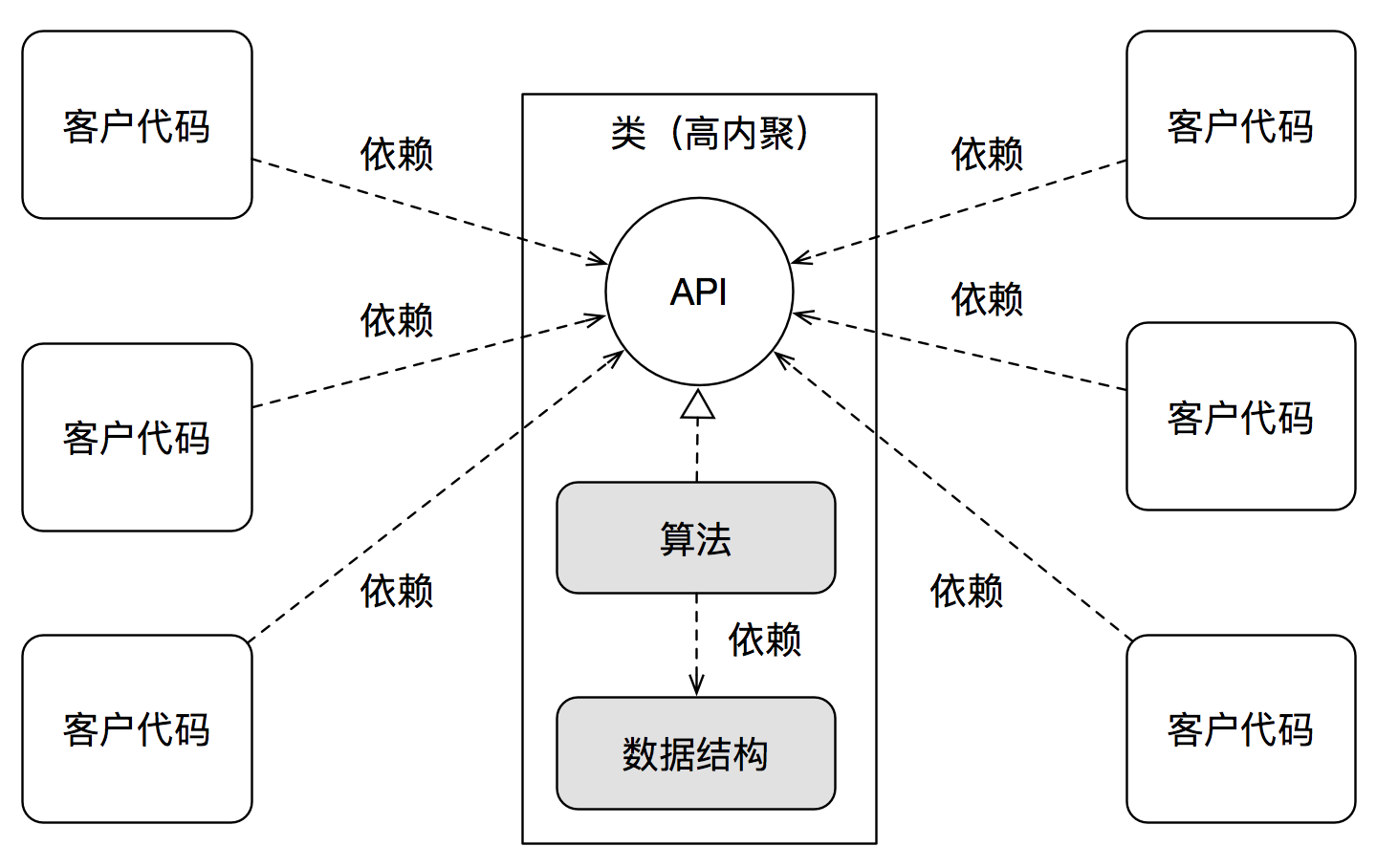
而如果不进行封装,客户拥有访问数据,并定义算法的自由,就会让客户同时依赖数据结构和算法。无论你认为数据结构更不稳定,还是算法更不稳定,总之都会让用户直接依赖在不稳定的事物上。同时,在大产品下,极易造成重复,这会进一步导致更严重的耦合(见《类与封装》)。
当数据结构和算法还在争论谁更抽象,更稳定时,API笑了。
七
而最最重要的部分,在Grady Booch著名的《面向对象分析与设计》中,对OOP定义的第一个要点则是:
利用对象作为面向对象编程的基本逻辑构建块,而不是利用算法。
这与把Procedure看做Building Block的面向过程范式,把Function看做Building Block的函数式范式相比,如果我们认为数据结构比算法更稳定是一个事实,那么毫无疑问,面向对象才是更加尊重这个事实的范式。
因而,从数据结构比算法更稳定出发,不仅不应该得到OO无用的结论,而应该恰恰相反:OO是在已有的范式中,最符合软件问题本质的选择。
