spark ML
参考文档:
Apache Spark
Spark's Python API
Python
Spark Context
创建SparkContext后,向master要资源,master分配资源给sc。
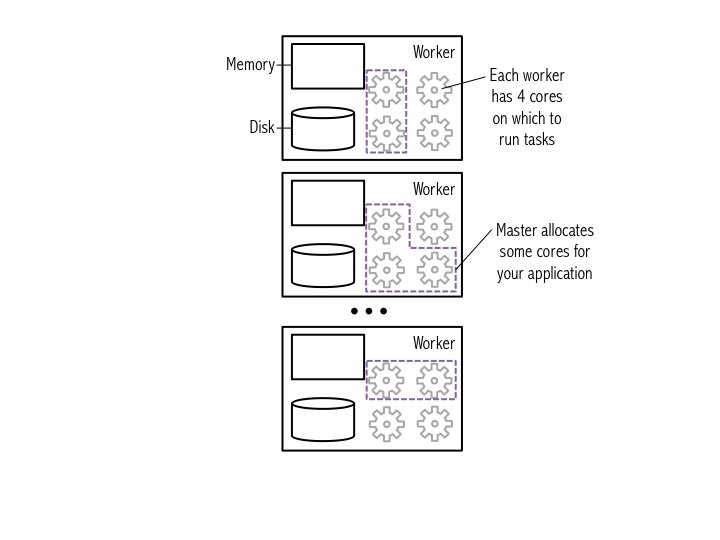
常用命令:
# Display the type of the Spark Context sc
type(sc)
#Out: pyspark.context.SparkContext
# List sc's attributes
dir(sc)
# Use help to obtain more detailed information
help(sc)
# After reading the help we've decided we want to use sc.version to see what version of Spark we are running
sc.version
Using RDD
Distributed data and using a collection to create an RDD
Spark中数据集表示为一个list,list被分成很多分区,存储在不同机器的内存中。
图示: 数据集被分层不同分区,存储在不同worker的内存中
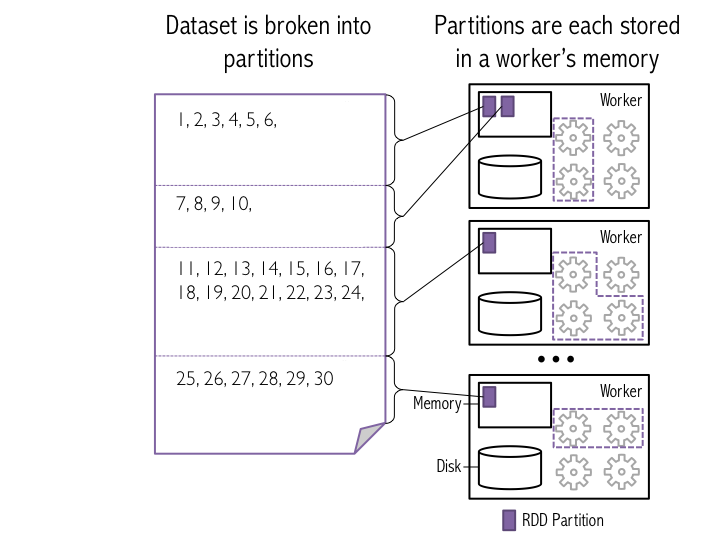
data = xrange(1, 10001)
# Parallelize data using 8 partitions
# This operation is a transformation of data into an RDD
# Spark uses lazy evaluation, so no Spark jobs are run at this point
xrangeRDD = sc.parallelize(data, 8)
# Let's see what type sc.parallelize() returned
print 'type of xrangeRDD: {0}'.format(type(xrangeRDD))
#Out: type of xrangeRDD: <class 'pyspark.rdd.PipelinedRDD'>
# How about if we use a range
dataRange = range(1, 10001)
rangeRDD = sc.parallelize(dataRange, 8)
print 'type of dataRangeRDD: {0}'.format(type(rangeRDD))
#Out: type of dataRangeRDD: <class 'pyspark.rdd.RDD'>
# Each RDD gets a unique ID
print 'xrangeRDD id: {0}'.format(xrangeRDD.id())
# We can name each newly created RDD using the setName() method
xrangeRDD.setName('My first RDD')
# Let's view the lineage (the set of transformations) of the RDD using toDebugString()
print xrangeRDD.toDebugString()
# Let's see how many partitions the RDD will be split into by using the getNumPartitions()
xrangeRDD.getNumPartitions()
map()
Subtract one from each value using map
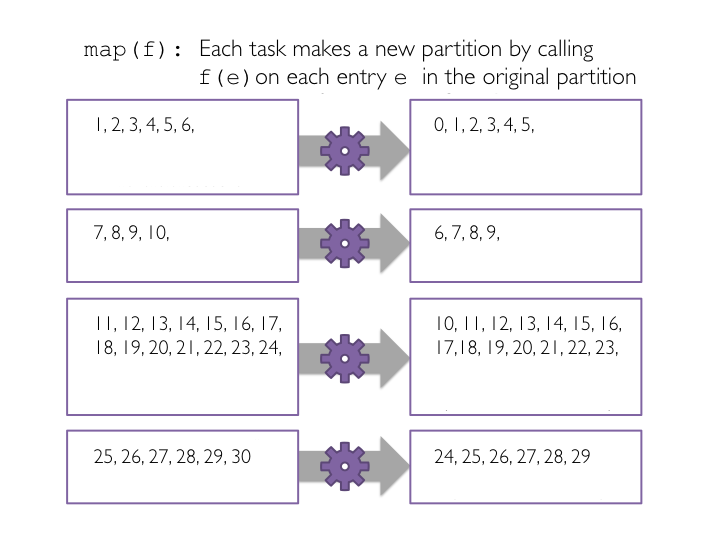
# Create sub function to subtract 1
def sub(value):
"""Subtracts one from `value`.
Args:
value (int): A number.
Returns:
int: `value` minus one.
"""
return (value - 1)
#Transform xrangeRDD through map transformation using sub function
#Because map is a transformation and Spark uses lazy evaluation, no jobs, stages,
#or tasks will be launched when we run this code.
subRDD = xrangeRDD.map(sub)
collect()
将RDD结果转换为list
action 操作,此时才会实际执行
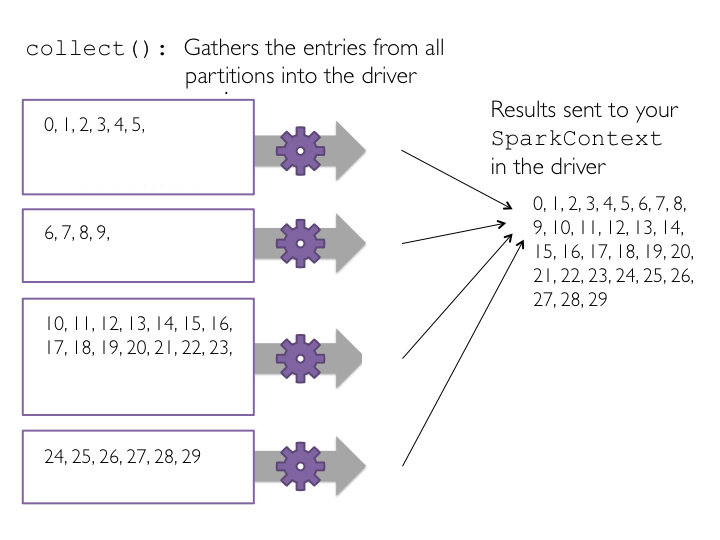
# Let's collect the data
print subRDD.collect()
#Out: [0, 1, 2, 3, 4……,9999]
count()
count RDD中记录个数
action 操作
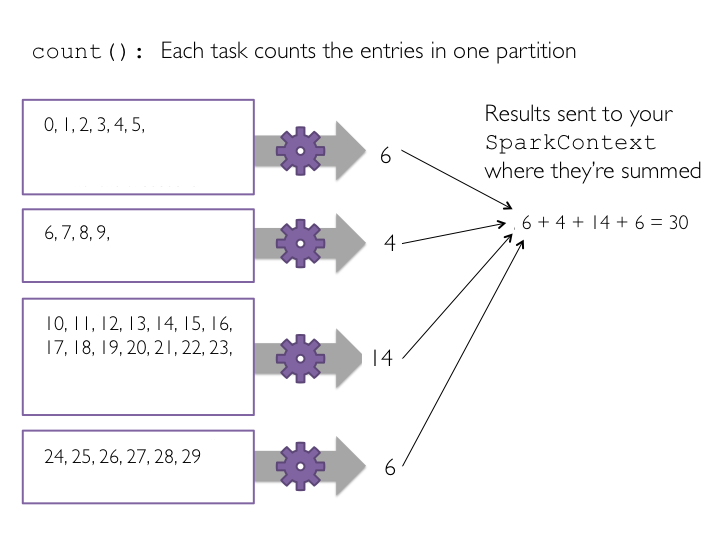
print xrangeRDD.count()
#Out: 10000
print subRDD.count()
#Out: 10000
filter()
过滤操作,从原RDD 中提取满足条件的记录,生成新的RDD
transformation operation
图:筛选小于10的数据
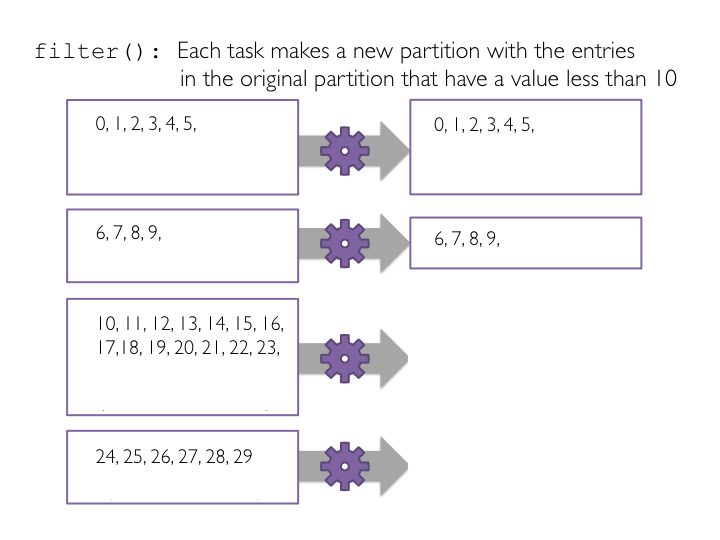
# Define a function to filter a single value
def ten(value):
"""Return whether value is below ten.
Args:
value (int): A number.
Returns:
bool: Whether `value` is less than ten.
"""
if (value < 10):
return True
else:
return False
# The ten function could also be written concisely as: def ten(value): return value < 10
# Pass the function ten to the filter transformation
# Filter is a transformation so no tasks are run
filteredRDD = subRDD.filter(ten)
# View the results using collect()
# Collect is an action and triggers the filter transformation to run
print filteredRDD.collect()
#Out:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Using Python lambda() functions
#filter values less than 10
lambdaRDD = subRDD.filter(lambda x: x < 10)
lambdaRDD.collect()
#Out: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# Let's collect the even values less than 10
evenRDD = lambdaRDD.filter(lambda x: x % 2 == 0)
evenRDD.collect()
#Out:[0, 2, 4, 6, 8]
常用actions
| action | 说明 |
|---|---|
| first() | Return the first element in this RDD. |
| take(num) | Take the first num elements of the RDD. |
| top(num, key=None) | Get the top N elements from a RDD.Note: It returns the list sorted in descending order. |
| takeOrdered(num, key=None) | Get the N elements from a RDD ordered in ascending order or as specified by the optional key function. |
| reduce(f) | Reduces the elements of this RDD using the specified commutative and associative binary operator. |
| countByValue() | Return the count of each unique value in this RDD as a dictionary of (value, count) pairs |
| takeSample(withReplacement, num, seed=None) | returns an array with a random sample of elements from the dataset |
reduce(f) 先在各分区上计算,然后再汇总各个分区的结果进行计算。 函数f要符合 交换律和结合律,如果不符合的话,计算结果可能会发生变化。
The reduce() action reduces the elements of a RDD to a single value by applying a function that takes two parameters and returns a single value.
The function should be commutative and associative, as reduce() is applied at the partition level and then again to aggregate results from partitions. If these rules don't hold, the results from reduce() will be inconsistent. Reducing locally at partitions makes reduce() very efficient.
# Let's get the first element
print filteredRDD.first()
#Out:0
# The first 4
print filteredRDD.take(4)
#Out:[0, 1, 2, 3]
# Note that it is ok to take more elements than the RDD has
print filteredRDD.take(12)
#Out:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# Retrieve the three smallest elements ascending order 升序
print filteredRDD.takeOrdered(3)
#Out:[0, 1, 2]
# Retrieve the five largest elements descending order 降序
print filteredRDD.top(5)
#Out:[9, 8, 7, 6, 5]
# Pass a lambda function to takeOrdered to reverse the order
filteredRDD.takeOrdered(4, lambda s: -s)
#Out:[9, 8, 7, 6]
# Obtain Python's add function
from operator import add
# Efficiently sum the RDD using reduce
print filteredRDD.reduce(add)
# Sum using reduce with a lambda function
print filteredRDD.reduce(lambda a, b: a + b)
# Note that subtraction is not both associative and commutative
print filteredRDD.reduce(lambda a, b: a - b)
print filteredRDD.repartition(4).reduce(lambda a, b: a - b)
# While addition is
print filteredRDD.repartition(4).reduce(lambda a, b: a + b)
#Out:45
#Out:45
#Out:-45
#Out:21
#Out:45
# takeSample reusing elements
print filteredRDD.takeSample(withReplacement=True, num=6)
# takeSample without reuse
print filteredRDD.takeSample(withReplacement=False, num=6)
# Set seed for predictability
print filteredRDD.takeSample(withReplacement=False, num=6, seed=500)
# Try reruning this cell and the cell above -- the results from this cell will remain constant
# Use ctrl-enter to run without moving to the next cell
# Create new base RDD to show countByValue
repetitiveRDD = sc.parallelize([1, 2, 3, 1, 2, 3, 1, 2, 1, 2, 3, 3, 3, 4, 5, 4, 6])
print repetitiveRDD.countByValue()
#Out:defaultdict(<type 'int'>, {1: 4, 2: 4, 3: 5, 4: 2, 5: 1, 6: 1})
常用transformations
flatMap()
Return a new RDD by first applying a function to all elements of this RDD, and then flattening the results.
# Let's create a new base RDD to work from
wordsList = ['cat', 'elephant', 'rat', 'rat', 'cat']
wordsRDD = sc.parallelize(wordsList, 4)
# Use map
singularAndPluralWordsRDDMap = wordsRDD.map(lambda x: (x, x + 's'))
# Use flatMap
singularAndPluralWordsRDD = wordsRDD.flatMap(lambda x: (x, x + 's'))
# View the results
print singularAndPluralWordsRDDMap.collect()
#Out:[('cat', 'cats'), ('elephant', 'elephants'), ('rat', 'rats'), ('rat', 'rats'), ('cat', 'cats')]
print singularAndPluralWordsRDD.collect()
#Out:['cat', 'cats', 'elephant', 'elephants', 'rat', 'rats', 'rat', 'rats', 'cat', 'cats']
# View the number of elements in the RDD
print singularAndPluralWordsRDDMap.count()
#Out:5
print singularAndPluralWordsRDD.count()
#Out:10
groupByKey and reduceByKey
groupByKey(numPartitions=None)
Group the values for each key in the RDD into a single sequence. Hash-partitions the resulting RDD with numPartitions partitions.
reduceByKey (func, numPartitions=None)
Merge the values for each key using an associative reduce function.
类似MR的combiner会在每个mapper上先 merge,后再汇总到reducer
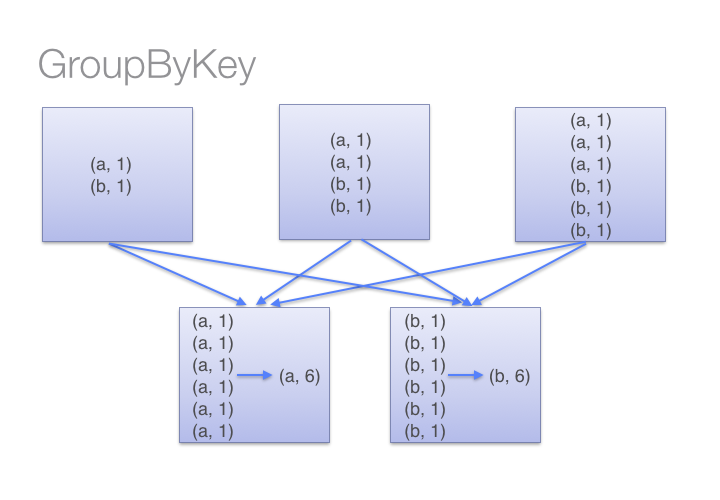
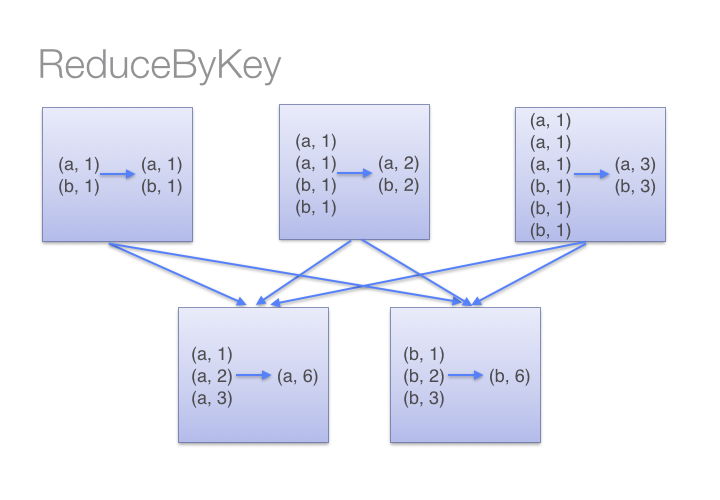
尽量少用groupByKey(),用reduceByKey()或下面2个代替
combineByKey() can be used when you are combining elements but your return type differs from your input value type.
foldByKey() merges the values for each key using an associative function and a neutral "zero value".
pairRDD = sc.parallelize([('a', 1), ('a', 2), ('b', 1)])
# mapValues only used to improve format for printing
print pairRDD.groupByKey().mapValues(lambda x: list(x)).collect()
# Different ways to sum by key
print pairRDD.groupByKey().map(lambda (k, v): (k, sum(v))).collect()
# Using mapValues, which is recommended when they key doesn't change
print pairRDD.groupByKey().mapValues(lambda x: sum(x)).collect()
# reduceByKey is more efficient / scalable
print pairRDD.reduceByKey(add).collect()
#Out:[('a', [1, 2]), ('b', [1])]
#Out:[('a', 3), ('b', 1)]
#Out:[('a', 3), ('b', 1)]
#Out:[('a', 3), ('b', 1)]
mapPartitions()
# mapPartitions takes a function that takes an iterator and returns an iterator
print wordsRDD.getNumPartitions()
print wordsRDD.collect()
itemsRDD = wordsRDD.mapPartitions(lambda iterator: [','.join(iterator)])
print itemsRDD.collect()
#Out:4
#Out:['cat', 'elephant', 'rat', 'rat', 'cat']
#Out:['cat', 'elephant', 'rat', 'rat,cat']
mapPartitionsWithIndex()
itemsByPartRDD = wordsRDD.mapPartitionsWithIndex(lambda index, iterator: [(index, list(iterator))])
# We can see that three of the (partitions) workers have one element and the fourth worker has two
# elements, although things may not bode well for the rat...
print itemsByPartRDD.collect()
# Rerun without returning a list (acts more like flatMap)
itemsByPartRDD = wordsRDD.mapPartitionsWithIndex(lambda index, iterator: (index, list(iterator)))
print itemsByPartRDD.collect()
#Out: [(0, ['cat']), (1, ['elephant']), (2, ['rat']), (3, ['rat', 'cat'])]
#Out: [0, ['cat'], 1, ['elephant'], 2, ['rat'], 3, ['rat', 'cat']]
Caching RDDs and storage options
.cache() 将RDD 保存在内存中
# Name the RDD
filteredRDD.setName('My Filtered RDD')
# Cache the RDD
filteredRDD.cache()
# Is it cached
print filteredRDD.is_cached
不需用时,可以用unpersist() 将数据从 内存和磁盘清理掉
# If we are done with the RDD we can unpersist it so that its memory can be reclaimed
filteredRDD.unpersist()
# Storage level for a non cached RDD
print filteredRDD.getStorageLevel()
filteredRDD.cache()
# Storage level for a cached RDD
print filteredRDD.getStorageLevel()
#Out:Serialized 1x Replicated
#Out:Memory Serialized 1x Replicated
Code style
用括号括起来
每个 method、transformation、action 单独一行
# Final version
(sc
.parallelize(data)
.map(lambda y: y - 1)
.filter(lambda x: x < 10)
.collect())
