title: iOS音频编程之变声处理
date: 2016-06-09
tags: Audio Unit,变声处理
博客地址
iOS音频编程之变声处理
需求:耳塞Mic实时录音,变声处理后实时输出
初始化
程序使用44100HZ的频率对原始的音频数据进行采样,并在音频输入的回调中处理采样的数据。
1)对AVAudioSession的一些设置
NSError *error;
self.session = [AVAudioSession sharedInstance];
[self.session setCategory:AVAudioSessionCategoryPlayAndRecord error:&error];
handleError(error);
//route变化监听
[[NSNotificationCenter defaultCenter] addObserver:self selector:@selector(audioSessionRouteChangeHandle:) name:AVAudioSessionRouteChangeNotification object:self.session];
[self.session setPreferredIOBufferDuration:0.005 error:&error];
handleError(error);
[self.session setPreferredSampleRate:kSmaple error:&error];
handleError(error);
[self.session setActive:YES error:&error];
handleError(error);
setPreferredIOBufferDurations文档上解释change to the I/O buffer duration,具体解释参看官方文档。我把它理解为在每次调用输入或输出的回调,能提供多长时间(由设置的这个值决定)的音频数据。但当我用0.005和0.93分别设置它的时候,发现回调中的inNumberFrames的值并未改变,一直是512,相当于每次输入或输出提供了512/44100=0.0116s的数据。(设置有问题?)
setPreferredSampleRate设置对音频数据的采样率。
2)获取AudioComponentInstance
//Obtain a RemoteIO unit instance
AudioComponentDescription acd;
acd.componentType = kAudioUnitType_Output;
acd.componentSubType = kAudioUnitSubType_RemoteIO;
acd.componentFlags = 0;
acd.componentFlagsMask = 0;
acd.componentManufacturer = kAudioUnitManufacturer_Apple;
AudioComponent inputComponent = AudioComponentFindNext(NULL, &acd);
AudioComponentInstanceNew(inputComponent, &_toneUnit);
3)对AudioComponentInstance的一些初始化设置
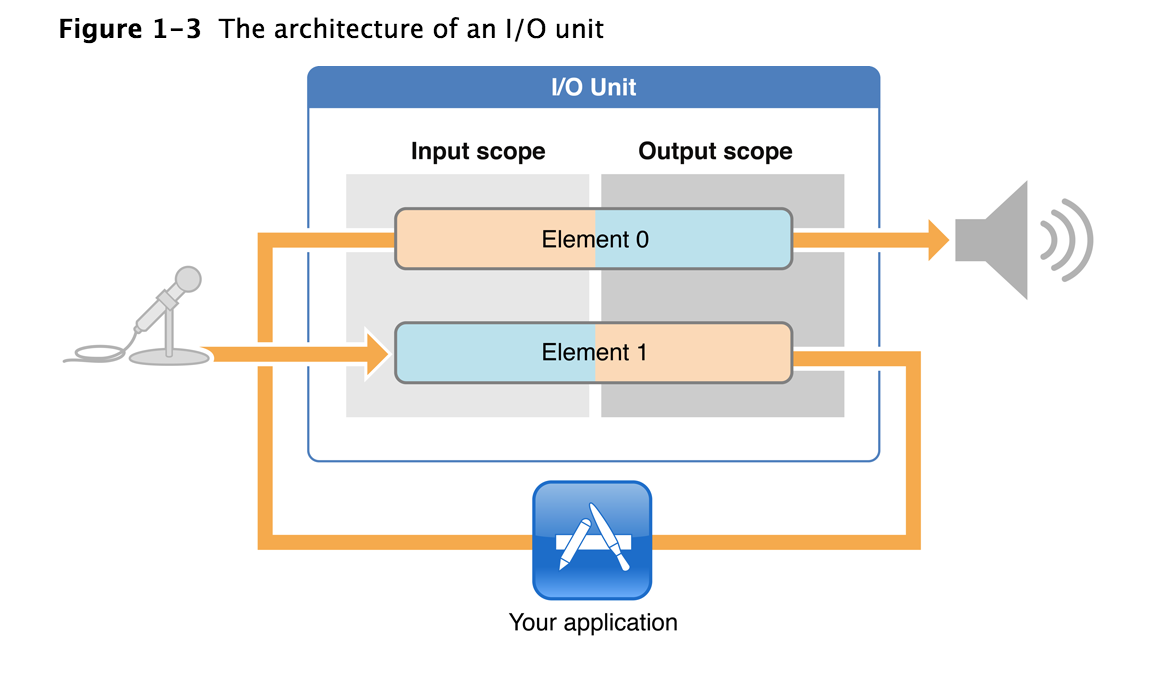
这张图蓝色框中的部分就是一个I/O Unit(AudioComponentInstance的实例).图中的Element 0连接Speaker,也叫Output Bus;Element 1连接Mic,也叫Input Bus.初始化它,就是对再这些Bus上的音频流的格式,设置输入输出的回调函数等。
UInt32 enable = 1;
AudioUnitSetProperty(_toneUnit,
kAudioOutputUnitProperty_EnableIO,
kAudioUnitScope_Input,
kInputBus,
&enable,
sizeof(enable));
AudioUnitSetProperty(_toneUnit,
kAudioOutputUnitProperty_EnableIO,
kAudioUnitScope_Output,
kOutoutBus, &enable, sizeof(enable));
mAudioFormat.mSampleRate = kSmaple;//采样率
mAudioFormat.mFormatID = kAudioFormatLinearPCM;//PCM采样
mAudioFormat.mFormatFlags = kAudioFormatFlagIsSignedInteger | kAudioFormatFlagIsPacked;
mAudioFormat.mFramesPerPacket = 1;//每个数据包多少帧
mAudioFormat.mChannelsPerFrame = 1;//1单声道,2立体声
mAudioFormat.mBitsPerChannel = 16;//语音每采样点占用位数
mAudioFormat.mBytesPerFrame = mAudioFormat.mBitsPerChannel*mAudioFormat.mChannelsPerFrame/8;//每帧的bytes数
mAudioFormat.mBytesPerPacket = mAudioFormat.mBytesPerFrame*mAudioFormat.mFramesPerPacket;//每个数据包的bytes总数,每帧的bytes数*每个数据包的帧数
mAudioFormat.mReserved = 0;
CheckError(AudioUnitSetProperty(_toneUnit,
kAudioUnitProperty_StreamFormat,
kAudioUnitScope_Input, kOutoutBus,
&mAudioFormat, sizeof(mAudioFormat)),
"couldn't set the remote I/O unit's output client format");
CheckError(AudioUnitSetProperty(_toneUnit,
kAudioUnitProperty_StreamFormat,
kAudioUnitScope_Output, kInputBus,
&mAudioFormat, sizeof(mAudioFormat)),
"couldn't set the remote I/O unit's input client format");
CheckError(AudioUnitSetProperty(_toneUnit,
kAudioOutputUnitProperty_SetInputCallback,
kAudioUnitScope_Output,
kInputBus,
&_inputProc, sizeof(_inputProc)),
"couldnt set remote i/o render callback for input");
CheckError(AudioUnitSetProperty(_toneUnit,
kAudioUnitProperty_SetRenderCallback,
kAudioUnitScope_Input,
kOutoutBus,
&_outputProc, sizeof(_outputProc)),
"couldnt set remote i/o render callback for output");
CheckError(AudioUnitInitialize(_toneUnit),
"couldn't initialize the remote I/O unit");
注意
kAudioUnitScope_Output/kAudioUnitScope_Input和kOutput/kInput的组合。设置输入输出使能时,Scope_Input下的kInput直接和Mic相连,所以是选用它们两;设置输出使能也类似。而设置音频的格式时,要选用Scope_Input下的kOutput和Scope_OutPut下的kInput,如果组合错误,为会返回-10865的错误码,意思说设置了只读属性,而在官方文档中也有说明,This hardware connection—at the input scope of element 1—is opaque to you. Your first access to audio data entering from the input hardware is at the output scope of element 1, output scope of element 0 is opaque。(疑问?在设置输入输出回调时以及Scope选择Input和Output以及Global都可以,但是官方文档中说Your first access to audio data entering from the input hardware is at the output scope of element 1)
音频处理
预备知识
变声操作实际是对声音信号的频谱进行搬移,在时域中乘以一个三角函数相当于在频域上进行了频谱的搬移。但使得频谱搬移了±𝑓。由下图傅里叶变化公式说明
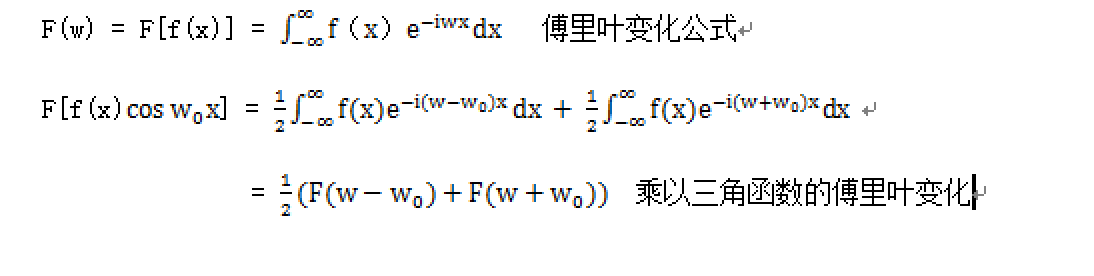
频谱搬移后,要把搬移的F(w-w。)的部分滤除。将声音的原始PCM放到Matlab中分析出频谱,然后进行搬移(实际上,我滤波这一步是失败的,还请小伙伴们告知我应该选一个怎样的滤波器)
1)写一个专门手机原始声音数据的程序,将声音数据保存到模拟上(用模拟器收集的声音,方便直接将写入到沙盒中的文件拷出来)。
-
将声音数据用matlab读出来(注意模拟器和matlab处理数据时的大小端,专门把数据转换读出来看了,两边都应该是小端模式),并分析和频移其频谱
matlab代码FID=fopen('record.txt','r');
fseek(FID,0,'eof');
len=ftell(FID);
frewind(FID);
A=fread(FID,len/2,'short');
A=A1.0-mean(A);
Y=fft(A);
Fs=44100;
f=Fs(0:length(A)/2 - 1)/length(A);
subplot(211);
plot(f,abs(Y(1:length(A)/2)));
k=0:length(A)-1;
cos_y=cos(2pi1000k/44100);
cos_y=cos_y';
A2=A.cos_y;
Y2=fft(A2);
subplot(212);
plot(f,abs(Y2(1:length(A)/2)));
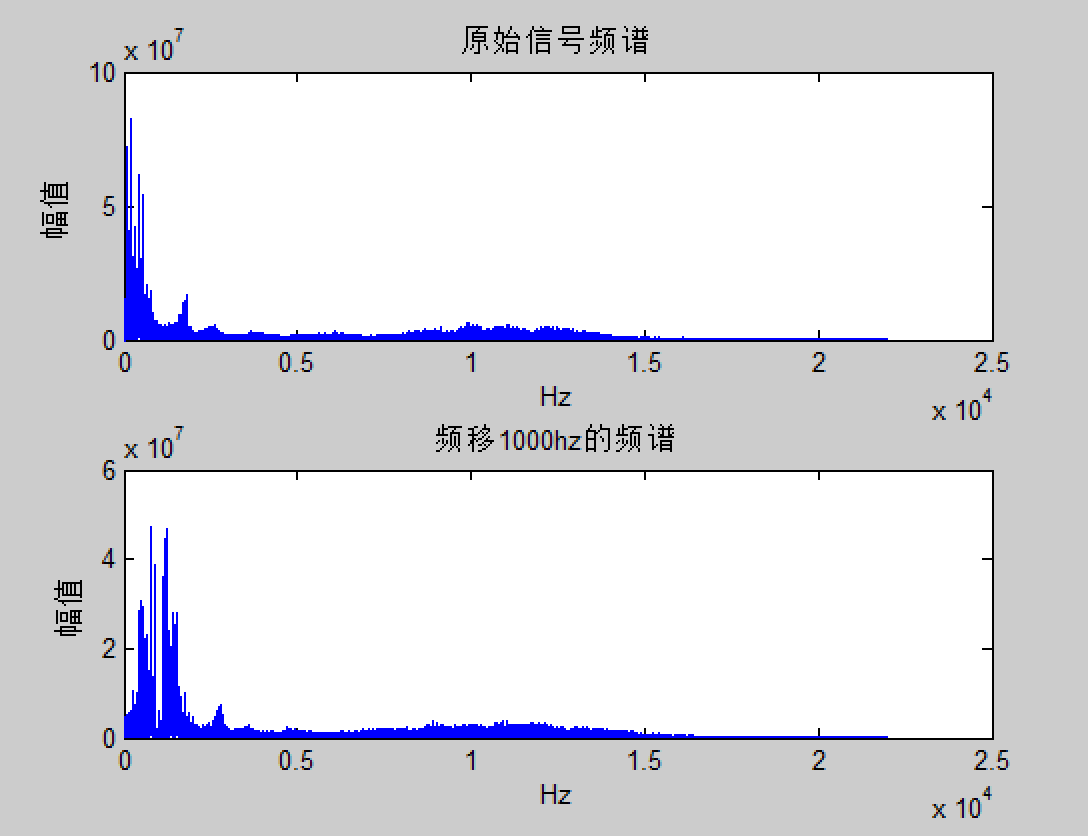
原始信号的频谱从0频开始?频率1000Hz后,虑除的就是小于1000hz的频率?实际在我的程序中对频谱只进行了200hz的搬移,那选一个大于200hz的IIR高通滤波器?
3)用matlab设计滤波器,并得到滤波器参数.我用matlab的fdatool工具设计了一个5阶的IIR高通滤波器,截止频率为200hz。导出参数,用[Bb,Ba]=sos2tf(SOS,G);得出滤波器参数。
4)得到的Bb和Ba参数后,可以直接代入输入输出的差分方程得出滤波器的输出y(n)
音频输入输出回调函数处理
1)输入回调
OSStatus inputRenderTone(
void *inRefCon,
AudioUnitRenderActionFlags *ioActionFlags,
const AudioTimeStamp *inTimeStamp,
UInt32 inBusNumber,
UInt32 inNumberFrames,
AudioBufferList *ioData)
{
ViewController *THIS=(__bridge ViewController*)inRefCon;
AudioBufferList bufferList;
bufferList.mNumberBuffers = 1;
bufferList.mBuffers[0].mData = NULL;
bufferList.mBuffers[0].mDataByteSize = 0;
OSStatus status = AudioUnitRender(THIS->_toneUnit,
ioActionFlags,
inTimeStamp,
kInputBus,
inNumberFrames,
&bufferList);
SInt16 *rece = (SInt16 *)bufferList.mBuffers[0].mData;
for (int i = 0; i < inNumberFrames; i++) {
rece[i] = rece[i]*THIS->_convertCos[i];//频谱搬移
}
RawData *rawData = &THIS->_rawData;
//距离最大位置还有mDataByteSize/2 那就直接memcpy,否则要一个一个字节拷贝
if((rawData->rear+bufferList.mBuffers[0].mDataByteSize/2) <= kRawDataLen){
memcpy((uint8_t *)&(rawData->receiveRawData[rawData->rear]), bufferList.mBuffers[0].mData, bufferList.mBuffers[0].mDataByteSize);
rawData->rear = (rawData->rear+bufferList.mBuffers[0].mDataByteSize/2);
}else{
uint8_t *pIOdata = (uint8_t *)bufferList.mBuffers[0].mData;
for (int i = 0; i < rawData->rear+bufferList.mBuffers[0].mDataByteSize; i+=2) {
SInt16 data = pIOdata[i] | pIOdata[i+1]<<8;
rawData->receiveRawData[rawData->rear] = data;
rawData->rear = (rawData->rear+1)%kRawDataLen;
}
}
return status;
}
在频移的处理时,本来要对频移后的序列滤波的,但是滤波后,全部是杂音,所以删除掉了这部分代码,在提供的完整代码中有这部分删除掉的代码。存储数据中循环队列来存。
2)输出回调
OSStatus outputRenderTone(
void *inRefCon,
AudioUnitRenderActionFlags *ioActionFlags,
const AudioTimeStamp *inTimeStamp,
UInt32 inBusNumber,
UInt32 inNumberFrames,
AudioBufferList *ioData)
{
ViewController *THIS=(__bridge ViewController*)inRefCon;
SInt16 *outSamplesChannelLeft = (SInt16 *)ioData->mBuffers[0].mData;
RawData *rawData = &THIS->_rawData;
for (UInt32 frameNumber = 0; frameNumber < inNumberFrames; ++frameNumber) {
if (rawData->front != rawData->rear) {
outSamplesChannelLeft[frameNumber] = (rawData->receiveRawData[rawData->front]);
rawData->front = (rawData->front+1)%kRawDataLen;
}
}
return 0;
}
以上实现了对音频的实时录入变声后实时输出。没有滤波,听起来声音有点怪。😂😂😂大学的时候学的数字信号处理已经还给老师,关于信号处理这部分还请知道的小伙伴指点指点,想实现男女声音转化的效果。
