标签: Python
引言:(文章比较长,建议看目录按需学习~)
以前刚学编程的时候就对Python略有耳闻,不过学校只有C,C++,Java,C#。
和PHP有句"PHP是最好的语言" 这种家喻户晓的骚话一样,Python也有
"人生苦短,我用Python"。而接触Python这个词最多的场合就是在一些技术群里,
有些大佬张嘴动不动就说什么Py交易,作为潜伏在群里的开发萌新的我每次都
会忍不住会发出这样的感慨:

而真正接触了下Python是在上家公司,当时老大让我写个脚本去下载
仓库里最近打包的apk,当时东凑凑西凑凑最后总算拼成了一个可运行
的py文件,因为不了解Python里的数据结构,全部用的字符串变量,
后面被老大教育了一番才知道有元组这种东西。因为本身做Android的,
Python用到的场合不多,加之觉得Kotlin有点意思,就没去研究Python了。
前段时间,手头的事做得差不多了,无聊四处张望时,看到隔壁后台
小哥迅雷疯狂下载东西,建文件夹,粘贴复制,不知道还以为他在给
小电影分类呢,后来一问才知道,运营让他把服务器上所有的音频
文件下下来,然后根据对应的类别下到对应文件夹,所以他做的事情
就是:迅雷批量下载过歌曲 -> 看mysql歌曲的分组 -> 建文件夹
-> 粘贴复制歌曲到这个文件夹下,咋一看,流程挺简单的,然而有
4700多首歌,几百个目录,这样慢慢搞怕是要搞几天,而且常时间
机械化的重复某项工作,很容易出错。看着一脸绝望的后台小哥:

于心不忍,决定写个py脚本来拯救他,脑子里也有了程序的大概逻辑:
- 1.让后台导出一份mysql建表语句,安装mysql把表建起来;
- 2.Python连mysql,读取表里的数据
- 3.编写带limit去重的sql查询语句,查询得到所有分类
- 4.得到的所有分类就是要创建的文件夹,迭代批量创建文件夹;
- 5.sql查询歌曲下载url与分类,拼接,写入到文件中;
- 6.读取文件,迭代:下载url截取文件名与分类路径拼接成文件
的完整路径,调用下载相关函数下载url到对应路径即可。
逻辑挺简单明了的,然而各种坑,最后折腾了一天才能弄出来
遇到了下面这些问题:
- 1.最坑的解码问题:默认使用Python2,中文乱码,各种网上搜,
设置编码方式,都没用,头皮发麻,特别是在截取文件名的时候。
后面换了一波Python3,很舒服,什么问题都没了。 - 2.没有对异常进行捕获,有些资源失效404,下到中途才发现.;
- 3.想弄多线程下载的,因为Python很多基础不知道,后面放弃了;
当看到所有文件都下载到了对应的位置,一种油然而生的成就感,
比起写APP天天画界面,请求,解析数据,显示数据,有意思太多,
毕竟学习开发兴趣很重要,索性从零开始学习下Python吧,越学越觉得:

理由上班时的闲暇时间,历时两周总算是把基础知识的东西过了
一遍,遂有此文,毕竟初学者,有些地方可能理解有误,望看到
的大佬不吝赐教,文中大部分内容摘自:
《Python 3 教程》与《小甲鱼的零基础入门学习Python》
有兴趣的可以阅读下这两本书~
本文不是入门教程啊,完全没有编程经验的不建议阅读!
完全小白可以看下这本:《编程小白的第一本Python入门书》
目录
[TOC]
1.学习资源相关
API文档
- 官网:http://www.python.org/
- API:https://docs.python.org/release/3.6.3/
- 中文API(3.5.2):http://python.usyiyi.cn/translate/python_352/index.html
- awesome-python:https://github.com/vinta/awesome-python
- awesome-python(翻译):https://github.com/jobbole/awesome-python-cn
书籍
- 《Python 3 教程》:http://www.runoob.com/python3/python3-tutorial.html
- 《老齐零基础学Python》:https://www.gitbook.com/book/looly/python-basic/details
- 《小甲鱼的零基础入门学习Python》:很不错的一本入门书籍,我就是看这本~
- 《Python核心编程(第3版)》:也是挺有名的一本书,还没看~
2.学习Python2还是Python3的问题
!!!Python 3的语法 不完全兼容 Python 2的语法!!!
菜逼刚学Python没多久,不敢大声哔哔,最直接原因:
Python 3默认使用utf-8,在处理中文的时候可以
减少很多编解码的问题,而Python 2默认使用ascii。
另外的原因:与时俱进,IT行业发展那么迅速,完全过渡只是时间问题;
举个例子:Android Studio刚出的没多久的时候,各种说卡啊,垃圾,
只能开一个项目等各种嫌弃,不如Eclipse好用;然而现在开发Android
还是用Eclipse的都是会被歧视一波的,So:人生苦短,我用Python3。
更多比较的文章可见:
Python2.x与3.x版本区别
Python2orPython3
Python3.x和Python2.x的区别
3.开发环境搭建
Python下载安装
官网下载:https://www.python.org/downloads/,
自己选择需要的版本与操作系统。
- Windows
傻瓜式下一步就好,记得勾选Add Python x.x to Path!勾选
了你装完就不用自己去配置环境变量,安装完毕后打开CMD输入:
python3 -V 能查看到安装的Python版本说明安装成功,
如果提示错误:python3不是内部或外部命令之类的话,恭喜你
可以百度下:Python3环境变量配置 了~
- Mac
方法一:官网下安装包,傻瓜下一步;
方法二:如果有装Homebrew,终端输入:brew install Python3 安装即可。
-
Ubuntu:一般内置,执行下述命令可查看版本,如果想安装自己喜欢
的版本可以键入:sudo apt-get install python版本号 进行安装
PyCharm下载安装
其实在安装完Python后就可以进行Python编程了,直接命令行输入python3,
就可以使用自带的IDLE进行开发了;又或者直接用Sublime Text或NotePad++
这类代码查看工具直接编写代码,然后保存成后缀为.py的文件,然后python3
执行这个py文件就可以了。
虽然可以,但是挺不方便的,比如缩进问题,Python通过缩进来表示代码块,
代码一多,某一行没有正确的使用缩进,结果可能与你预期的相差甚远。
智能提示,方便的依赖库管理等,这两个就不用说了吧,具体的还得你自己体会。
官网下载:https://www.jetbrains.com/pycharm/download/
下载Professional版本,傻瓜式安装,打开后会弹出注册页面,
勾选License server,在License server address输入注册服务器,
网上搜很多,然后就可以愉快的进行py开发了。
软件的基本使用也非常简单,Jetbrains的IDE都是差不多的~
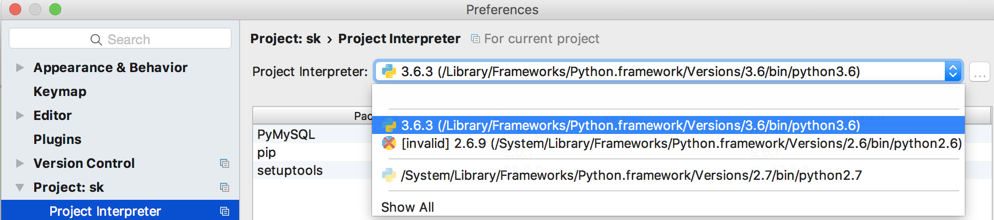
有一点要注意的地方是,如果你想切换项目依赖的Python版本号的话:
打开设置(Preference或settings),修改即可:
4.基本常识
1) 导包
有时项目中需要引入其他模块或者模块中的某个函数,需要用到import和
from...import,用法示例如下:
import sys # 导入整个模块
from sys import argv # 导入模块中的需要用到的部分
from urllib.error import URLError, HTTPError # 多个的时候可以用逗号隔开
from sys import * # 导出模块中的所有
# 另外还可以使用as关键字为模块设置别名,比如 import sys as s
# 调用的时候直接s.argv 这样就可以了。
2) 关键字与标识符命名规则
在对变量或者方法名这些标识符进行命名的时候,需要注意,不能够
与Python中的关键字相同,通过keyword.kwlist可以查询所有的关键字:
需要import keyword模块哦~

除了不能与与关键字相同外,标识符的命名规则:
由字母,数字和下划线组成,且首字符必须为字母或下划线,
Python对大小写敏感;关于命名规范的问题,没有什么
强制规定,整个项目保持统一就好,附上网上找的一个命名规则:
- 1.项目名:首字母大写,其余小写,用下划线增加可读性,如:Ui_test;
- 2.包名与模块名:全部小写字母;
- 3.类名:首字母大写,其余小写,多个单词驼峰命名法;
- 4.方法(函数)名:全部小写,多个单词用下划线分隔;
- 5.参数名:小写单词,如果与关键词冲突,参数名前加上下划线,比如_print;
- 6.变量:小写,多个单词用下划线分隔;
- 7.常量:全部大写,多个单词用下划线分隔;
3) 注释
Python 使用 # 来进行单行注释,多行注释的话使用三引号,比如:
'''
这是
Python的
多行注释
'''
4) print打印输出与input输入函数
学习一门新的编程语言,第一个程序基本都是打印Hello world,
把结果打印到屏幕上,是验证代码执行结果的最直观体现,所以
有必要先学一波 print 和 input 的用法!
print():
- 1.可以输出各种乱七八糟类型的数据直接转成字符串打印输出;
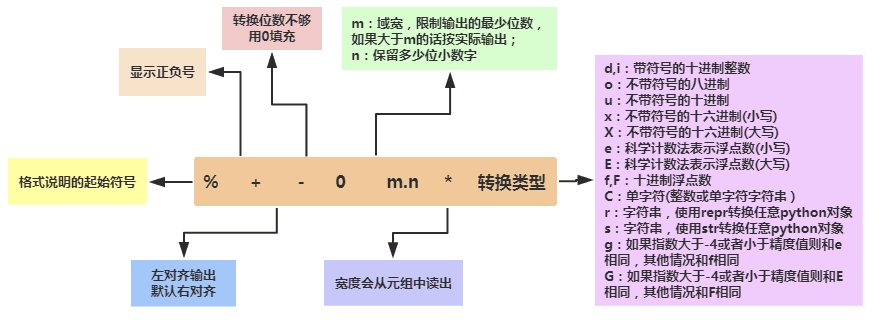
- 2.print默认会换行,如果不换行可以: print(xxx, end = "")
- 3.支持
格式化输出,和C中的printf用法类似,逗号分隔前后改成%:
input():
从键盘读入一个字符串,并自动忽略换行符,所有形式的输入按字符串处理。
可以在括号里写一些输入的提示信息,比如: input("请输入一个字符串:")


5) help函数
这个就不用说了,很多编程语言都有的,可以用来查看某个 内置函数(BIF)
的相关用法的,比如help(print),会输出这样的结果:

6) dir函数
查看对象内所有属性与方法,只需要把要查询的对象添加到括号中即可,
比如定义一个类,然后用dir可以获取所有的属性与方法:

7) 查看所有内置函数(BIF)
执行:print(dir(sys.modules['builtins'])) 可以打印出所有的内置函数。
8) 多个语句一行与一个语句多行
如果你想把多个语句写到一行,可以使用; (分号)分隔;
有时语句可能太长,你可以使用\ (反斜杠)来衔接,
而在[] , {} , ()里的不需要使用反斜杠来衔接。
5.数据类型
1) 变量
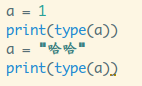
Python3里定义一个变量非常简单粗暴,直接一个 变量名 = 初值
赋值时就决定了变量的数据类型,变量名引用了数值的同时也引用
它的类型,如果不理解的话,看下例子就知道了,type可以查看
变量的数据类型(另外还要注意Python对大小写敏感,区分大小写!):
另外Python中支持多个变量赋值,以下这两种赋值写法是正确的:
a = b = c = 1
a,b,c = 1,2,"Python"
对了,你还可以使用del关键字删除对象的引用,但删除后再调用
变量是会报错的!


2) 数字(Mumber)
Python3中支持四种数字类型:int,float,complex(复数)
注:Python3中 int 不区分整形与长整形,整数的长度不受限制,
所以很容易进行大数计算。而除了十进制外的进制表示如下:
二进制0b,八进制0o,十六进制0x 开头。
Python支持复数直接表示法,就是(a+bj)的形式,complex类的实例,
可以直接运算,比如:a = 1 + 2j + 3 * 4j,输出a,结果是:(1+14j)
实数+虚数,除了a+bj,还可以用complex(a,b)表示,两个都是
浮点型,可以调用.real获得实部,.imag 获得虚部,abs()求复数
的模(√(a^2 + b^2))。
数字类型转换:(Python文档中,方括号[]括起来表示为可选)
| 函数 | 作用 |
|---|---|
| int(x[,base]) | 将x转换为一个整数,第二个参数是指定前面字符串的进制类型 |
| float(x) | 将x转换到一个浮点数 |
| complex(real [,imag]) | 创建一个复数 |
| str(x) | 将对象x转换为字符串 |
| repr(x) | 将对象x转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s) | 将序列s转换为一个元组 |
| list(s) | 将序列s转换为一个列表 |
| chr(x) | 将一个整数转换为一个字符 |
| unichr(x) | 将一个整数转换为Unicode字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
| bin(x) | 将一个整数转换为一个二进制字符串 |
数学函数:
| 函数 | 作用 |
|---|---|
| abs(x) | 返回数字的绝对值,如abs(-10) 返回 10 |
| ceil(x) | 返回数字的上入整数,如math.ceil(4.1) 返回 5 |
| cmp(x, y) | 如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1 |
| exp(x) | 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045 |
| fabs(x) | 返回数字的绝对值,如math.fabs(-10) 返回10.0 |
| floor(x) | 返回数字的下舍整数,如math.floor(4.9)返回 4 |
| log(x) | 如math.log(math.e)返回1.0,math.log(100,10)返回2.0 |
| log10(x) | 返回以10为基数的x的对数,如math.log10(100)返回 2.0 |
| max(x1, x2,...) | 返回给定参数的最大值,参数可以为序列。 |
| min(x1, x2,...) | 返回给定参数的最小值,参数可以为序列。 |
| modf(x) | 返回x的整数部分与小数部分,两部分的数值符号与x相同, 整数部分以浮点型表示。 |
| pow(x, y) | x的y次方 |
| round(x [,n]) | 返回浮点数x的四舍五入值,如给出n值,则代表舍入到 小数点后的位数。 |
| sqrt(x) | 返回数字x的平方根,数字可以为负数,返回类型为实数, 如math.sqrt(4)返回 2+0j |
3) 布尔类型(Bool)
用True和False来表示真假,也可以当做整数来对待,True为1,
False为0,但是不建议用来参与运算!
4) 列表(List)
类似于数组,有序,内容长度可变,使用中括号[]表示,元素间用逗号分隔,
元素的数据类型可以不一样!用法示例如下(dir(list)可以查看所有的属性与方法j):
(Tip:列表可嵌套,如果想访问列表中的列表中的某个值可以写多个[],比如:list1[1][2])
list1 = [1,2.0,"a",True] # 定义列表
print(list1[1]) # 通过[下标]访问元素,从0开始,结果输出:2.0
print(list1[1:3]) # 支持截取,比如这里的[1:3],结果输出:[2.0, 'a']
print(list1[1:3:2]) # 还可以有第三个参数,步长,默认为1,结果输出:[2.0]
print(list1[2:]) # 输出结果:['a', True]
print(list1[-2]) # 负数的话从后面开始访问,结果输出:a
print(list1.index("a")) # 返回参数在列表中的位置,结果输出:2
# 修改列表元素
list1[1] = 3.0 # 直接获得元素后进行修改,此时列表元素:[1, 3.0, 'a', True]
# 添加元素
list1.append('Jay') # 追加一个元素,此时列表元素:[1, 2.0, 'a', True, 'Jay']
list1.insert(2,'pig') # 插入一个元素,此时列表元素:[1, 2.0, 'pig', 'a', True]
print(list1.pop()) # 移除最后一个元素,并返回元素的值,结果输出:True
# 删除元素
del list1[0] # 删除索引位置的值,此时列表元素:[2.0, 'a', True]
list1.remove('a') # 删除指定的元素值,此时列表元素:[1, 2.0, True]
# 其他(使用+号可以组合列表,*号可以重复列表)
print(list1+list1) # 输出结果:[1, 2.0, 'a', True, 1, 2.0, 'a', True]
print(list1*2) # 输出结果:[1, 2.0, 'a', True, 1, 2.0, 'a', True]
print('a' in list1) # 判断列表中是否有此元素,输出结果:True
print('b' not in list1) # 判断原始中是不是没有这个元素,输出结果:True
for x in list: # 迭代遍历列表
print(len(list1)) # 获得列表长度,结果输出:4
print(list1.count(1)) # 统计某个元素在列表中出现的次数,结果输出:2,因为True的值也是1
max(list1) # 获得列表中的元素最大值,列表元素类型需要为数字
min(list1) # 获得列表中的元素最小值,列表元素类型需要为数字
list1.sort() # 对原列表元素进行排序,本地排序(会修改值),返回None,
# 只能比较数字!默认从小到大,从大到小可以用可选参数,括号里加上:
# key = lambda x:-1*x
list1.reverse() # 反转列表元素,会修改列表,返回None
list2 = list1.copy() # 拷贝列表,重新开辟了内存空间!和等号赋值不一样!
list(tuple) # 将元组或字符串转换为列表
5) 元组(tuple)
受限的列表,元组中的元素不能修改,使用小括号()表示。
有一点要注意的是:当元组中只有一个元素,需要在元素后添加逗号,
否则会当做括号运算符使用!元组可以当做不能修改的参数传递给函数,
而且元组所占用的内存较小。使用的话,除了没有修改元组元素的方法外,
其他的和列表的方法基本一致。
另外元组中的元素不能删除,但是可以使用del语句来删除整个元组,
不过比较少用,因为Python回收机制会在这个元组不再被使用时自动删除
(和Java的gc有点像~) 还可以使用tuple(list)将字符串或列表转换为元组。


6) 字典(dict)
和列表,元组通过下标序列来索引元素不同,字典使用键值对的形式来存储
数据,通过键来索引值,创建字典时,键不能重复,重复后面的会覆盖!
因为键必须不可变,所以键可用数字,字符串或元组,但是不能用列表!
使用冒号:分割键与值,多个键值对用逗号,分隔;字典也是支持嵌套的!
用法示例如下:
dict1 = {} # 定义一个空字典
dict2 = {'a': 1, 'b': 2, 3: "c"} # 定义一个普通字典
dict4 = dict2.copy() # 浅复制一个字典
# 可以使用fromkeys创建并返回新的字典,有两个参数,键和键对应的值
# 值可以不提供,默认None,不过有个小细节要注意,下面的例子输出
# 的结果是:{1: ['a', 'b', 'c'], 2: ['a', 'b', 'c'], 3: ['a', 'b', 'c']}
list1 = [1, 2, 3]
list2 = ['a', 'b', 'c']
dict3 = {}
dict3 = dict3.fromkeys(list1, list2)
print(dict3)
# 通过键查询对应的值,如果没有这个键会报错TypeError,这里输出结果:2
print(dict2['b'])
print(dict2.get("d")) # 通过get()方法查询键对应的值,没有的话会返回None
# 还可以加上一个默认的返回参数get(x,y)
print(dict2.setdefault("d")) # 和get()类似,如果找不到键的话会自动添加 键:None
print("d" in dict2) # 字典中是否有此键,这里输出结果:False
print("d" not in dict2) # 字典中是否没有此键,这里输出结果:True
print(dict2.keys()) # 返回字典中所有的键,这里输出结果:dict_keys(['a', 3, 'b'])
print(dict2.values()) # 返回字典中所有的值,这里输出结果:dict_values([1, 'c', 2])
print(dict2.items()) # 返回字典中所有的键值对,这里输出结果:
# dict_items([('a', 1), (3, 'c'), ('b', 2)])
# 修改键对应的值,此时字典元素:{3: 'c', 'a': 1, 'b': 'HaHa'}
dict2['b'] = 'HaHa'
dict2.update(b:'Pig') # 使用update方法可以更新键对应的值,不过键需要为字符串!
# 删除字典元素
del(dict2['b']) # 删除某个键值对,此时字典元素:{3: 'c', 'a': 1}
dict2.clear() # 移除字典中所有的键值对,此时剩下空字典:{}
del dict2 # 删除整个字典,删除后无法再重复引用!!!
print(dict2.pop('a')) # 根据键删除对应的值,返回被删除的值。
print(dict2.popitem()) # 删除一个项,随机,比如:('b', 2)
# 遍历字典:
for d in dict2:
print("%s:%s" % (d, dict2.get(d)))
for (k,v) in dict2.items():
print("%s:%s" % (k, v))
7) 集合(set)
集合中的存储的元素无序且不重复,所以你无法去索引某个具体的元素;
使用大括号{}包裹元素,逗号分隔,如果有重复的元素会被自动剔除!
另外有一点要注意的是,如果是创建空集合必须使用set(),而不能用{},
通过上面我们也知道了{}的话是直接创建一个空字典!
用法示例如下:
set1 = set() # 创建空集合
set2 = {1, 2, 3, 4, 5, 1} # 普通方式创建集合
print(set2) # 重复元素会被自动删除,输出结果:{1, 2, 3, 4, 5}
set3 = set('12345') # 字符串
print(set3) # 输出:{'2', '5', '3', '4', '1'},集合元素无序
print(6 in set2) # 判断集合中是否有此元素:输出结果:False
print(6 not in set2) # 判断集合中是否有此元素:输出结果:True
set2.add("6") # 添加元素
print(set2) # 输出结果:{1, 2, 3, 4, 5, '6'}
set2.remove(2) # 删除元素,如果删除的元素不存在会报错
print(set2) # 输出结果:{1, 3, 4, 5, '6'}
# 遍历集合,输出结果: 1 3 4 5 6
for data in set2:
print(data, end="\t")
# 使用frozenset()函数定义不可变集合
set4 = frozenset({1, 2, 3, 4, 5})
8) 字符串
Python里对处理字符串可是日常,熟练掌握字符串的处理非常重要。
可以使用单引号('')或者双引号("")来修饰字符串,
如果想让字符串包含换行缩进等格式时,可以使用三括号('''''')
来修饰,一般要打印段落文字的时候可以用这个。
另外,字符串定义后就不能修改元素了,比如下面str1[0] = 'x'是会报错的,
只能通过+,*,分片等方式进行拼接,间接得到相同的字符串内容,不过却不是原来
的字符了,变量指向了新的字符串,而旧的会被py的回收机制回收掉!
访问字符串:
str1 = "Hello Python"
print(str1[3]) # 输出结果:l
print(str1[2:]) # 输出结果:llo Python
print(str1[2:5]) # 输出结果:llo
print(str1[2:10:2]) # 输出结果:loPt
print(str1[0:8] + str1[8:]) # 输出结果:Hello Python
str2 = str1[6:] * 3
print(str2) # 输出结果:PythonPythonPython
转义字符:
| 转义字符 | 作用 | 转义字符 | 作用 | 转义字符 | 作用 |
|---|---|---|---|---|---|
行尾的\
|
续行符 | \\ |
反斜杠 | \' |
单引号 |
\a |
响铃 | \b |
退格 | \e |
转义 |
\000 |
空 | \n |
换行 | \v |
纵向制表符 |
\t |
横向制表符 | \r |
回车 | \f |
换页 |
\o |
八进制数代表字符 | \x |
十六进制数代表字符 |
各种内置方法:
| 方法名 | 作用 |
|---|---|
| capitalize() | 把字符串的第一个字符改为大写 |
| casefold() | 把整个字符串的所有字符改为小写 |
| center(width) | 将字符串居中,并使用空格填充至长度width的新字符串 |
| count(sub[,start[,end]]) | 返同sub在字符申里边出现的次数, start和end参数表示范围,可选 |
| encode(encoding= 'utf-8 ',errors='strict') | 以encoding指定的编码格式对字符串进行编码 |
| endswith(sub[,start[,end]]) | 检查字符串是否以sub 子字符串结束,如果是返回True, 否则返回False。start和end参数表示范围,可选 |
| expandtabs([tabsize= 8]) | 把字符串中的tab符号(\t)转换为空格,如不指定参数, 默认的空格数是tabsize=8 |
| find(sub[,start[,end]]) | 检测sub是否包含在字符串中,如果有则返回索引值, 否则返回-1,start和end参数表示范围,可选 |
| index(sub[,start[,end]]) | 跟find方法一样,不过如果sub不在string中会产生一个异常 |
| isalnum() | 如果字符串中至少有一个字符,并且所有字符都是 字母或数字则返回True,否则返回False |
| isalpha() | 如果字符串至少有一个字符串,并且所有字符都是 字母则返回True,否则返回False |
| isdecimal() | 如果字符串只包含十进制数字则返回True,否则返回False |
| isdigit() | 如果字符串只包含数字则返回True,否则返回False |
| islower() | 如果字符串中至少包含一个区分大小写的字符,并且这些字符 都是小写,则返回True,否则返回False |
| isnumeric() | 如果字符串中只包含数字字符,则返回True,否则返回False |
| isspace() | 如果字符串中只包含空格,则返回True,否则返回False |
| istitle() | 如果字符串是标题化(所有单词大写开头,其余小写), 则返回True,否则返回False |
| isupper() | 如果字符串中至少包含一个区分大小写的字符,并且这些 字符都是大写,则返回True,否则返回False |
| join(sub) | 以字符串作为分隔符,插入到sub中所有的字符之间,使用+去拼接大量 字符串的时候是很低效率的,因为加号拼接会引起内存赋值一级垃圾回收 操作,此时用join来拼接效率会高一些,比如: ''.join(['Hello','Python']) |
| ljust(width) | 返回一个左对齐的字符串,并使用空格填充至长度为width的新字符串 |
| lower() | 转换字符串所有大写字符为小写 |
| lstrip() | 去除字符串左边的所有空格 |
| partition(sub) | 找到子字符串sub,把字符串分割成3元组(前,pre,后) 如果字符串中不包含则返回('原字符串','','') |
| replace(old, new[,count]) | 把字符串中的old子字符串替换成new,如果count指定, 则替换次数不超过count次 |
| rfind(sub[,start[,end]]) | 和find()方法类似,不过是从右开始查找 |
| rindex(sub[,start[,end]]) | 和index()方法类似,不过是从右开始查找 |
| rjust(width) | 返回一个右对齐的字符串,并使用空格填充至长度为width的新字符串 |
| rpartition(sub) | 类似于partition(),不过是从右边开始查找 |
| rstrip() | 删除字符串末尾的空格 |
| split(sep=None,maxsplit=-1) | 不带参数默认是以空格为分隔符切片字符串,如果maxspli参数t 右设置,则仅分隔maxsplit个子字符串,返回切片后的子字符串拼接的列表 |
| splitlines([keepends]) | 按照'\n'分隔,返回一个包含各行作为元素的列表,如果keepends参数 指定,则返回前keepends行 |
| startswith(prefix[,start[,end]]) | 检查字符串是否以prefix开头,是则返回True,否则返回False。 start和end参数可以指定范围检查,可选 |
| strip([chars]) | 删除字符串前边和后边所有的空格,chars参数可定制删除的字符串,可选 |
| swapcase() | 反转字符串中的大小写 |
| title() | 返回标题化(所有的单词都是以大写开始,其余字母小写)的字符串 |
| translate(table) | 按照table的规则(可由str.maketrans('a','b')定制)转换字符串中的字符 |
| upper() | 转换字符串中所有的小写字符为大写 |
| zfill(width) | 返回长度为width的字符串,原字符串右对齐,前边用0填充 |
字符串格式化:
其实就是format方法的使用而已,示例如下:
# 位置参数
str1 = "{0}生{1},{2}{3}!".format("人","苦短","我用","Python")
print(str1) # 输出结果:人生苦短,我用Python!
# 关键字参数
str1 = "{a}生{c},{b}{d}!".format(a = "人", c = "苦短",b = "我用",d = "Python")
print(str1) # 输出结果:人生苦短,我用Python!
# 位置参数可以与关键字参数一起使用,不过位置参数需要在关键字参数前,否则会报错!
# 另外还有个叫替换域的东西,冒号代表格式化符号开始,比如下面的例子:
str1 = "{0}:{1:.4}".format("圆周率", 3.1415926)
print(str1) # 输出结果:圆周率:3.142
格式化操作符:%,这个就不说了,和上面print()那里的一致!
9) 运算符
算术操作符:(+ - * / % **(幂,次方) //(地板除法,舍弃小数))
print("3 + 7 = %d" % (3 + 7)) # 输出结果: 3 + 7 = 10
print("3 - 7 = %d" % (3 - 7)) # 输出结果: 3 - 7 = -4
print("3 * 7 = %d" % (3 * 7)) # 输出结果: 3 * 7 = 21
print("7 / 3 = %f" % (7 / 3)) # 输出结果: 7 / 3 = 2.333333
print("7 %% 3 = %d" % (7 % 3)) # 输出结果: 7 % 3 = 1
print("3 ** 6 = %d" % (7 ** 3)) # 输出结果: 3 ** 6 = 343
print("3 // 6 = %f" % (7 // 3)) # 输出结果: 3 // 6 = 2.000000
比较运算符:(== != > < >= <=)
赋值运算符:(== += -= *= /= %= **= //=)
位运算符:(&(按位与) |(按位或) ^(异或,不同为1) ~(取反) << >>)
逻辑运算符:(and or not)
成员运算符:(in not in)
身份运算符(判断是否引用同一个对象):(is is not)
运算符优先级:
**(指数) > ~ + -(取反,正负号) > * / % //(乘除,求余,地板除) > << >>(左右移)
> &(按位与) > ^ |(异或,按位或) > < <= > >=(比较运算符) > 等于运算符 > 赋值运算符
> 身份运算符 > 成员运算符 > 逻辑运算符
10) 日期时间
日期时间并不属于数据结构,只是觉得很常用,索性也在这里把用法mark下~
以来的两个模块是:time 和 datetime,详细用法示例如下:
import time, datetime
# 获取当前时间
moment = time.localtime()
print("年:%s" % moment[0])
print("月:%s" % moment[1])
print("日:%s" % moment[2])
print("时:%s" % moment[3])
print("分:%s" % moment[4])
print("秒:%s" % (moment[5] + 1))
print("周几:%s" % (moment[6] + 1))
print("一年第几天:%s" % moment[7])
print("是否为夏令时:%s" % moment[8])
# 格式化时间(这里要注意strftime和strptime是不一样的!!!)
moment1 = time.strftime('%Y-%m-%d %H:%M:%S')
moment2 = time.strftime('%a %b %d %H:%M:%S %Y', time.localtime())
moment3 = time.mktime(time.strptime(moment2, '%a %b %d %H:%M:%S %Y'))
print(moment1) # 输出结果:2017-12-02 11:08:02
print(moment2) # 输出结果:Sat Dec 02 11:08:02 2017
print(moment3) # 输出结果:1512184082.0 日期转换为时间戳
# 获得当前时间戳
print(time.time()) # 输出结果:1512185208.0942981
# 获得当前时间(时间数组,还需strftime格式化下)
print(datetime.datetime.now()) # 输出结果:2017-12-02 11:34:44.726843
# 时间戳转换为时间
# 方法一:(输出结果:2017-12-02 11:08:02)
moment4 = 1512184082
moment5 = time.localtime(moment4) # 转换成时间数组
print(time.strftime('%Y-%m-%d %H:%M:%S', moment5)) # 格式化
# 方法二:
moment6 = datetime.datetime.utcfromtimestamp(moment4)
print(moment6) # 直接输出:2017-12-02 03:08:02
moment7 = moment6.strftime('%a %b %d %H:%M:%S %Y')
print(moment7) # 格式化后输出:Sat Dec 02 03:08:02 2017
# 延迟执行
time.sleep(秒)
6.流程控制
1) if条件判断
python中没有switch-case,另外使用了 elif 代替了else if
每个条件后需要跟一个冒号(:),通过缩放来划分代码块,
嵌套的时候要注意!使用示例如下:


另外,如果条件成立,你又不想做任何事情,可以直接使用pass空语句
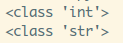
2) while循环
python中没有do-while,同样要注意冒号和缩放!
可以搭配else使用,还有无限循环这种东西:while True:
使用下面的break关键字可以跳出循环。
使用示例如下:

3) for循环
和C或者Java那种for循环不同,并不能直接写 for(int a = 0;a < 100;a++)
使用示例如下:

输出结果:

4) break,continue,else
break跳出循环;continue跳过余下操作直接进入下一次循环;
else也可以使用在循环,for循环条件不成立时执行,如果先break的话不会执行!
5) 条件表达式(简化版的if-else)
a = x if 条件 else y
6) 断言
当assert关键字后面的判断条件为假的时候,程序自动崩溃并抛出AssertionErro异常,
一般在测试程序的时候才会用到,要确保某个条件为真程序才能正常工作的时候使用~
7) 迭代器与生成器
迭代器:用于访问集合,是一种可以记住遍历位置的对象,会从第一个元素
开始访问,直到结束,两个基本的方法:iter()和next()

输出结果:

生成器
应该叫生成器函数吧,一种特别的函数,用yield来返回值,
调用时会返回一个生成器对象,本质上还是迭代器,只是更加简洁,
yield对应的值在函数调用的时候不会立即返回,只有去调用next()
方法的时候才会返回,使用for x in xxx的时候其实调用的还是next()方法,
最简单的使用示例如下:


如果你用type()方法查下,会发现返回的对象类型是:<class 'generator'>
相比起迭代器,生成器更加简洁优雅,最经典的例子就是实现斐波那契数列:
def func(n):
a, b = 0, 1
while n > 0:
n -= 1
yield b
a, b = b, a + b
for i in func(10):
print(i, end="\t")
# 输出结果:1 1 2 3 5 8 13 21 34 55
7.函数
对于一些重复使用的代码块,我们可以把他抽取出来写成一个函数。
1) 函数定义
使用 def关键字 修饰,后接函数名与圆括号(传入参数),
使用 return关键字 返回值,不写的话默认返回 None值,
Python可以动态确定函数类型,返回不同的类型的值,可以利用
列表打包多种类型的值一次性返回,也可以直接用元组返回多个值;
另外函数参数如果有多个的话,可以用逗号隔开。
还有一个建议是:在函数第一行语句可以选择性地使用文档字符串用于存放
函数说明,直接用三引号注释包括即可,通过help方法可以拿到!
2) 形参与实参
定义函数时的参数是形参,调用时传入的是实参;
3) 关键字参数
参数有多个的时候,怕参数混淆传错,可以在传入的时候
指定形参的参数名,比如: show(a = "a", b = "b")这样。
4) 默认参数
定义的形参时候赋予默认初值,调用时就可以不带
参数去调用函数,比如:def sub(a = "1", b = "2"),调用时直接
什么都传sub()或者传入一个参数sub(3)都可以,还可以配合
关键字参数指定传入的是哪个参数。
5) 可变参数
有时传入的函数参数数目可能是不固定的,比如,要你
计算一组值的和,具体有多少个数字不知道,此时就可以用可变参数了。
只需要在参数前加上*号(其实是把数据打包成了元组),就代表这个
参数是可变参数;如果有多个参数,写在可变参数后的参数要用
关键字参数指定,否则会加入可变参数的范畴!!!有打包自然有
解包,如果想把列表或元组当做可变参数传入,需要在传入的时候
在实参前加上*号!另外,如果想把参数打包成元组的方式的话,
可以使用两个星号(**)修饰~
6) 全局变量与局部变量
全局变量就是定义为在最外部的,可以在函数内部进行访问但不能直接修改;
局部变量就是定义在函数内部的,而在函数外部无法访问的参数或变量;
局部变量无法在外部访问的原因:
Python在运行函数时,会利用栈(Stack)来存储数据,执行完
函数后,所有数据会被自动删除。
函数中无法修改全局变量的原因:
当试图在函数里修改全局变量的值时,Python会自动在函数内部新建一个
名字一样的局部变量代替。如果硬是要修改,可以在函数内部使用
global关键字 修饰全局变量,但是不建议这样做,会使得程序
维护成本的提高。
7) 内部函数
其实就是函数嵌套,一个函数里嵌套另一个函数,需要注意一点:
内部函数的作用域只在内部函数的直接外部函数内,外部是
无法调用的,如果调用会报错的。
8) 闭包
Python中的闭包:如果在一个外部函数中,对外部作用域(非全局)的变量
进行引用,那么内部函数就被认为是闭包。简单的例子如下:


不能在外部函数以外的地方调用内部函数,会报方法名未定义。
另外,内部函数也不能直接修改外部函数里的变量,会报UnboundLocalError错误!
和前面函数里修改全局变量的情况一样,如果硬是要修改的话
可以把外部函数中的变量间接通过容器类型来存放,或者使用
Python3 中提供的nolocal关键字修饰修改的变量。例子如下:

9) lambda表达式
在Python中可以使用lambda关键字来创建匿名函数,直接返回一个函数对象,
不用去纠结起什么名字,省了定义函数的步骤,从而简化代码的可读性!
简单的对比大小lambda表达式例子如下:
big = lambda x, y: x > y
print("第一个参数比第二个参数大:%s" % big(1, 2))
# 输出结果:第一个参数比第二个参数大:False
10) 递归
其实就是函数调用自身,最简单的递归求和例子如下:
def sum(n):
if n == 1:
return 1
else:
return n + sum(n - 1)
print("1到100的求和结果是: %d" % sum(100))
# 输出结果:1到100的求和结果是: 5050
8.异常处理
1) 语法错误与运行异常区分
语法错误是连编译器那关都过不了的错误,比如if后漏掉:冒号,跑都跑不起来;
运行异常则是程序跑起来后,因为程序的业务逻辑问题引起的程序崩溃,比如除以0;
2) Python中的常见异常
| 异常 | 描述信息 |
|---|---|
AssertionError |
断言语句失败 |
AttributeError |
尝试访问未知的对象属性 |
IndexError |
索引超出序列的范围 |
keyError |
字典中查找一个不存在的Key |
NameError |
尝试访问一个不存在的变量 |
OSError |
操作系统产生的异常,比如FileNotFoundError |
SyntaxError |
Python语法错误 |
TypeError |
不同类型间的无效操作 |
ZeroDivisionError |
除数为0 |
IOError |
输入输出错误 |
ValueError |
函数传参类型错误 |
3) 异常捕获
try-expect-else语句,try-finally语句
# 1.最简单的,try捕获了任何异常,直接丢给except后的代码块处理:
try:
result = 1 / 0
except:
print("捕获到异常了!") # 输出:捕获到异常了!
# 2.捕获特定类型:
try:
result = 1 / 0
except ZeroDivisionError:
print("捕获到除数为零的错误") # 输出:捕获到除数为零的错误
# 3.针对不同的异常设置多个except
try:
sum = 1 + '2'
result = 1 / 0
except TypeError as reason:
print("类型出错:" + str(reason))
except ZeroDivisionError as reason:
print("除数为0:" + str(reason))
# 输出:类型出错:unsupported operand type(s) for +: 'int' and 'str'
# 4.对多个异常统一处理
try:
result = 1 / 0
sum = 1 + '2'
except (TypeError, ZeroDivisionError) as reason:
print(str(reason)) # 输出:division by zero
# 5.当没有检测到异常时才执行的代码块,可以用else
try:
result = 4 / 2
except ZeroDivisionError as reason:
print(str(reason))
else:
print("没有发生异常,输出结果:%d" % result)
# 输出:没有发生异常,输出结果:2
# 6.无论是否发生异常都会执行的一段代码块,比如io流关闭,
# 可以使用finally子句,如果发生异常先走except子句,后走finally子句。
try:
result = 4 / 2
except ZeroDivisionError as reason:
print(str(reason))
else:
print("没有发生异常,输出结果:%d" % result)
finally:
print("无论是否发生异常都会执行~")
# 输出结果:
# 没有发生异常,输出结果:2
# 无论是否发生异常都会执行~
4) 抛出异常
使用raise语句可以直接抛出异常,比如raise TypeError(异常解释,可选)
5) 上下文管理-with语句
当你的异常捕获代码仅仅是为了保证共享资源(文件,数据等)的唯一分配,
并在任务结束后释放掉它,那么可以使用with语句,例子如下:
try:
with open('123.txt', "w") as f:
for line in f:
print(line)
except OSError as reason:
print("发生异常:" + str(reason))
# 输出结果:发生异常:not readable
6) sys.exc_info 函数
除了上面获取异常信息的方式外,还可以通过sys模块的exc_info() 函数获得:
示例如下:
# 输出结果依次是:异常类,类示例,跟踪记录对象
try:
result = 1 / 0
except:
import sys
tuple_exception = sys.exc_info()
for i in tuple_exception:
print(i)
# 输出结果:
# <class 'ZeroDivisionError'>
# division by zero
# <traceback object at 0x7f3560c05808>
9.文件存储
1) open函数与文件打开模式
Python中读写文件非常简单,通过open()函数 可以打开文件并
返回文件对象使用help命令可以知道,open函数有好几个参数:

作为初学者,暂时了解前两个参数就够了:
file参数:文件名,不带路径的话会在当前文件夹中查找;
mode:打开模式,有以下几种打开方式:
| 模式 | 作用 |
|---|---|
r |
只读模式打开,默认 |
w |
写模式打开,若文件存在,先删除,然后重新创建 |
a |
追加模式打开,追加到文件末尾,seek()指向其他地方也没用,文件不存在,自动创建 |
b |
二进制模式打开 |
t |
文本模式打开,默认 |
+ |
可读写模式,可配合其他模式使用,比如r+,w+ |
x |
如果文件已存在,用此模式打开会引发异常 |
U |
通用换行符支持 |
2) 文件对象的方法
| 函数 | 作用 |
|---|---|
| close() | 关闭文件,关闭后文件不能再进行读写操作 |
| read(size=-1) | 从文件读取指定的字节数,如果未设置或为负数,读取所有 |
| next() | 返回文件下一行 |
| readline() | 读取整行,包括换行符'\n' |
| seek(offset, from) | 设置当前文件指针的位置,从from(0文件起始位置,1当前位置, 2文件末尾)偏移offset个字节 |
| tell() | 返回文件的当前位置 |
| write(str) | 将字符串写入文件 |
| writelines(seq) | 写入一个序列字符串列表,如果要换行,需要自己加入每行的换行符 |
3) 使用例子
# 读取123.txt文件里的内容打印,同时写入到321.txt中
try:
f1 = open("321.txt", "w")
with open("123.txt", "r") as f2:
for line in f2:
print(line, end="")
f1.write(line)
except OSError as reason:
print("发生异常" + str(reason))
finally:
f1.close() # 用完要关闭文件,f2不用是因为用了with
输出结果:

4) OS模块中关于文件/目录的常用函数
需要导入os模块,使用的时候需加上模块引用,比如os.getcwd()
| 函数 | 作用 |
|---|---|
| getcwd() | 返回当前工作目录 |
| chdir(path) | 改变当前工作目录 |
| listdir(path='.') | 不写参数默认列举当前目录下所有文件和文件夹,'.'当前目录,'..'上一层目录 |
| mkdir(path) | 创建文件夹,若存在会抛出FileExistsError异常 |
| mkdirs(path) | 可用于创建多层目录 |
| remove(path) | 删除指定文件 |
| rmdir(path) | 删除目录 |
| removedirs(path) | 删除多层目录 |
| rename(old,new) | 重命名文件或文件夹 |
| system(command) | 调用系统提供的小工具,比如计算器 |
| walk(top) | 遍历top参数指定路径下所有子目录,返回一个三元组(路径,[包含目录],[包含文件]) |
| curdir | 当前目录(.) |
| pardir | 上一节目录(..) |
| sep | 路径分隔符,Win下是'\',Linux下是'/' |
| linesep | 当前平台使用的行终止符,win下是'\r\n',Linux下是'\n' |
| name | 当前使用的操作系统 |
os.path模块(文件路径相关)
| 函数 | 作用 | |
|---|---|---|
| dirname(path) | 获得路径名 | |
| basename(path) | 获得文件名 | |
| join(path1[,path2[,...]]) | 将路径名与文件名拼接成一个完整路径 | |
| split(path) | 分割路径与文件名,返回元组(f_path, f_name),如果完全使用目录, 它也会将最后一个目录作为文件名分离,且不会判断文件或目录是否存在 |
|
| splitext(path) | 分隔文件名与扩展名 | |
| getsize(file) | 获得文件大小,单位是字节 | |
| getatime(file) | 获得文件最近访问时间,返回的是浮点型秒数 | |
| getctime(file) | 获得文件的创建时间,返回的是浮点型秒数 | |
| getmtime(file) | 获得文件的修改时间,返回的是浮点型秒数 | |
| exists(path) | 判断路径(文件或目录)是否存在 | |
| isabs(path) | 判断是否为决定路径 | |
| isdir(path) | 判断是否存在且是一个目录 | |
| isfile(path) | 判断是否存在且是一个文件 | |
| islink(path) | 判断是否存在且是一个符号链接 | |
| ismount(path) | 判断是否存在且是一个挂载点 | |
| samefile(path1,path2) | 判断两个路径是否指向同一个文件 | wenji |
10.类与对象
1) 最简单的例子
PS:Python中没有像其他语言一样有public或者private的关键字
来区分公有还是私有,默认公有,如果你想定义私有属性或者函数,
命名的时候在前面加上两下划线__即可,其实是伪私有,内部
采用的是名字改编技术,改成了_类名__私有属性/方法名,比如
下面调用people._Person__skill,是可以访问到私有成员的!
类中的属性是静态变量。

输出结果:
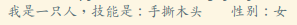
2) __init__(self) 构造方法
实例化对象的时候会自动调用,当你想传参的时候可以用它~

输出结果:

3) 继承
规则如下:
- 1.继承写法:
class 子类(父类): - 2.子类可以继承父类的所有属性与方法;
- 3.子类定义与父类同名的属性与方法会自动覆盖;
- 4.重写时如果想调用父类的同名方法可以使用
super()函数.方法名调用;
Python支持多继承,多个父类用逗号隔开,子类可同时继承多个父类的
属性与方法多继承的时候如果父类们中有相同的方法,调用的顺序是
谁在前面先调用那个父类中的方法,比如有class Person(Name, Sex,Age),
三个父类里都有一个show的方法,那么子类调用的是Name里的show()!
如果不是得用多继承不可的话,应该尽量避免使用它,有时会出现
一些不可遇见的BUG。
还有一种叫组合的套路,就是在把需要用到的类丢到组合类中
实例化,然后使用,比如把Book,Phone,Wallet放到Bag里:

输出结果:
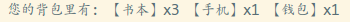
4) 与对象相关的一些内置函数
| 函数 | 作用 |
|---|---|
| issubclass(class, classinfo) | 如果第一个参数是第二个参数的子类,返回True,否则返回False |
| isinstance(object, classinfo) | 如果第一个参数是第二个参数的实例对象,返回True,否则返回False |
| hasattr(object, name) | 测试一个对象中是否有指定的属性,属性名要用引号括着! |
| getattr(object, name, [,default]) | 返回对象的指定属性值,不存在返回default值,没设会报ArttributeError异常 |
| setattr(object, name, value) | 设置对象中指定属性的值,属性不存在会新建并赋值 |
| delattr(object, name) | 删除对象中的指定属性的值,不存在会报报ArttributeError异常 |
| property(fget,fset,fdel,doc) | 返回一个可以设置属性的属性 |
11.模块
1) 导入模块
保存为.py后缀的文件都是一个独立的模块,比如有a.py和b.py文件,
你可以在a中import b,然后就可以使用b.py中的函数了。
模块导入规则4.1 导包处就写得详细了,此处就不重复描述了ß。
2) 指定模块
导入其他模块的时候,测试部分的代码也会执行,可以通过
__name__告诉Python该模块是作为程序运行还是导入到其他程序中。
作为程序运行时该属性的值是__main__,只有单独运行的时候才会执行。
比如:
if __name__ == '__main__':
test()
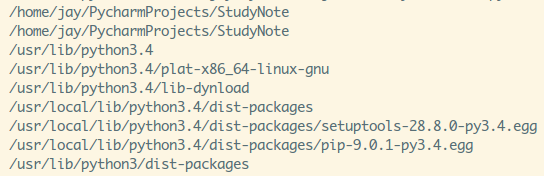
3) 搜索路径
Python模块的导入会有一个路径搜索的过程,如果这些搜索路径都找不到的话,
会报ImportError,可以通过打印sys.path可以看到这些搜索路径,比如我的:
如果你的模块都不在这些路径里,就会报错,当然也可以通过
sys.path.append("路径") 把路径添加到搜索路径中!
4) 下载安装第三方库
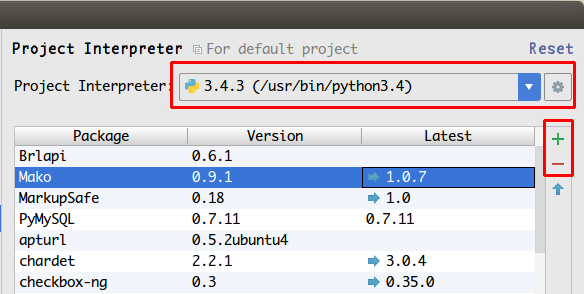
方法一:Pycharm直接安装
File -> Default Settings -> Project Interpreter -> 选择当前Python版本
可以看到当前安装的所有第三库,点+号进入库搜索,在搜索页找到想要的
库后勾选点击Install Package即可,点-号可以卸载不需要的库。
方法二:命令行使用pip命令安装
pip3 install 库名 # 安装
python3 -m pip install 库名 # 作用同上,可以区分python2和python3而已
pip install --upgrade pip # 更新pip
pip uninstall 库名 # 卸载库
pip list # 查看已安装库列表
结语
呼,历时两周,总算把Python的基础知识过了一遍,当然肯定是会有遗漏的
后面想到再补上吧,撸基本知识是挺乏味的,期待后续爬虫学习~

来啊,Py交易啊
想加群一起学习Py的可以加下,智障机器人小Pig,验证信息里包含:
Python,python,py,Py,加群,交易,屁眼 中的一个关键词即可通过;

验证通过后回复 加群 即可获得加群链接(不要把机器人玩坏了!!!)~~~
欢迎各种像我一样的Py初学者,Py大神加入,一起愉快地交流学♂习,van♂转py。

