Fluent Python Notebook Part Three
标签(空格分隔): Python
Object References, Mutability, and Recycling
Variables Are Not Boxes
Python variables are like reference variables in Java, so it’s better to think of them as labels attached to objects.

Example 8-2 proves that the righthand side of an assignment happens first. Example 8-2. Variables are assigned to objects only after the objects are created
>>> class Gizmo:
... def __init__(self):
... print('Gizmo id: %d' % id(self))
...
>>> x = Gizmo()
Gizmo id: 4301489152
>>> y = Gizmo() * 10
Gizmo id: 4301489432
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for *: 'Gizmo' and 'int'
>>>
>>> dir()
['Gizmo', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__', 'x']
Identity, Equality, and Aliases
Example 8-3. charles and lewis refer to the same object
>>> charles = {'name': 'Charles L. Dodgson', 'born': 1832}
>>> lewis = charles
>>> lewis is charles
True
>>> id(charles), id(lewis)
(4300473992, 4300473992)
>>> lewis['balance'] = 950
>>> charles
{'name': 'Charles L. Dodgson', 'balance': 950, 'born': 1832}

Example 8-4. alex and charles compare equal, but alex is not charles
>>> alex = {'name': 'Charles L. Dodgson', 'born': 1832, 'balance': 950}
>>> alex == charles
True
>>> alex is not charles
True
Every object has an identity, a type and a value. An object’s identity never changes once it has been created; you may think of it as the object’s address in memory. The is operator compares the identity of two objects; the id() function returns an integer representing its identity.
Choosing Between == and is
By far, the most common case is checking whether a variable is bound to None. This is the recommended way to do it:
x is None
And the proper way to write its negation is:
x is not None
The is operator is faster than ==, because it cannot be overloaded.
In contrast, a == b is syntactic sugar for a.__eq__(b).
The Relative Immutability of Tuples
If the referenced items are mutable, they may change even if the tuple itself does not.
Example 8-5. t1 and t2 initially compare equal, but changing a mutable item inside tuple t1 makes it different.
>>> t1 = (1, 2, [30, 40])
>>> t2 = (1, 2, [30, 40])
>>> t1 == t2
True
>>> id(t1[-1])
4302515784
>>> t1[-1].append(99)
>>> t1
(1, 2, [30, 40, 99])
>>> id(t1[-1])
4302515784
>>> t1 == t2
False
Copies Are Shallow by Default
The easiest way to copy a list (or most built-in mutable collections) is to use the builtin constructor for the type itself.
>>> l1 = [3, [55, 44], (7, 8, 9)]
>>> l2 = list(l1)
>>> l2
[3, [55, 44], (7, 8, 9)]
>>> l2 == l1
True
>>> l2 is l1
False
For lists and other mutable sequences, the shortcut l2 = l1[:] also makes a copy.
However, using the constructor or [:] produces a shallow copy (i.e., the outermost container is duplicated, but the copy is filled with references to the same items held by the original container).
I highly recommend watching the interactive animation for Example 8-6 at the Online Python Tutor.
Example 8-6. Making a shallow copy of a list containing another list; copy and paste this code to see it animated at the Online Python Tutor
l1 = [3, [66, 55, 44], (7, 8, 9)]
l2 = list(l1)
l1.append(100)
l1[1].remove(55)
print('l1:', l1)
# l1: [3, [66, 44], (7, 8, 9), 100]
print('l2:', l2)
# l2: [3, [66, 44], (7, 8, 9)]
l2[1] += [33, 22] #
l2[2] += (10, 11) #
print('l1:', l1)
# l1: [3, [66, 44, 33, 22], (7, 8, 9), 100]
print('l2:', l2)
# l2: [3, [66, 44, 33, 22], (7, 8, 9, 10, 11)]
Deep and Shallow Copies of Arbitrary Objects
The copy module provides the deepcopy and copy functions that return deep and shallow copies of arbitrary objects.
Example 8-8. Bus picks up and drops off passengers
class Bus:
def __init__(self, passengers=None):
if passengers is None:
self.passengers = []
else:
self.passengers = list(passengers)
def pick(self, name):
self.passengers.append(name)
def drop(self, name):
self.passengers.remove(name)
Example 8-9. Effects of using copy versus deepcopy
>>> import copy
>>> bus1 = Bus(['Alice', 'Bill', 'Claire', 'David'])
>>> bus2 = copy.copy(bus1)
>>> bus3 = copy.deepcopy(bus1)
>>> id(bus1), id(bus2), id(bus3)
(4301498296, 4301499416, 4301499752)
>>> bus1.drop('Bill')
>>> bus2.passengers
['Alice', 'Claire', 'David']
>>> id(bus1.passengers), id(bus2.passengers), id(bus3.passengers)
(4302658568, 4302658568, 4302657800)
>>> bus3.passengers
['Alice', 'Bill', 'Claire', 'David']
Note that making deep copies is not a simple matter in the general case. Objects may have cyclic references that would cause a naïve algorithm to enter an infinite loop. The deepcopy function remembers the objects already copied to handle cyclic references gracefully.
Example 8-10. Cyclic references: b refers to a, and then is appended to a; deepcopy still manages to copy a
>>> a = [10, 20]
>>> b = [a, 30]
>>> a.append(b)
>>> a
[10, 20, [[...], 30]]
>>> from copy import deepcopy
>>> c = deepcopy(a)
>>> c
[10, 20, [[...], 30]]
You can control the behavior of both copy and deepcopy by implementing the __copy__() and __deepcopy__() special methods.
Function Parameters as References
The only mode of parameter passing in Python is call by sharing.
Example 8-11. A function may change any mutable object it receives.
>>> def f(a, b):
... a += b
... return a
...
>>> x = 1
>>> y = 2
>>> f(x, y)
3
>>> x, y
(1, 2)
>>> a = [1, 2]
>>> b = [3, 4]
>>> f(a, b)
[1, 2, 3, 4]
>>> a, b
([1, 2, 3, 4], [3, 4])
>>> t = (10, 20)
>>> u = (30, 40)
>>> f(t, u)
(10, 20, 30, 40)
>>> t, u
((10, 20), (30, 40))
Mutable Types as Parameter Defaults: Bad Idea
Example 8-12. A simple class to illustrate the danger of a mutable default.
class HauntedBus:
"""A bus model haunted by ghost passengers"""
def __init__(self, passengers=[]): # <1>
self.passengers = passengers # <2>
def pick(self, name):
self.passengers.append(name) # <3>
def drop(self, name):
self.passengers.remove(name)
Example 8-13. Buses haunted by ghost passengers
>>> bus1 = HauntedBus(['Alice', 'Bill'])
>>> bus1.passengers
['Alice', 'Bill']
>>> bus1.pick('Charlie')
>>> bus1.drop('Alice')
>>> bus1.passengers
['Bill', 'Charlie']
>>> bus2 = HauntedBus()
>>> bus2.pick('Carrie')
>>> bus2.passengers
['Carrie']
>>> bus3 = HauntedBus()
>>> bus3.passengers
['Carrie']
>>> bus3.pick('Dave')
>>> bus2.passengers
['Carrie', 'Dave']
>>> bus2.passengers is bus3.passengers
True
>>> bus1.passengers
['Bill', 'Charlie']
>>> dir(HauntedBus.__init__) # doctest: +ELLIPSIS
['__annotations__', '__call__', ..., '__defaults__', ...]
>>> HauntedBus.__init__.__defaults__
(['Carrie', 'Dave'],)
>>> HauntedBus.__init__.__defaults__[0] is bus2.passengers
True
The problem is that Bus instances that don’t get an initial passenger list end up sharing the same passenger list among themselves.
Strange things happen only when a HauntedBus starts empty, because then self.passengers becomes an alias for the default value of the passengers parameter.
Defensive Programming with Mutable Parameters
The last bus example in this chapter shows how a TwilightBus breaks expectations by sharing its passenger list with its clients.
Example 8-15. A simple class to show the perils of mutating received arguments.
class TwilightBus:
"""A bus model that makes passengers vanish"""
def __init__(self, passengers=None):
if passengers is None:
self.passengers = [] # <1>
else:
self.passengers = passengers #<2>
def pick(self, name):
self.passengers.append(name)
def drop(self, name):
self.passengers.remove(name)
Example 8-14. Passengers disappear when dropped by a TwilightBus
>>> basketball_team = ['Sue', 'Tina', 'Maya', 'Diana', 'Pat']
>>> bus = TwilightBus(basketball_team)
>>> bus.drop('Tina')
>>> bus.drop('Pat')
>>> basketball_team
['Sue', 'Maya', 'Diana']
The problem here is that the bus is aliasing the list that is passed to the constructor. Instead, it should keep its own passenger list.
def __init__(self, passengers=None):
if passengers is None:
self.passengers = []
else:
self.passengers = list(passengers)
del and Garbage Collection
The del statement deletes names, not objects. An object may be garbage collected as result of a del command, but only if the variable deleted holds the last reference to the object, or if the object becomes unreachable.
A Pythonic Object
Object Representations
Every object-oriented language has at least one standard way of getting a string representation from any object. Python has two:
- repr(): Return a string representing the object as the developer wants to see it.
- str(): Return a string representing the object as the user wants to see it.
As you know, we implement the special methods __repr__ and __str__ to support repr() and str().
There are two additional special methods to support alternative representations of objects: __bytes__ and __format__. The __bytes__ method is analogous to __str__: it’s called by bytes() to get the object represented as a byte sequence. Regarding __format__, both the built-in function format() and the str.format() method call it to get string displays of objects using special formatting codes.
Vector Class Redux
Example 9-2. vector2d_v0.py: methods so far are all special methods
from array import array
import math
class Vector2d:
typecode = 'd'
def __init__(self, x, y):
self.x = float(x) # Converting x and y to float in __init__ catches errors early
self.y = float(y)
# __iter__ makes a Vector2d iterable;
# this is what makes unpacking work (e.g, x, y = my_vector).
# We implement it simply by using a generator expression
# to yield the components one after the other.
def __iter__(self):
return (i for i in (self.x, self.y))
# *self feeds the x and y components to
format
def __repr__(self):
class_name = type(self).__name__
return '{}({!r}, {!r})'.format(class_name, *self)
def __str__(self):
return str(tuple(self))
def __bytes__(self):
return (bytes([ord(self.typecode)]) +
bytes(array(self.typecode, self)))
def __eq__(self, other):
return tuple(self) == tuple(other)
def __abs__(self):
return math.hypot(self.x, self.y)
def __bool__(self):
return bool(abs(self))
>>> v1 = Vector2d(3, 4)
>>> print(v1.x, v1.y)
3.0 4.0
>>> x, y = v1
>>> x, y
(3.0, 4.0)
>>> v1
Vector2d(3.0, 4.0)
>>> v1_clone = eval(repr(v1))
>>> v1 == v1_clone
True
>>> print(v1)
(3.0, 4.0)
>>> octets = bytes(v1)
>>> octets
b'd\\x00\\x00\\x00\\x00\\x00\\x00\\x08@\\x00\\x00\\x00\\x00\\x00\\x00\\x10@'
>>> abs(v1)
5.0
>>> bool(v1), bool(Vector2d(0, 0))
(True, False)
An Alternative Constructor
Because we can export a Vector2d as bytes, naturally we need a method that imports a Vector2d from a binary sequence.
@classmethod
def frombytes(cls, octets): # No self argument; instead, the class itself is passed as cls.
typecode = chr(octets[0])
memv = memoryview(octets[1:]).cast(typecode)
return cls(*memv)
classmethod Versus staticmethod
classmethod changes the way the method is called, so it receives the class itself as the first argument, instead of an instance. By convention, the first parameter of a class method should be named cls (but Python doesn’t care how it’s named).
In contrast, the staticmethod decorator changes a method so that it receives no special first argument. In essence, a static method is just like a plain function that happens to
live in a class body, instead of being defined at the module level.
Example 9-4. Comparing behaviors of classmethod and staticmethod.
>>> class Demo:
... @classmethod
... def klassmeth(*args):
... return args
... @staticmethod
... def statmeth(*args):
... return args
...
>>> Demo.klassmeth()
(<class '__main__.Demo'>,)
>>> Demo.klassmeth('spam')
(<class '__main__.Demo'>, 'spam')
>>> Demo.statmeth()
()
>>> Demo.statmeth('spam')
('spam',)
The classmethod decorator is clearly useful, but I’ve never seen a compelling use case for staticmethod. If you want to define a function that does not interact with the class, just define it in the module.
Formatted Displays
The format() built-in function and the str.format() method delegate the actual formatting to each type by calling their .__format__(format_spec) method.
The format_spec is a formatting specifier, which is either:
- The second argument in format(my_obj, format_spec), or
- Whatever appears after the colon in a replacement field delimited with {} inside a format string used with str.format()
>>> brl = 1/2.43 # BRL to USD currency conversion rate
>>> brl
0.4115226337448559
>>> format(brl, '0.4f')
'0.4115'
>>> '1 BRL = {rate:0.2f} USD'.format(rate=brl)
'1 BRL = 0.41 USD'
The notation used in the formatting specifier is called the Format Specification Mini-Language.
If a class has no __format__, the method inherited from object returns str(my_object). However, if you pass a format specifier, object.__format__ raises TypeError:
>>> v1 = Vector2d(3, 4)
>>> format(v1)
'(3.0, 4.0)'
>>> format(v1, '.3f')
Traceback (most recent call last):
...
TypeError: non-empty format string passed to object.__format__
We will fix that by implementing our own format mini-language. To generate polar coordinates we already have the __abs__ method for the magnitude, and we’ll code a simple angle method using the math.atan2() function to get the angle.
def angle(self):
return math.atan2(self.y, self.x)
With that, we can enhance our __format__ to produce polar coordinates.
def __format__(self, fmt_spec=''):
if fmt_spec.endswith('p'): # Format ends with 'p': use polar coordinates.
fmt_spec = fmt_spec[:-1] # Remove 'p' suffix from fmt_spec.
coords = (abs(self), self.angle())
outer_fmt = '<{}, {}>'
else:
coords = self
outer_fmt = '({}, {})'
components = (format(c, fmt_spec) for c in coords)
return outer_fmt.format(*components)
>>> format(Vector2d(1, 1), 'p')
'<1.414213..., 0.785398...>'
>>> format(Vector2d(1, 1), '.3ep')
'<1.414e+00, 7.854e-01>'
>>> format(Vector2d(1, 1), '0.5fp')
'<1.41421, 0.78540>'
A Hashable Vector2d
As defined, so far our Vector2d instances are unhashable, so we can’t put them in a set.
>>> v1 = Vector2d(3, 4)
>>> hash(v1)
Traceback (most recent call last):
...
TypeError: unhashable type: 'Vector2d'
>>> set([v1])
Traceback (most recent call last):
...
TypeError: unhashable type: 'Vector2d'
To make a Vector2d hashable, we must implement __hash__ (__eq__ is also required, and we already have it). We also need to make vector instances immutable.
Right now, anyone can do v1.x = 7 and there is nothing in the code to suggest that changing a Vector2d is forbidden. This is the behavior we want:
>>> v1.x, v1.y
(3.0, 4.0)
>>> v1.x = 7
Traceback (most recent call last):
...
AttributeError: can't set attribute
Example 9-7. vector2d_v3.py: only the changes needed to make Vector2d immutable are shown here.
class Vector2d:
typecode = 'd'
def __init__(self, x, y):
self.__x = float(x)
self.__y = float(y)
@property
def x(self):
return self.__x
@property
def y(self):
return self.__y
def __iter__(self):
return (i for i in (self.x, self.y))
Now that our vectors are reasonably immutable, we can implement the __hash__ method. It should return an int and ideally take into account the hashes of the object attributes that are also used in the __eq__ method, because objects that compare equal should have the same hash.
def __hash__(self):
return hash(self.x) ^ hash(self.y)
With the addition of the **__hash__ method, we now have hashable vectors:
>>> v1 = Vector2d(3, 4)
>>> v2 = Vector2d(3.1, 4.2)
>>> hash(v1), hash(v2)
(7, 384307168202284039)
>>> set([v1, v2])
{Vector2d(3.1, 4.2), Vector2d(3.0, 4.0)}
Sequence Hacking, Hashing, and Slicing
Vector: A User-Defined Sequence Type
Our strategy to implement Vector will be to use composition, not inheritance. We’ll store the components in an array of floats, and will implement the methods needed for our Vector to behave like an immutable flat sequence.
Vector Take #1: Vector2d Compatible
Example 10-2. vector_v1.py: derived from vector2d_v1.py
from array import array
import reprlib
import math
class Vector:
typecode = 'd'
def __init__(self, components):
self._components = array(self.typecode, components) # The self._components instance “protected” attribute will hold an array with the Vector components.
def __iter__(self):
return iter(self._components)
def __repr__(self):
components = reprlib.repr(self._components)
components = components[components.find('['):-1]
return 'Vector({})'.format(components)
def __str__(self):
return str(tuple(self))
def __bytes__(self):
return (bytes([ord(self.typecode)]) +
bytes(self._components))
def __eq__(self, other):
return tuple(self) == tuple(other)
def __abs__(self):
return math.sqrt(sum(x * x for x in self))
def __bool__(self):
return bool(abs(self))
@classmethod
def frombytes(cls, octets):
typecode = chr(octets[0])
memv = memoryview(octets[1:]).cast(typecode)
return cls(memv)
The way I used reprlib.repr deserves some elaboration. That function produces safe representations of large or recursive structures by limiting the length of the output string and marking the cut with '...'.
Because of its role in debugging, calling repr() on an object should never raise an exception.
Example 10-1. Tests of Vector.__init__ and Vector.__repr__.
>>> Vector([3.1, 4.2])
Vector([3.1, 4.2])
>>> Vector((3, 4, 5))
Vector([3.0, 4.0, 5.0])
>>> Vector(range(10))
Vector([0.0, 1.0, 2.0, 3.0, 4.0, ...])
Protocols and Duck Typing
You don’t need to inherit from any special class to create a fully functional sequence type in Python; you just need to implement the methods that fulfill the sequence protocol.
In the context of object-oriented programming, a protocol is an informal interface, defined only in documentation and not in code.
For example, the sequence protocol in Python entails just the __len__ and __getitem__ methods. All that
matters is that it provides the necessary methods.
Example 10-3. Code from Example 1-1, reproduced here for convenience.
import collections
Card = collections.namedtuple('Card', ['rank', 'suit'])
class FrenchDeck:
ranks = [str(n) for n in range(2, 11)] + list('JQKA')
suits = 'spades diamonds clubs hearts'.split()
def __init__(self):
self._cards = [Card(rank, suit) for suit in self.suits
for rank in self.ranks]
def __len__(self):
return len(self._cards)
def __getitem__(self, position):
return self._cards[position]
The FrenchDeck class in Example 10-3 takes advantage of many Python facilities because it implements the sequence protocol, even if that is not declared anywhere in the code. Any experienced Python coder will look at it and understand that it is a sequence, even if it subclasses object. We say it is a sequence because it behaves like one, and that is what matters.
Because protocols are informal and unenforced, you can often get away with implementing just part of a protocol, if you know the specific context where a class will be used. For example, to support iteration, only __getitem__ is required; there is no need to provide __len__.
Vector Take #2: A Sliceable Sequence
class Vector:
# many lines omitted
# ...
def __len__(self):
return len(self._components)
def __getitem__(self, index):
return self._components[index]
With these additions, all of these operations now work:
>>> v1 = Vector([3, 4, 5])
>>> len(v1)
3
>>> v1[0], v1[-1]
(3.0, 5.0)
>>> v7 = Vector(range(7))
>>> v7[1:4]
array('d', [1.0, 2.0, 3.0])
As you can see, even slicing is supported—but not very well. It would be better if a slice of a Vector was also a Vector instance and not a array. In the case of Vector, a lot of functionality is lost when slicing produces plain arrays.
How Slicing Works
Example 10-4. Checking out the behavior of __getitem__ and slices.
>>> class MySeq:
... def __getitem__(self, index):
... return index
...
>>> s = MySeq()
>>> s[1]
1
>>> s[1:4]
slice(1, 4, None)
>>> s[1:4:2]
slice(1, 4, 2)
>>> s[1:4:2, 9]
(slice(1, 4, 2), 9)
>>> s[1:4:2, 7:9]
(slice(1, 4, 2), slice(7, 9, None))
Example 10-5. Inspecting the attributes of the slice class.
>>> slice
<class 'slice'>
>>> dir(slice)
['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__le__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'indices', 'start', 'step', 'stop']
Calling dir(slice) reveals an indices attribute, which turns out to be a very interesting but little-known method. Here is what help(slice.indices) reveals:
S.indices(len) -> (start, stop, stride)
This method produces “normalized” tuples of nonnegative start, stop, and stride integers adjusted to fit within the bounds of a sequence of the given length.
>>> slice(None, 10, 2).indices(5)
(0, 5, 2)
>>> slice(-3, None, None).indices(5)
(2, 5, 1)
A Slice-Aware __getitem__
Example 10-6. Part of vector_v2.py: __len__ and __getitem__ methods added to Vector class from vector_v1.py.
def __len__(self):
return len(self._components)
def __getitem__(self, index):
cls = type(self)
if isinstance(index, slice):
return cls(self._components[index])
elif isinstance(index, numbers.Integral):
return self._components[index]
else:
msg = '{cls.__name__} indices must be integers'
raise TypeError(msg.format(cls=cls))
Excessive use of isinstance may be a sign of bad OO design, but handling slices in __getitem__ is a justified use case.
Example 10-7. Tests of enhanced Vector.getitem from Example 10-6.
>>> v7 = Vector(range(7))
>>> v7[-1]
6.0
>>> v7[1:4]
Vector([1.0, 2.0, 3.0])
>>> v7[-1:]
Vector([6.0])
>>> v7[1,2]
Traceback (most recent call last):
...
TypeError: Vector indices must be integers
Vector Take #3: Dynamic Attribute Access
In the evolution from Vector2d to Vector, we lost the ability to access vector components by name (e.g., v.x, v.y).
In Vector2d, we provided read-only access to x and y using the @property decorator. We could write four properties in Vector, but it would be tedious. The __getattr__ special method provides a better way.
The __getattr__ method is invoked by the interpreter when attribute lookup fails. In simple terms, given the expression my_obj.x, Python checks if the my_obj instance has an attribute named x; if not, the search goes to the class (my_obj.__class__), and then up the inheritance graph. If the x attribute is not found, then the __getattr__ method defined in the class of my_obj is called with self and the name of the attribute as a string (e.g., 'x').
Example 10-8. Part of vector_v3.py: __getattr__ method added to Vector class from vector_v2.py.
shortcut_names = 'xyzt'
def __getattr__(self, name):
cls = type(self)
if len(name) == 1:
pos = cls.shortcut_names.find(name)
if 0 <= pos < len(self._components):
return self._components[pos]
msg = '{.__name__!r} object has no attribute {!r}'
raise AttributeError(msg.format(cls, name))
Example 10-9. Inappropriate behavior: assigning to v.x raises no error, but introduces an inconsistency
>>> v = Vector(range(5))
>>> v
Vector([0.0, 1.0, 2.0, 3.0, 4.0])
>>> v.x
0.0
>>> v.x = 10
>>> v.x
10
>>> v
Vector([0.0, 1.0, 2.0, 3.0, 4.0])
To do that, we’ll implement __setattr__ as listed in Example 10-10.
Example 10-10. Part of vector_v3.py: __setattr__ method in Vector class.
def __setattr__(self, name, value):
cls = type(self)
if len(name) == 1:
if name in cls.shortcut_names:
error = 'readonly attribute {attr_name!r}'
elif name.islower():
error = "can't set attributes 'a' to 'z' in {cls_name!r}"
else:
error = ''
if error:
msg = error.format(cls_name=cls.__name__, attr_name=name)
raise AttributeError(msg)
super().__setattr__(name, value)
The super() function provides a way to access methods of superclasses dynamically, a necessity in a dynamic language supporting multiple inheritance like Python. It’s used to delegate some task from a method in a subclass to a suitable method in a superclass.
Even without supporting writing to the Vector components, here is an important takeaway from this example: very often when you implement __getattr__ you need to code __setattr__ as well, to avoid inconsistent behavior in your objects.
If we wanted to allow changing components, we could implement __setitem__ to enable v[0] = 1.1 and/or __setattr__ to make v.x = 1.1 work. But Vector will remain immutable because we want to make it hashable in the coming section.
Vector Take #4: Hashing and a Faster ==
Once more we get to implement a __hash__ method. Together with the existing __eq__, this will make Vector instances hashable.
The reduce is not as popular as before, but computing the hash of all vector components is a perfect job for it.
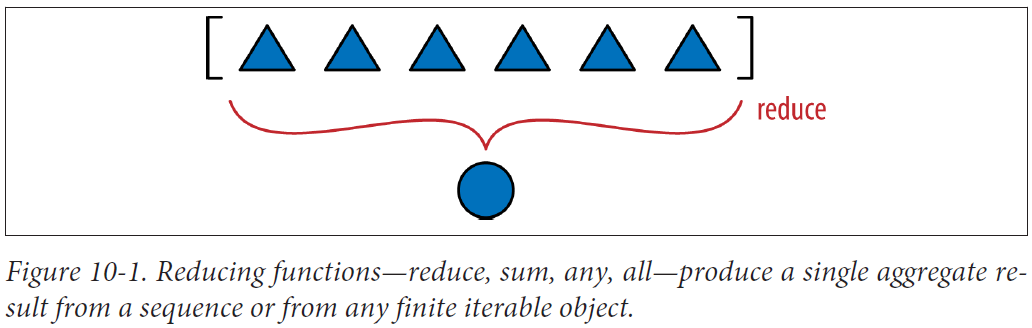
When you call reduce(fn, lst), fn will be applied to the first pair of elements — fn(lst[0], lst[1]) — producing a first result, r1. Then fn is applied to r1 and the next element—fn(r1, lst[2])—producing a second result, r2. Now fn(r2, lst[3]) is called to produce r3 … and so on until the last element, when a single result, rN, is returned.
>>> 2 * 3 * 4 * 5 # the result we want: 5! == 120
120
>>> import functools
>>> functools.reduce(lambda a,b: a*b, range(1, 6))
120
Example 10-12. Part of vector_v4.py: two imports and __hash__ method added to Vector class from vector_v3.py.
class Vector:
typecode = 'd'
# many lines omitted in book listing...
def __eq__(self, other):
return (len(self) == len(other) and
all(a == b for a, b in zip(self, other)))
def __hash__(self):
hashes = (hash(x) for x in self)
return functools.reduce(operator.xor, hashes, 0)
When using reduce, it’s good practice to provide the third argument, reduce(function, iterable, initializer), to prevent this exception: TypeError: reduce() of empty sequence with no initial value (excellent message: explains the problem and how to fix it). The initializer is the value returned if the sequence is empty and is used as the first argument in the reducing loop, so it should be the identity value of the operation.
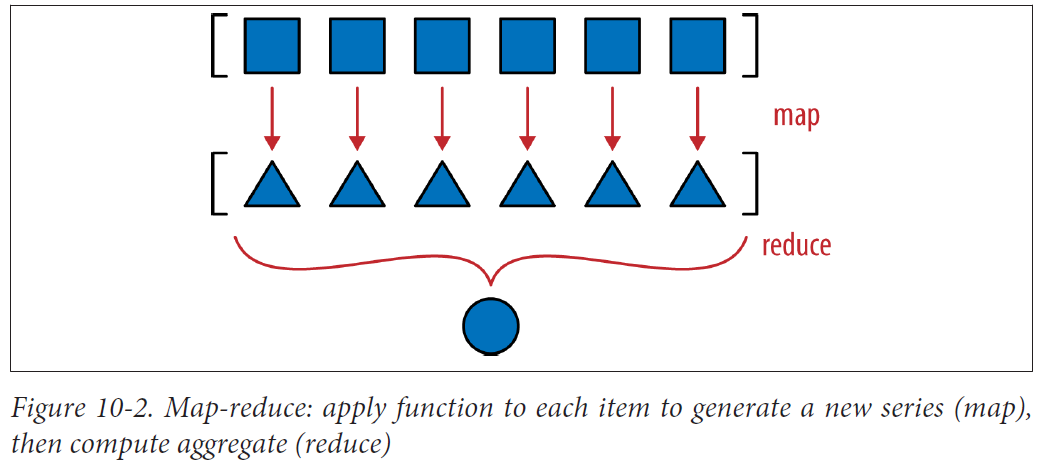
The mapping step produces one hash for each component, and the reduce step aggregates all hashes with the xor operator. Using map instead of a genexp makes the mapping step even more visible:
def __hash__(self):
hashes = map(hash, self._components)
return functools.reduce(operator.xor, hashes)
In Python 3, map is lazy: it creates a generator that yields the results on demand, thus saving memory—just like the generator expression.
The Awesome zip
The zip built-in makes it easy to iterate in parallel over two or more iterables by returning tuples that you can unpack into variables, one for each item in the parallel inputs.
Example 10-15. The zip built-in at work
>>> zip(range(3), 'ABC')
<zip object at 0x10063ae48>
>>> list(zip(range(3), 'ABC'))
[(0, 'A'), (1, 'B'), (2, 'C')]
>>> list(zip(range(3), 'ABC', [0.0, 1.1, 2.2, 3.3]))
[(0, 'A', 0.0), (1, 'B', 1.1), (2, 'C', 2.2)]
>>> from itertools import zip_longest
>>> list(zip_longest(range(3), 'ABC', [0.0, 1.1, 2.2, 3.3], fillvalue=-1))
[(0, 'A', 0.0), (1, 'B', 1.1), (2, 'C', 2.2), (-1, -1, 3.3)]
The enumerate built-in is another generator function often used in for loops to avoid manual handling of index variables.
Vector Take #5: Formatting
The __format__ method of Vector will resemble that of Vector2d, but instead of providing a custom display in polar coordinates.
Interfaces: From Protocols to ABCs
An abstract class represents an interface.
From the dynamic protocols that are the hallmark of duck typing to abstract base classes (ABCs) that make interfaces explicit and verify implementations for conformance.
Interfaces and Protocols in Python Culture
An interface seen as a set of methods to fulfill a role is what Smalltalkers called a procotol, and the term spread to other dynamic language communities. Protocols are independent of inheritance. A class may implement several protocols, enabling its instances to fulfill several roles.
Protocols are interfaces, but because they are informal—defined only by documentation and conventions—protocols cannot be enforced like formal interfaces can. A protocol may be partially implemented in a particular class, and that’s OK.
Python Digs Sequences
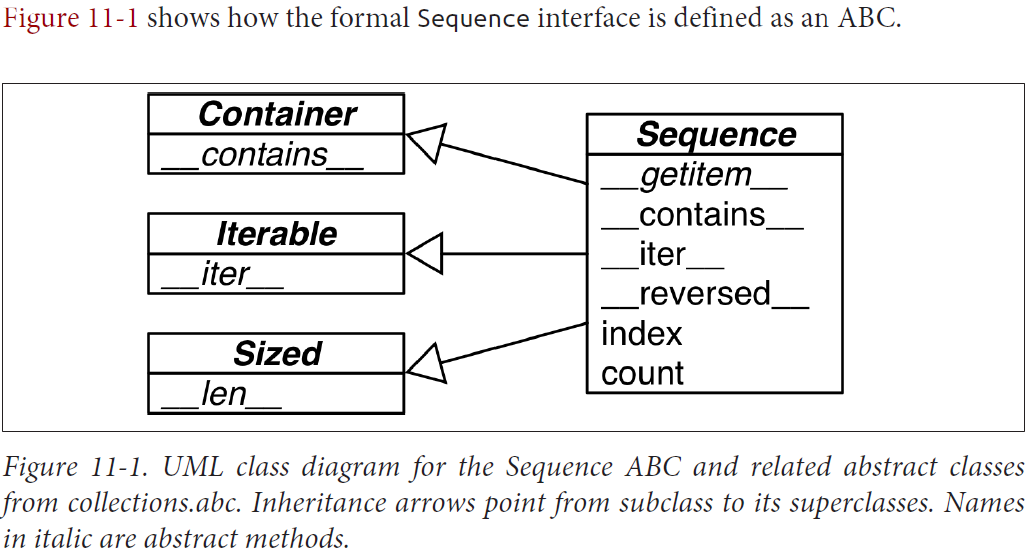
Now, take a look at the Foo class. It does not inherit from abc.Se quence, and it only implements one method of the sequence protocol: __getitem__ (__len__ is missing).
Example 11-3. Partial sequence protocol implementation with __getitem__: enough for item access, iteration, and the in operator.
>>> class Foo:
... def __getitem__(self, pos):
... return range(0, 30, 10)[pos]
>>> f = Foo()
>>> for i in f: print(i)
...
0
10
20
>>> 20 in f
True
>>> 15 in f
False
Given the importance of the sequence protocol, in the absence __iter__ and __contains__ Python still manages to make iteration and the in operator work by invoking __getitem__.
Monkey-Patching to Implement a Protocol at Runtime
The standard random.shuffle function is used like this:
>>> from random import shuffle
>>> l = list(range(10))
>>> shuffle(l)
>>> l
[5, 2, 9, 7, 8, 3, 1, 4, 0, 6]
However, if we try to shuffle a FrenchDeck instance, we get an exception. Example 11-5. random.shuffle cannot handle FrenchDeck.
>>> from random import shuffle
>>> from frenchdeck import FrenchDeck
>>> deck = FrenchDeck()
>>> shuffle(deck)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File ".../python3.3/random.py", line 265, in shuffle
x[i], x[j] = x[j], x[i]
TypeError: 'FrenchDeck' object does not support item assignment
The problem is that shuffle operates by swapping items inside the collection, and FrenchDeck only implements the immutable sequence protocol. Mutable sequences must also provide a __setitem__ method.
Because Python is dynamic, we can fix this at runtime, even at the interactive console.
Example 11-6. Monkey patching FrenchDeck to make it mutable and compatible with random.shuffle.
>>> def set_card(deck, position, card):
... deck._cards[position] = card
...
>>> FrenchDeck.__setitem__ = set_card
>>> shuffle(deck)
>>> deck[:5]
[Card(rank='3', suit='hearts'), Card(rank='4', suit='diamonds'), Card(rank='4', suit='clubs'), Card(rank='7', suit='hearts'), Card(rank='9', suit='spades')]
This is an example of monkey patching: changing a class or module at runtime, without touching the source code. Monkey patching is powerful, but the code that does the actual patching is very tightly coupled with the program to be patched, often handling private and undocumented parts.
Example 11-6 highlights that protocols are dynamic: random.shuffle doesn’t care what type of argument it gets, it only needs the object to implement part of the mutable sequence protocol.
Alex Martelli’s Waterfowl
Alex Martelli explains in a guest essay why ABCs were a great addition to Python.
Alex makes the point that inheriting from an ABC is more than implementing the required methods. In addition, the use of isinstance and issubclass becomes more acceptable to test
against ABCs.
However, even with ABCs, you should beware that excessive use of isinstance checks may be a code smell—a symptom of bad OO design. It’s usually not OK to have a chain of if/elif/elif with insinstance checks performing different actions depending on the type of an object.
For example, in several classes in this book, when I needed to take a sequence of items and process them as a list, instead of requiring a list argument by type checking, I simply took the argument and immediately built a list from it: that way I can accept any iterable, and if the argument is not iterable, the call will fail soon enough with a very clear message.
Example 11-7. Duck typing to handle a string or an iterable of strings.
try:
field_names = field_names.replace(',', ' ').split()
except AttributeError:
pass
field_names = tuple(field_names)
Subclassing an ABC
Example 11-8. frenchdeck2.py: FrenchDeck2, a subclass of collections.MutableSequence.
import collections
Card = collections.namedtuple('Card', ['rank', 'suit'])
class FrenchDeck2(collections.MutableSequence):
ranks = [str(n) for n in range(2, 11)] + list('JQKA')
suits = 'spades diamonds clubs hearts'.split()
def __init__(self):
self._cards = [Card(rank, suit) for suit in self.suits
for rank in self.ranks]
def __len__(self):
return len(self._cards)
def __getitem__(self, position):
return self._cards[position]
def __setitem__(self, position, value): # __setitem__ is all we need to enable shuffling
self._cards[position] = value
def __delitem__(self, position): # But subclassing MutableSequence forces us to implement __delitem__, an abstract method of that ABC.
del self._cards[position]
def insert(self, position, value): # We are also required to implement insert, the third abstract method of MutableSequence.
self._cards.insert(position, value)
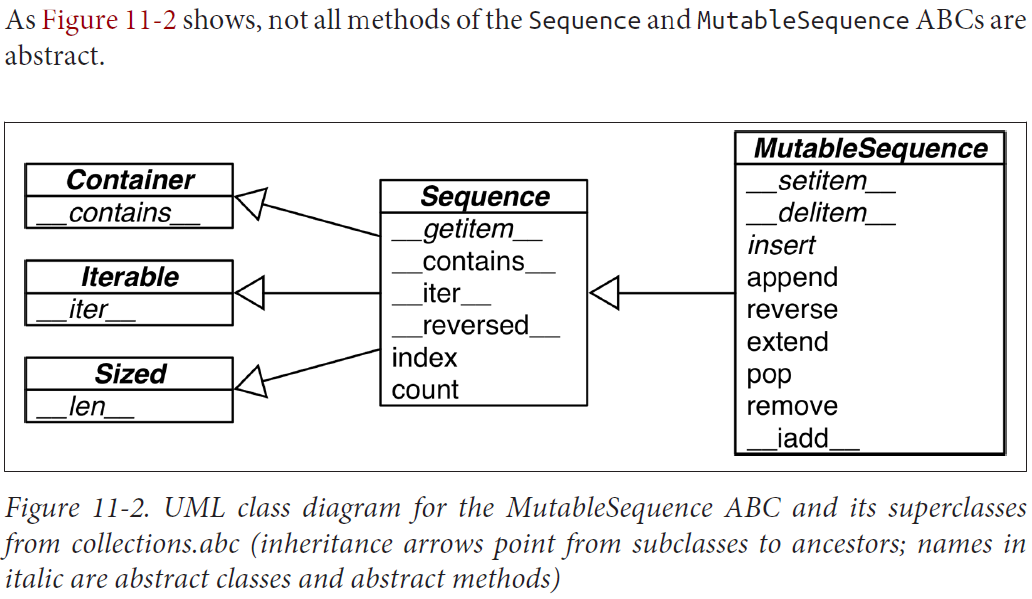
To use ABCs well, you need to know what’s available.
ABCs in the Standard Library
ABCs in collections.abc
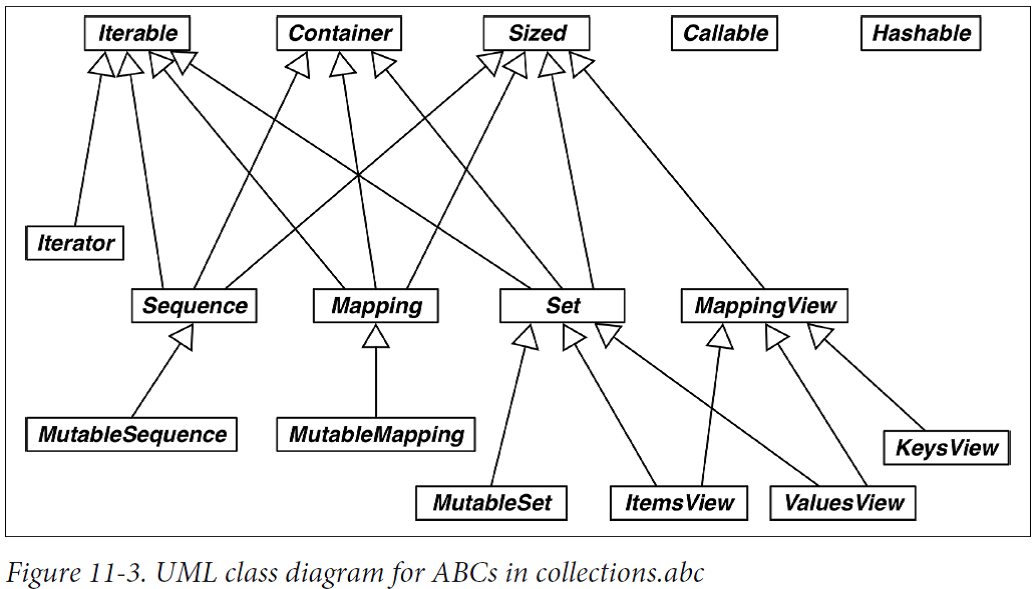
Let’s review the clusters in Figure 11-3:
Iterable, Container, and Sized: Every collection should either inherit from these ABCs or at least implement compatible protocols. Iterable supports iteration with __iter__, Container supports the in operator with __contains__, and Sized supports len() with __len__.
Sequence, Mapping, and Set: These are the main immutable collection types, and each has a mutable subclass. A detailed diagram for MutableSequence is in Figure 11-2; for MutableMapping and MutableSet, there are diagrams in Chapter 3 (Figures 3-1 and 3-2).
MappingView: In Python 3, the objects returned from the mapping methods .items(), .keys(), and .values() inherit from ItemsView, ValuesView, and ValuesView, respectively.
Callable and Hashable: never seen subclasses of either Callable or Hashable. Their main use is to support the insinstance built-in as a safe way of determining whether an object is callable or hashable.
Iterator: Note that iterator subclasses Iterable.
The Numbers Tower of ABCs
The numbers package defines the so-called “numerical tower” (i.e., this linear hierarchy of ABCs), where Number is the topmost superclass, Complex is its immediate subclass, and so on, down to Integral:
- umber
- Complex
- Real
- Rational
- Integral
So if you need to check for an integer, use
isinstance(x, numbers.Integral)
to accept int, bool (which subclasses int) or other integer types that may be provided by external libraries that register their types with the numbers ABCs. And to satisfy your check, you or the users of your API may always register any compatible type as a virtual subclass of numbers.Integral.
Further Reading
Beazley and Jones’s Python Cookbook, 3rd Edition (O’Reilly) has a section about defining an ABC.
