作者:Umberto Raimondi,原文链接,原文日期:2016-10-27
译者:shanks;校对:Crystal Sun;定稿:CMB
每当处理循环引用(retain cycles)时,需要考量对象生命周期来选择unowned或者weak标识符,这已经成为了一个共识。但是有时仍然会心存疑问,在具体的使用中应该选择哪一个,或者退一步讲,保守的只使用 weak 是不是一个好的选择呢?
本文首先对循环引用的基础知识做一个简要介绍,然后会分析 Swift 源代码的一些片段,讲解 unowned 和 weak 在生命周期和性能上的差异点,希望看完本文以后,在的使用场景中,能使用正确的弱引用类型。
目录:
从 GitHub 或者 zipped 获取本文相关的 Playground 代码。然后从这里获取闭包案例和 SIL,SILGen 以及 LLVM IR 的输出。
<a name="the_basic"></a>
基础知识
众所周知,Swift 利用古老并且有效的自动引用计数(ARC, Automatic Reference Counting)来管理内存,带来的后果和在 Objective-C 中使用的情况类似,需要手动使用弱引用来解决循环引用问题。
如果对 ARC 不了解,只需要知道的是,每一个引用类型实例都有一个引用计数与之关联,这个引用计数用来记录这个对象实例正在被变量或常量引用的总次数。当引用计数变为 0 时,实例将会被析构,实例占有的内存和资源都将变得重新可用。
当有两个实例通过某种形式互相引用时,就会形成循环引用(比如:两个类实例都有一个属性指向对方的类实例;双向链表中两个相邻的节点实例等...), 由于两个实例的引用计数都一直大于 0, 循环引用将会阻止这些实例的析构。
为了解决这个问题,和其他一些有类似问题的语言一样, 在 Swift 中,弱引用 的概念被提了出来,弱引用不会被 ARC 计算,也就是说,当一个弱引用指向一个引用类型实例时,引用计数不会增加。
弱引用不会阻止实例的析构, 只需要记住的是,在任何情况下,弱引用都不会拥有它指向的对象。在正式的场景中不是什么大问题,但是在我们处理这类引用的时候,需要意识到这一点。
在 Swift 中有 2 种 弱 引用形式,unowned 和 weak。
虽然它们的作用类似,但与它们相关实例生命周期的假设会略有不同,并且具有不同的性能特征。
为了举例说明循环引用,这里不使用大家期望看到的类之间的循环引用,而使用闭包的上下文案例,这在 Objective-C 日常开发中处理循环引用时经常会遇到的情况。和类的循环引用类似,通过创建一个强引用指向外部实例,或捕获它,阻止它析构。
在 Objective-C ,按照标准的做法,定义一个弱引用指向闭包外部的实例,然后在闭包内部定义强引用指向这个实例,在闭包执行期间使用它。当然,有必要在使用前检查引用的有效性。
为了更方便的处理循环引用,Swift 引入了一个新的概念,用于简化和更加明显地表达在闭包内部外部变量的捕获:捕获列表(capture list)。使用捕获列表,可以在函数的头部定义和指定那些需要用在内部的外部变量,并且指定引用类型(译者注:这里是指 unowned 和 weak)。
接下来举一些例子,在各种情况下捕获变量的表现。
当不使用捕获列表时,闭包将会创建一个外部变量的强引用:
var i1 = 1, i2 = 1
var fStrong = {
i1 += 1
i2 += 2
}
fStrong()
print(i1,i2) //Prints 2 and 3
闭包内部对变量的修改将会改变外部原始变量的值,这与预期是一致的。
使用捕获列表,闭包内部会创建一个新的可用常量。如果没有指定常量修饰符,闭包将会简单地拷贝原始值到新的变量中,对于值类型和引用类型都是一样的。
var fCopy = { [i1] in
print(i1,i2)
}
fStrong()
print(i1,i2) //打印结果是 2 和 3
fCopy() //打印结果是 1 和 3
在上面的例子中,在调用 fStrong 之前定义函数 fCopy ,在该函数定义的时候,私有常量已经被创建了。正如你所看到的,当调用第二个函数时候,仍然打印 i1 的原始值。
对于外部引用类型的变量,在捕获列表中指定 weak 或 unowned,这个常量将会被初始化为一个弱引用,指向原始值,这种指定的捕获方式就是用来处理循环引用的方式。
class aClass{
var value = 1
}
var c1 = aClass()
var c2 = aClass()
var fSpec = { [unowned c1, weak c2] in
c1.value += 1
if let c2 = c2 {
c2.value += 1
}
}
fSpec()
print(c1.value,c2.value) //Prints 2 and 2
两个 aClass 捕获实例的不同的定义方式,决定了它们在闭包中不同的使用方式。
unowned 引用使用的场景是,原始实例永远不会为 nil,闭包可以直接使用它,并且直接定义为显式解包可选值。当原始实例被析构后,在闭包中使用这个捕获值将导致崩溃。
如果捕获原始实例在使用过程中可能为 nil ,必须将引用声明为 weak, 并且在使用之前验证这个引用的有效性。
<a name="the_question_unowned_or_weak"></a>
问题来了: unowened 还是 weak?
在实际使用中如何选择这两种弱引用类型呢?
这个问题的答案可以简单由原始对象和引用它的闭包的生命周期来解释。
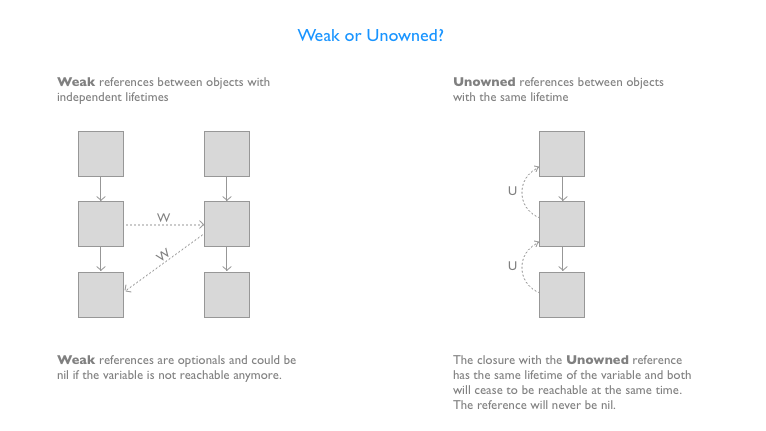
有两个可能出现的场景:
- 闭包和捕获对象的生命周期相同,所以对象可以被访问,也就意味着闭包也可以被访问。外部对象和闭包有相同的生命周期(比如:对象和它的父对象的简单返回引用)。在这种情况下,你应该把引用定义为 unowned。
一个经典的案例是: [unowned self], 主要用在闭包中,这种闭包主要在他们的父节点上下文中做一些事情,没有在其他地方被引用或传递,不能作用在父节点之外。
- 闭包的生命周期和捕获对象的生命周期相互独立,当对象不能再使用时,闭包依然能够被引用。这种情况下,你应该把引用定义为
weak,并且在使用它之前验证一下它是否为nil(请不要对它进行强制解包).
一个经典的案例是: [weak delegate = self.delegate!],可以在某些使用闭包的场景中看到,闭包使用的是完全无关(生命周期独立)的代理对象。
当无法确认两个对象之间生命周期的关系时,是否不应该去冒险选择一个无效 unowned 引用?而是保守选择 weak 引用是一个更好的选择?
答案是否定的,不仅仅是因为对象生命周期了解是一件必要的事情,而且这两个修饰符在性能特性上也有很大的不同。
弱引用最常见的实现是,每次一个新的引用生成时,都会把每个弱引用和它指向的对象信息存储到一个附加表中。
当没有任何强引用指向一个对象时,Swift 运行时会启动析构过程,但是在这之前,运行时会把所有相关的弱引用置为 nil 。弱引用的这种实现方式我们称之为"零和弱引用"。
这种实现有实际的开销,考虑到需要额外实现的数据结构,需要确保在并发访问情况下,对这个全局引用结构所有操作的正确性。一旦析构过程开始了,在任何环境中,都不允许访问弱引用所指向的对象了。
弱引用(包括 unowned 和一些变体的 weak)在 Swift 使用了更简单和快速的实现机制。
Swift 中的每个对象保持了两个引用计数器,一个是强引用计数器,用来决定 ARC 什么时候可以安全地析构这个对象,另外一个附加的弱引用计数器,用来计算创建了多少个指向这个对象的 unowned 或者 weak 引用,当这个计数器为零时,这个对象将被 析构 。
需要重点理解的是,只有等到所有 unowned 引用被释放后,这个对象才会被真正地析构,然后对象将会保持未解析可访问状态,当析构发生后,对象的内容才会被回收。
每当 unowned 引用被定义时,对应的 unowned 引用计数会进行原子级别地增加(使用原子gcc/llvm操作,进行一系列快速且线程安全的基本操作,例如:增加,减少,比较,交换等),以保证线程安全。在增加计数之前,会检查强引用计数以确保对象是有效的。
试图访问一个无效的对象,将会导致错误的断言,你的应用在运行时中会报错(这就是为什么这里的 unownd 实现方式叫做 unowned(safe) 实现)
为了更好的优化,应用编译时带有 -OFast,unowned 引用不会去验证引用对象的有效性,unowned 引用的行为就会像 Objective-C 中的 __unsafe_unretained 一样。如果引用对象无效,unowned 引用将会指向已经释放垃圾内存(这种实现称之 unowned(unsafe))。
当一个 unowned 引用被释放后,如果这时没有其他强引用或 unowned 引用指向这个对象,那么最终这个对象将被析构。这就是为什么一个引用对象不能在强引用计数器等于零的情况下,被析构的原因,所有的引用计数器必须能够被访问用来验证 unowned 引用和强引用数量。
Swift 的 weak 引用添加了附加层,间接地把 unowned 引用包裹到了一个可选容器里面,在指向的对象析构之后变成空的情况下,这样处理会更加的清晰。但是需要付出的代价是,附加的机制需要正确地处理可选值。
考虑到以上因素,在对象关系生命周期允许的情况下,优先选择使用 unowned 引用。但是这不是此故事的结局,接下来比较一下两者性能1上的差别。
<a name="performance_a_look_under_the_hood"></a>
性能:深度探索
在查看 Swift 项目源码验证之前,需要理解 ARC 如何管理这两种引用类型,并且还需要解释 swiftc,LLVM 和 SIL 的相关知识。
接下来试着简要介绍本文所需要的必备知识点,如果想了解更多,将在最后的脚注中找到一些有用的链接。
使用一个图来解释 swiftc 整个编译过程的包含的模块:
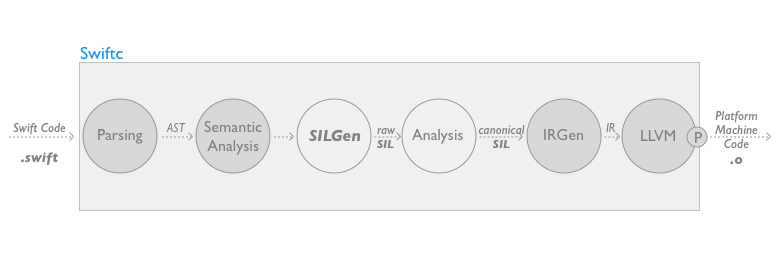
Swiftc 和 clang 一样构建在 LLVM 上,遵循 clang 编译器相似的编译流程。
在编译过程的第一部分,使用一个特定语言前端进行管理,swift 源代码被解释生成一个抽象语法树(AST)表达2,然后抽象语法树的结果从语义角度进行分析,找出语义错误。
在这个点上,对于其他的基于 LLVM 的编译器来讲,在通过一个附加步骤对源代码进行静态分析后(必要时可以显示错误和警告),接着 IRGen 模块 会把 AST 的内容会转换成一个轻量的和底层的机器无关的表示,我们称之为 LLVM IR(LLVM 中间表示)。
尽管两个模块都需要做一些相同检查,但是这两个模块是区分开的,在两个模块之间也存在许多重复的代码。
IR 是一种静态单赋值形式(SSA-form)一致语言,可以看做注入了 LLVM 的虚拟机下的 RISC 类型汇编语言。基于 SSA 将简化接下来的编译过程,从语言前端提供的中间表达会在 IR 进行多重优化。
需要重点注意的是,IR 其中一个特点是,它具有三种不同的形式:内存表达(内部使用),序列化位代码形式(你已经知道的位代码形式)和可读形式。
最后一种形式非常有用,用来验证 IR 代码的最终结构,这个结构将会传入到整个过程中的最后一步,将会从机器独立的 IR 代码转换成平台相关的表达(比如:x86,ARM 等等)。最后一步将被 LLVM 平台后端执行。
那么 swiftc 和其他基于 LLVM 的编译器有什么不同呢?
swiftc 和其他编译器从结构形式上的差别主要体现在一个附加组件,这个附加组件是 SILGen ,在 IRGen 之前,执行代码的监测和优化,生成一个高级的中间表达,我们称之为 SIL (Swift Intermediate Language,Swift 中间语言),最后 SIL 将会转换成 LLVM IR。这一步加强了在单个软件模块上所有具体语言的检查,并且简化了 IRGen。
从 AST 到 IR 的转换分为两个步骤。SILGen 把 AST 源代码转换为原始 SIL ,然后编译器进行 Swift 语法检查(需要时打印错误或者警告信息),优化有效的原始 SIL ,通过一些步骤最后生成标准化 SIL 。如上面的示意图显示那样,标准化 SIL 的最后转化为 LLVM IR。
再次强调,SIL 是一个 SSA 类型语言,使用附加的结构扩展了 Swift 的语法。它依赖 Swift 的类型系统,并且能理解 Swift 的定义,但是需要重点记住的是,当编译一个手写的 SIL 源码(是的,可以手动写 SIL 然后编译它)时,高阶的 Swift 代码或者函数内容将被编译器忽略。
在接下来的章节,我们将分析一个标准化 SIL 的案例,来理解 unowned 和 weak 引用如何被编译器处理。一个包含捕获列表的基本闭包的例子,查看这个例子生成的 SIL 代码,可以看到被编译器添加的所有 ARC 相关的函数调用。
从 GitHub 或者 zipped 获取本文相关的 Playground 代码。然后从这里获取闭包案例和
SIL,SILGen以及LLVM IR的输出。
<a name="deconstructing_capture_lists_handling"></a>
捕获列表处理解析
接下来看看一个简单的 Swift 的例子,定义两个类变量,然后在一个闭包中对他们进行弱引用的捕获:
class aClass{
var value = 1
}
var c1 = aClass()
var c2 = aClass()
var fSpec = {
[unowned c1, weak c2] in
c1.value = 42
if let c2o = c2 {
c2o.value = 42
}
}
fSpec()
通过 xcrun swiftc -emit-sil sample.swift 编译 swift 源代码,生成标准化 SIL 代码。原始SIL 可以使用 -emit-silgen 选项来生成。
运行以上命令以后,会发现 swiftc 产生了许多代码。通过查看 swiftc 输出代码的片段,学习一下基本的 SIL 指令,理解整个结构。
在下面代码中需要的地方添加了一些多行注释(编译器也生成了一些单行注释),希望这些注释已经足够说清楚发生了什么:
/*
此文件包含典型 SIL 代码
*/
sil_stage canonical
/*
只有在 SIL 内部使用的特殊的导入
*/
import Builtin
import Swift
import SwiftShims
/*
三个全局变量的定义,包括 c1,c2 和 闭包 fSpec。
@_Tv4clos2c1CS_6aClass是变量的符号,$aClass 是它的类型(类型前缀为$)。
变量名在这里看起来很乱,但是在后面的代码中将变得更加可读。
*/
// c1
sil_global hidden @_Tv4sample2c1CS_6aClass : $aClass
// c2
sil_global hidden @_Tv4sample2c2CS_6aClass : $aClass
// fSpec
sil_global hidden @_Tv4sample5fSpecFT_T_ : $@callee_owned () -> ()
...
/*
层次作用域定义表示原始代码的位置。
每个 SIL 指示将会指向它生成的 `sil_scope`。
*/
sil_scope 1 { parent @main : $@convention(c) (Int32, UnsafeMutablePointer<Optional<UnsafeMutablePointer<Int8>>>) -> Int32 }
sil_scope 2 { loc "sample.swift":14:1 parent 1 }
/*
自动生成的 @main 函数包含了我们原始全部作用域的代码。
这里沿用了熟悉的 c main() 函数结构,接收参数个数和参数数组两个输入,这个函数遵循 c 调用约定。
这个函数包含了需要调用闭包的指令。
*/
// main
sil @main : $@convention(c) (Int32, UnsafeMutablePointer<Optional<UnsafeMutablePointer<Int8>>>) -> Int32 {
/*
入口定义头部为 % 符号,后面跟随一个数字 id。
每当一个新的入口定义时(或者函数开头定义函数参数),编译器在入口行尾根据它的值(叫做 users)添加一个注释。
对于其他指令,需要提供 id 号。
在这里,入口 0 将被用来计算入口 4 的内容,入口 1 将被用来创建入口 10 的值。
*/
// %0 // user: %4
// %1 // user: %10
/*
每一个函数被分解成一系列的基本指令块,每一个指令块结束于一个终止指令(一个分支或者一个返回)。
这一系列的指令块表示函数所有可能的执行路径。
*/
bb0(%0 : $Int32, %1 : $UnsafeMutablePointer<Optional<UnsafeMutablePointer<Int8>>>):
...
/*
每一个 SIL 指令都包含一个引用,指向源代码的位置,包括指令具体从源代码中哪个地方来,属于哪一个作用域。
在后面分析具体的方法会看到这些内容。
*/
unowned_retain %27 : $@sil_unowned aClass, loc "sample.swift":9:14, scope 2 // id: %28
store %27 to %2 : $*@sil_unowned aClass, loc "sample.swift":9:14, scope 2 // id: %29
%30 = alloc_box $@sil_weak Optional<aClass>, var, name "c2", loc "sample.swift":9:23, scope 2 // users: %46, %44, %43, %31
%31 = project_box %30 : $@box @sil_weak Optional<aClass>, loc "sample.swift":9:23, scope 2 // user: %35
%32 = load %19 : $*aClass, loc "sample.swift":9:23, scope 2 // users: %34, %33
...
}
...
/*
下面是一系列自动生成的`aClass`的方法,包括: init/deinit, setter/getter 和其他一些工具方法。
每个方法前的注释是编译器添加的,用来说明代码的具体作用。
*/
/*
隐藏方法只在它们模块中可见。
@convention(方法名)是 Swift 中方法调用默认的约定,在尾部有一个附加的参数指向它自己。
*/
// aClass.__deallocating_deinit
sil hidden @_TFC4clos6aClassD : $@convention(method) (@owned aClass) -> () {
...
}
/*
@guaranteed 参数表示保证在整个周期内调用此方法都有效。
*/
// aClass.deinit
sil hidden @_TFC4clos6aClassd : $@convention(method) (@guaranteed aClass) -> @owned Builtin.NativeObject {
...
}
/*
[transparent] 修饰的方法是内联的小方法
*/
// aClass.value.getter
sil hidden [transparent] @_TFC4clos6aClassg5valueSi : $@convention(method) (@guaranteed aClass) -> Int {
...
}
// aClass.value.setter
sil hidden [transparent] @_TFC4clos6aClasss5valueSi : $@convention(method) (Int, @guaranteed aClass) -> () {
...
}
// aClass.value.materializeForSet
sil hidden [transparent] @_TFC4clos6aClassm5valueSi : $@convention(method) (Builtin.RawPointer, @inout Builtin.UnsafeValueBuffer, @guaranteed aClass) -> (Builtin.RawPointer, Optional<Builtin.RawPointer>) {
...
}
/*
@owned 修饰符表示这个对象将被调用者拥有。
*/
// aClass.init() -> aClass
sil hidden @_TFC4clos6aClasscfT_S0_ : $@convention(method) (@owned aClass) -> @owned aClass {
...
}
// aClass.__allocating_init() -> aClass
sil hidden @_TFC4clos6aClassCfT_S0_ : $@convention(method) (@thick aClass.Type) -> @owned aClass {
...
}
/*
接下面是闭包代码段
*/
// (closure #1)
sil shared @_TF4closU_FT_T_ : $@convention(thin) (@owned @sil_unowned aClass, @owned @box @sil_weak Optional<aClass>) -> () {
...
/* 关于闭包的 SIL 代码, 见下文 */
...
}
...
/*
sil_vtable 定义所有关于 aClass 类的虚函数表。
sil_vtable 包含了期望的所有自动生成的方法。
*/
sil_vtable aClass {
#aClass.deinit!deallocator: _TFC4clos6aClassD // aClass.__deallocating_deinit
#aClass.value!getter.1: _TFC4clos6aClassg5valueSi // aClass.value.getter
#aClass.value!setter.1: _TFC4clos6aClasss5valueSi // aClass.value.setter
#aClass.value!materializeForSet.1: _TFC4clos6aClassm5valueSi // aClass.value.materializeForSet
#aClass.init!initializer.1: _TFC4clos6aClasscfT_S0_ // aClass.init() -> aClass
}
现在回到主函数,看看两个类实例如何被获取到,并如何传递给调用他们的闭包。
在这里,所有标识都被重新整理,使得代码片段更加可读。
// main
sil @main : $@convention(c) (Int32, UnsafeMutablePointer<Optional<UnsafeMutablePointer<Int8>>>) -> Int32 {
// %0 // user: %4
// %1 // user: %10
bb0(%0 : $Int32, %1 : $UnsafeMutablePointer<Optional<UnsafeMutablePointer<Int8>>>):
...
/*
全局变量的引用使用三个入口来放置。
*/
%13 = global_addr @clos.c1 : $*aClass, loc "sample.swift":5:5, scope 1 // users: %26, %17
...
%19 = global_addr @clos.c2 : $*aClass, loc "sample.swift":6:5, scope 1 // users: %32, %23
...
%25 = global_addr @clos.fSpec : $*@callee_owned () -> (), loc "sample.swift":8:5, scope 1 // users: %48, %45
/*
c1 是 unowned_retained 的。
下面的指令增加变量的 unowned 引用计数。
*/
%26 = load %13 : $*aClass, loc "sample.swift":9:14, scope 2 // user: %27
%27 = ref_to_unowned %26 : $aClass to $@sil_unowned aClass, loc "sample.swift":9:14, scope 2 // users: %47, %38, %39, %29, %28
unowned_retain %27 : $@sil_unowned aClass, loc "sample.swift":9:14, scope 2 // id: %28
store %27 to %2 : $*@sil_unowned aClass, loc "sample.swift":9:14, scope 2 // id: %29
/*
对 c2 的处理会更加复杂一些。
alloc_box 创建了一个这个变量的引用数容器,变量将会存在这个容器的堆中。
容器创建以后,将会创建一个可选变量,指向 c2,并且可选变量会存储在容器里。容器会增加所包含值的技术,正如下面看到的一样,一旦容器被迁移,可选值就会被释放。
在这里,c2 的值将被存储在这个可选值中,对象将暂时strong_retained 然后释放。
*/
%30 = alloc_box $@sil_weak Optional<aClass>, var, name "c2", loc "sample.swift":9:23, scope 2 // users: %46, %44, %43, %31
%31 = project_box %30 : $@box @sil_weak Optional<aClass>, loc "sample.swift":9:23, scope 2 // user: %35
%32 = load %19 : $*aClass, loc "sample.swift":9:23, scope 2 // users: %34, %33
strong_retain %32 : $aClass, loc "sample.swift":9:23, scope 2 // id: %33
%34 = enum $Optional<aClass>, #Optional.some!enumelt.1, %32 : $aClass, loc "sample.swift":9:23, scope 2 // users: %36, %35
store_weak %34 to [initialization] %31 : $*@sil_weak Optional<aClass>, loc "sample.swift":9:23, scope 2 // id: %35
release_value %34 : $Optional<aClass>, loc "sample.swift":9:23, scope 2 // id: %36
/*
获取到闭包的引用。
*/
// function_ref (closure #1)
%37 = function_ref @sample.(closure #1) : $@convention(thin) (@owned @sil_unowned aClass, @owned @box @sil_weak Optional<aClass>) -> (), loc "sample.swift":8:13, scope 2 // user: %44
/*
c1 将被标记为 tagged,并且变量变为 unowned_retained。
*/
strong_retain_unowned %27 : $@sil_unowned aClass, loc "sample.swift":8:13, scope 2 // id: %38
%39 = unowned_to_ref %27 : $@sil_unowned aClass to $aClass, loc "sample.swift":8:13, scope 2 // users: %42, %40
%40 = ref_to_unowned %39 : $aClass to $@sil_unowned aClass, loc "sample.swift":8:13, scope 2 // users: %44, %41
unowned_retain %40 : $@sil_unowned aClass, loc "sample.swift":8:13, scope 2 // id: %41
strong_release %39 : $aClass, loc "sample.swift":8:13, scope 2 // id: %42
/*
包含 c2 的可选值容器是 strong_retained 的。
*/
strong_retain %30 : $@box @sil_weak Optional<aClass>, loc "sample.swift":8:13, scope 2 // id: %43
/*
创建一个闭包对象,绑定方法到参数中。
*/
%44 = partial_apply %37(%40, %30) : $@convention(thin) (@owned @sil_unowned aClass, @owned @box @sil_weak Optional<aClass>) -> (), loc "sample.swift":8:13, scope 2 // user: %45
store %44 to %25 : $*@callee_owned () -> (), loc "sample.swift":8:13, scope 2 // id: %45
/*
对 c1 和 c2 的容器变量进行释放(使用 对应匹配的 *_release 方法)。
*/
strong_release %30 : $@box @sil_weak Optional<aClass>, loc "sample.swift":14:1, scope 2 // id: %46
unowned_release %27 : $@sil_unowned aClass, loc "sample.swift":9:14, scope 2 // id: %47
/*
加载原先存储的闭包对象,增加强引用然后调用它。
*/
%48 = load %25 : $*@callee_owned () -> (), loc "sample.swift":17:1, scope 2 // users: %50, %49
strong_retain %48 : $@callee_owned () -> (), loc "sample.swift":17:1, scope 2 // id: %49
%50 = apply %48() : $@callee_owned () -> (), loc "sample.swift":17:7, scope 2
...
}
闭包有一个更加复杂的结构:
/*
闭包参数被标记为 @sil, 指定参数如何被计数,有一个 unowned 的 aClass 类变量 c2, 和另外一个包含 c2 的可选值容器。
*/
// (closure #1)
sil shared @clos.fSpec: $@convention(thin) (@owned @sil_unowned aClass, @owned @box @sil_weak Optional<aClass>) -> () {
// %0 // users: %24, %6, %5, %2
// %1 // users: %23, %3
/*
下面的函数包含三块,后面两块的执行依赖可选值 c2 具体的值。
*/
bb0(%0 : $@sil_unowned aClass, %1 : $@box @sil_weak Optional<aClass>):
...
/*
c1 被强计数。
*/
strong_retain_unowned %0 : $@sil_unowned aClass, loc "sample.swift":10:5, scope 17 // id: %5
%6 = unowned_to_ref %0 : $@sil_unowned aClass to $aClass, loc "sample.swift":10:5, scope 17 // users: %11, %10, %9
/*
使用内部自带包,传入一个整型字面量到整型结构中,初始化了一个值为 42 的整型值。
这个值将被设置为 c1 的新值,完成以后这个变量将会被释放。
在这里,我们第一次看到 class_method 指令,用于获取 vtable 中的函数引用。
*/
%7 = integer_literal $Builtin.Int64, 42, loc "sample.swift":10:16, scope 17 // user: %8
%8 = struct $Int (%7 : $Builtin.Int64), loc "sample.swift":10:16, scope 17 // user: %10
%9 = class_method %6 : $aClass, #aClass.value!setter.1 : (aClass) -> (Int) -> () , $@convention(method) (Int, @guaranteed aClass) -> (), loc "sample.swift":10:14, scope 17 // user: %10
%10 = apply %9(%8, %6) : $@convention(method) (Int, @guaranteed aClass) -> (), loc "sample.swift":10:14, scope 17
strong_release %6 : $aClass, loc "sample.swift":10:16, scope 17 // id: %11
/*
接下来讨论 c2。
获取可选值,然后根据它的内容执行接下来的分支语句。
If the optional has a value the bb2 block will be executed before jumping
to bb3, if it doesn't after a brief jump to bb1, the function will proceed to bb3 releasing
the retained parameters.
*/
%12 = load_weak %3 : $*@sil_weak Optional<aClass>, loc "sample.swift":11:18, scope 18 // user: %13
switch_enum %12 : $Optional<aClass>, case #Optional.some!enumelt.1: bb2, default bb1, loc "sample.swift":11:18, scope 18 // id: %13
bb1: // Preds: bb0
/*
跳转到闭包的结尾。
*/
br bb3, loc "sample.swift":11:18, scope 16 // id: %14
// %15 // users: %21, %20, %19, %16
bb2(%15 : $aClass): // Preds: bb0
/*
调用 aClass 的 setter,设置它的值为 42.
*/
...
%17 = integer_literal $Builtin.Int64, 42, loc "sample.swift":12:21, scope 19 // user: %18
%18 = struct $Int (%17 : $Builtin.Int64), loc "sample.swift":12:21, scope 19 // user: %20
%19 = class_method %15 : $aClass, #aClass.value!setter.1 : (aClass) -> (Int) -> () , $@convention(method) (Int, @guaranteed aClass) -> (), loc "sample.swift":12:19, scope 19 // user: %20
%20 = apply %19(%18, %15) : $@convention(method) (Int, @guaranteed aClass) -> (), loc "sample.swift":12:19, scope 19
strong_release %15 : $aClass, loc "sample.swift":13:5, scope 18 // id: %21
br bb3, loc "sample.swift":13:5, scope 18 // id: %22
bb3: // Preds: bb1 bb2
/*
释放所有获取的变量然后返回。
*/
strong_release %1 : $@box @sil_weak Optional<aClass>, loc "sample.swift":14:1, scope 17 // id: %23
unowned_release %0 : $@sil_unowned aClass, loc "sample.swift":14:1, scope 17 // id: %24
%25 = tuple (), loc "sample.swift":14:1, scope 17 // user: %26
return %25 : $(), loc "sample.swift":14:1, scope 17 // id: %26
}
在这里,忽略掉不同的 ARC 指令带来的性能的差异点,对不同阶段每种类型的捕获变量做一个快速的对比:
| 动作 | Unowned | Weak |
|---|---|---|
| 预先调用 #1 | 对象进行 unowned_retain 操作 | 创建一个容器,并且对象进行 strong_retain 操作。创建一个可选值,存入到容器中,然后释放可选值 |
| 预先调用 #2 | strong_retain_unowned,unowned_retain 和 strong_release | strong_retain |
| 闭包执行 | strong_retain_unowned,unowned_release | load_weak, 打开可选值, strong_release |
| 调用之后 | unowned_release | strong_release |
正如上面看到的 SIL 代码段那样,处理 weak 引用会涉及到更多的工作,因为需要处理引用需要的可选值。
参照官方文档的描述,这里对涉及到的所有 ARC 指令做一个简要的解释:
- unowned_retain:增加堆对象中的 unowned 引用计数。
- strong_retain_unowned :断言对象的强引用计数大于 0,然后增加这个引用计数。
- strong_retain:增加对象的强引用计数。
- load_weak:不是真正的 ARC 调用,但是它将增加可选值指向对象的强引用计数。
- strong_release:减少对象的强引用计数。如果释放操作把对象强引用计数变为0,对象将被销毁,然后弱引用将被清除。当整个强引用计数和 unowned 引用计数都为0时,对象的内存才会被释放。
- unowned_release:减少对象的 unowned 引用计数。当整个强引用计数和 unowned 引用计数都为 0 时,对象的内存才会被释放。
接下来深入到 Swift 运行时看看,这些指令都是如何被实现的,相关的代码文件有:HeapObject.cpp,HeapObject.h,RefCount.h 和 Heap.cpp、 SwiftObject.mm 中的少量定义。容器实现可以在 MetadataImpl.h 找到,但是本文不展开讨论。
这些文件中定义大多数的 ARC 方法都有三种变体,一种是对 Swift 对象的基础实现,另外两种实现是针对非原生 Swift 对象的:桥接对象和未知对象。后面两种变体这里不予讨论。
第一个讨论指令集和 unowned 引用相关。
在 HeapObject.cpp 文件中间可以看到对 unowned_retain 和 unowned_release 的实现方法:
SWIFT_RT_ENTRY_VISIBILITY
void swift::swift_unownedRetain(HeapObject *object)
SWIFT_CC(RegisterPreservingCC_IMPL) {
if (!object)
return;
object->weakRefCount.increment();
}
SWIFT_RT_ENTRY_VISIBILITY
void swift::swift_unownedRelease(HeapObject *object)
SWIFT_CC(RegisterPreservingCC_IMPL) {
if (!object)
return;
if (object->weakRefCount.decrementShouldDeallocate()) {
// Only class objects can be weak-retained and weak-released.
auto metadata = object->metadata;
assert(metadata->isClassObject());
auto classMetadata = static_cast<const ClassMetadata*>(metadata);
assert(classMetadata->isTypeMetadata());
SWIFT_RT_ENTRY_CALL(swift_slowDealloc)
(object, classMetadata->getInstanceSize(),
classMetadata->getInstanceAlignMask());
}
}
swift_unownedRetain 是 unowned_retain 的具体实现,简单地进行 unowned 引用计数的原子增加操作(这里定义为weakRefCount),swift_unownedRelease 更加复杂,原因之前也描述过,当没有其他 unowned 引用存在时,它需要执行对象的析构操作。
但是整体来讲都不复杂,在这里可以看到 doDecrementShouldDeallocate 方法,这个方法在上面代码中被一个命名类似的方法调用了。这个方法没有做太多,swift_slowDealloc 只是释放给定的指针。
到此已经有了一个对象的 unowned 引用,另外一个指令,strong_retain_unowned 用来创建一个强引用:
SWIFT_RT_ENTRY_VISIBILITY
void swift::swift_unownedRetainStrong(HeapObject *object)
SWIFT_CC(RegisterPreservingCC_IMPL) {
if (!object)
return;
assert(object->weakRefCount.getCount() &&
"object is not currently weakly retained");
if (! object->refCount.tryIncrement())
_swift_abortRetainUnowned(object);
}
因为弱引用应该指向了这个对象,要使用断言来验证对象是否被弱引用,一旦断言通过,将尝试进行增加强引用计数的操作。一旦对象在进程中已经被释放,尝试将会失败。
所有类似于 tryIncrement 通过某种形式修改引用计数的方法都放到 RefCount.h 中,需要使用原子操作进行这些任务。
接下来讨论下 weak 引用的的实现,正如之前看到的那样,swift_weakLoadStrong 用来获取容器中可选值中强引用的对象。
HeapObject *swift::swift_weakLoadStrong(WeakReference *ref) {
if (ref->Value == (uintptr_t)nullptr) {
return nullptr;
}
// ref 可能被其他线程访问
auto ptr = __atomic_fetch_or(&ref->Value, WR_READING, __ATOMIC_RELAXED);
while (ptr & WR_READING) {
short c = 0;
while (__atomic_load_n(&ref->Value, __ATOMIC_RELAXED) & WR_READING) {
if (++c == WR_SPINLIMIT) {
std::this_thread::yield();
c -= 1;
}
}
ptr = __atomic_fetch_or(&ref->Value, WR_READING, __ATOMIC_RELAXED);
}
auto object = (HeapObject*)(ptr & ~WR_NATIVE);
if (object == nullptr) {
__atomic_store_n(&ref->Value, (uintptr_t)nullptr, __ATOMIC_RELAXED);
return nullptr;
}
if (object->refCount.isDeallocating()) {
__atomic_store_n(&ref->Value, (uintptr_t)nullptr, __ATOMIC_RELAXED);
SWIFT_RT_ENTRY_CALL(swift_unownedRelease)(object);
return nullptr;
}
auto result = swift_tryRetain(object);
__atomic_store_n(&ref->Value, ptr, __ATOMIC_RELAXED);
return result;
}
在这个实现中,获取一个强引用需要更多复杂同步操作,在多线程竞争严重的情况下,会带来性能损耗。
在这里第一次出现的 WeakReference 对象,是一个简单的结构体,包含一个整型值字段指向目标对象,目标对象是使用 HeapObject 类来承载的每一个运行时的 Swift 对象。
在 weak 引用询问当前线程设置的 WR_READING 标识之后,从 WeakReference 容器中获取 Swift 对象,如果对象不再有效,或者在等待获取资源时,它变成可以进行析构,当前的引用会被设置为 null。
如果对象依然有效,获取对象的尝试将会成功。
因此,从这个角度来讲,对 weak 引用的常规操作性能比 unowned 引用的更低(但是主要的问题还是在可选值操作上面)。
<a name="conclusion"></a>
结论
保守的使用 weak 引用是否明智呢?答案是否定的,无论是从性能的角度还是代码清晰的角度而言。
使用正确的捕获修饰符类型,明确的表明代码中的生命周期特性,当其他人或者你自己在读你的代码时不容易误解。
<a name="footnotes"></a>
脚注
<a name="1"></a>
1、苹果第一次讨论 weak/unowned 争议可以查看这里,之后在 twitter 上 Joe Groff 对此也进行了讨论,并且被 Michael Tsai 总结成文。
这篇文章从意图角度出发,提供了完整并且可操作的解释。
<a name="2"></a>
2、从维基百科中可以找到关于 AST 的解释,还可以从 Slava Pestov 的这篇文章中看到关于 Swift 编译器中如何实现 AST 的一些细节。
<a name="3"></a>
3、*关于 SIL 的更多信息,请查看详尽的官方 SIL 指南,还有 2015 LLVM 开发者会议的视频。Lex Chou 写的 SIL 快速指南可以点击这里查看。 *
<a name="4"></a>
4、查看在 Swift 中如何进行名称粉碎(name mangling)的细节,请查看 Lex Chou 的这篇文章。
<a name="5"></a>
5、Mike Ash 在他的 Friday Q&A 中的一篇文章中讨论了如何实现 weak 引用的一种实践方法,这种方法与目前 Swift 的方法对比起来有一些过时,但是其中的解释依然值得参考。
本文由 SwiftGG 翻译组翻译,已经获得作者翻译授权,最新文章请访问 http://swift.gg。
