2.3 序列
译者:飞龙
序列是数据值的顺序容器。不像偶对只有两个元素,序列可以拥有任意(但是有限)个有序元素。
序列在计算机科学中是强大而基本的抽象。例如,如果我们使用序列,我们就可以列出伯克利的每个学生,或者世界上的每所大学,或者每所大学中的每个学生。我们可以列出上过的每一门课,提交的每个作业,或者得到的每个成绩。序列抽象让数千个数据驱动的程序影响着我们每天的生活。
序列不是特定的抽象数据类型,而是不同类型共有的一组行为。也就是说,它们是许多序列种类,但是都有一定的属性。特别地,
长度。序列拥有有限的长度。
元素选择。序列的每个元素都拥有相应的非负整数作为下标,它小于序列长度,以第一个元素的 0 开始。
不像抽象数据类型,我们并没有阐述如何构造序列。序列抽象是一组行为,它们并没有完全指定类型(例如,使用构造器和选择器),但是可以在多种类型中共享。序列提供了一个抽象层级,将特定程序如何操作序列类型的细节隐藏。
这一节中,我们开发了一个特定的抽象数据类型,它可以实现序列抽象。我们之后介绍实现相同抽象的 Python 内建类型。
2.3.1 嵌套偶对
对于有理数,我们使用二元组将两个整数对象配对,之后展示了我们可以同样通过函数来实现偶对。这种情况下,每个我们构造的偶对的元素都是整数。然而,就像表达式,元组可以嵌套。每个偶对的元素本身也可以是偶对,这个特性在实现偶对的任意一个方法,元组或调度函数中都有效。
可视化偶对的一个标准方法 -- 这里也就是偶对(1,2) -- 叫做盒子和指针记号。每个值,复合或原始,都描述为指向盒子的指针。原始值的盒子只包含那个值的表示。例如,数值的盒子只包含数字。偶对的盒子实际上是两个盒子:左边的部分(箭头指向的)包含偶对的第一个元素,右边的部分包含第二个。
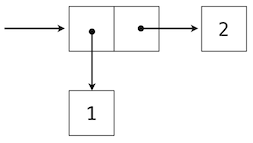
嵌套元素的 Python 表达式:
>>> ((1, 2), (3, 4))
((1, 2), (3, 4))
具有下面的结构:
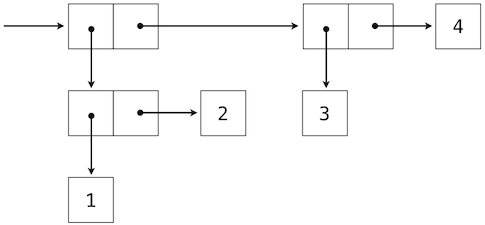
使用元组作为其它元组元素的能力,提供了我们编程语言中的一个新的组合手段。我们将这种将元组以这种方式嵌套的能力叫做元组数据类型的封闭性。通常,如果组合结果自己可以使用相同的方式组合,组合数据值的方式就满足封闭性。封闭性在任何组合手段中都是核心能力,因为它允许我们创建层次数据结构 -- 结构由多个部分组成,它们自己也由多个部分组成,以此类推。我们在第三章会探索一些层次结构。现在,我们考虑一个特定的重要结构。
2.3.2 递归列表
我们可以使用嵌套偶对来构建任意长度的元素列表,它让我们能够实现抽象序列。下面的图展示了四元素列表1, 2, 3, 4的递归表示:
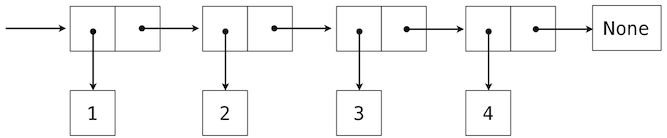
这个列表由一系列偶对表示。每个偶对的第一个元素是列表中的元素,而第二个元素是用于表示列表其余部分的偶对。最后一个偶对的第二个元素是None,它表明列表到末尾了。我们可以使用嵌套的元组字面值来构造这个结构:
>>> (1, (2, (3, (4, None))))
(1, (2, (3, (4, None))))
这个嵌套的结构通常对应了一种非常实用的序列思考方式,我们在 Python 解释器的执行规则中已经见过它了。一个非空序列可以划分为:
- 它的第一个元素,以及
- 序列的其余部分。
序列的其余部分本身就是一个(可能为空的)序列。我们将序列的这种看法叫做递归,因为序列包含其它序列作为第二个组成部分。
由于我们的列表表示是递归的,我们在实现中叫它rlist,以便不会和 Python 内建的list类型混淆,我们会稍后在这一章介绍它。一个递归列表可以由第一个元素和列表的剩余部分构造。None值表示空的递归列表。
>>> empty_rlist = None
>>> def make_rlist(first, rest):
"""Make a recursive list from its first element and the rest."""
return (first, rest)
>>> def first(s):
"""Return the first element of a recursive list s."""
return s[0]
>>> def rest(s):
"""Return the rest of the elements of a recursive list s."""
return s[1]
这两个选择器和一个构造器,以及一个常量共同实现了抽象数据类型的递归列表。递归列表唯一的行为条件是,就像偶对那样,它的构造器和选择器是相反的函数。
- 如果一个递归列表
s由元素f和列表r构造,那么first(s)返回f,并且rest(s)返回r。
我们可以使用构造器和选择器来操作递归列表。
>>> counts = make_rlist(1, make_rlist(2, make_rlist(3, make_rlist(4, empty_rlist))))
>>> first(counts)
1
>>> rest(counts)
(2, (3, (4, None)))
递归列表可以按序储存元素序列,但是它还没有实现序列的抽象。使用我们已经定义的数据类型抽象,我们就可以实现描述两个序列的行为:长度和元素选择。
>>> def len_rlist(s):
"""Return the length of recursive list s."""
length = 0
while s != empty_rlist:
s, length = rest(s), length + 1
return length
>>> def getitem_rlist(s, i):
"""Return the element at index i of recursive list s."""
while i > 0:
s, i = rest(s), i - 1
return first(s)
现在,我们可以将递归列表用作序列了:
>>> len_rlist(counts)
4
>>> getitem_rlist(counts, 1) # The second item has index 1
2
两个实现都是可迭代的。它们隔离了嵌套偶对的每个层级,直到列表的末尾(在len_rlist中),或者到达了想要的元素(在getitem_rlist中)。
下面的一系列环境图示展示了迭代过程,getitem_rlist通过它找到了递归列表中下标1中的元素2。
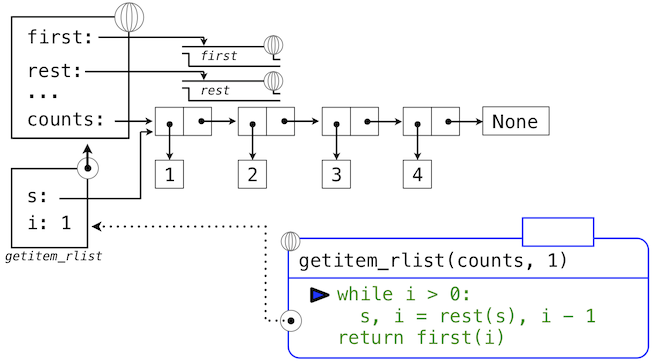
while头部中的表达式求值为真,这会导致while语句组中的赋值语句被执行:
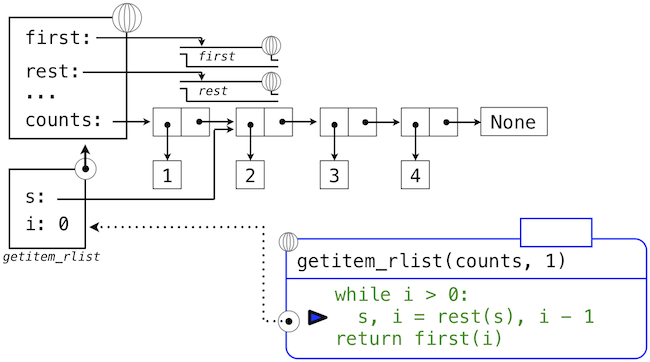
这里,局部名称s现在指向以原列表第二个元素开始的子列表。现在,while头中的表达式求值为假,于是 Python 会求出getitem_rlist最后一行中返回语句中的表达式。
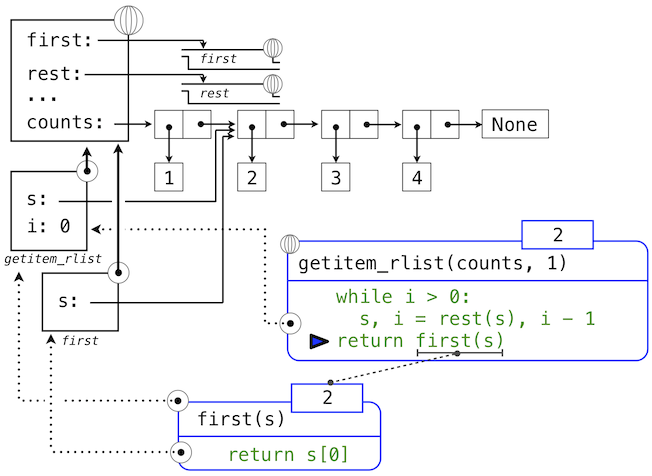
最后的环境图示展示了调用first的局部帧,它包含绑定到相同子列表的s。first函数挑选出值2并返回了它,完成了getitem_rlist的调用。
这个例子演示了递归列表计算的常见模式,其中迭代的每一步都操作原列表的一个逐渐变短的后缀。寻找递归列表的长度和元素的渐进式处理过程需要一些时间来计算。(第三章中,我们会学会描述这种函数的计算时间。)Python 的内建序列类型以不同方式实现,它对于计算序列长度和获取元素并不具有大量的计算开销。
2.3.2 元组 II
实际上,我们引入用于形成原始偶对的tuple类型本身就是完整的序列类型。元组比起我们以函数式实现的偶对抽象数据结构,本质上提供了更多功能。
元组具有任意的长度,并且也拥有序列抽象的两个基本行为:长度和元素选择。下面的digits是一个四元素元组。
>>> digits = (1, 8, 2, 8)
>>> len(digits)
4
>>> digits[3]
8
此外,元素可以彼此相加以及与整数相乘。对于元组,加法和乘法操作并不对元素相加或相乘,而是组合和重复元组本身。也就是说,operator模块中的add函数(以及+运算符)返回两个被加参数连接成的新元组。operator模块中的mul函数(以及*运算符)接受整数k和元组,并返回含有元组参数k个副本的新元组。
>>> (2, 7) + digits * 2
(2, 7, 1, 8, 2, 8, 1, 8, 2, 8)
映射。将一个元组变换为另一个元组的强大手段是在每个元素上调用函数,并收集结果。这一计算的常用形式叫做在序列上映射函数,对应内建函数map。map的结果是一个本身不是序列的对象,但是可以通过调用tuple来转换为序列。它是元组的构造器。
>>> alternates = (-1, 2, -3, 4, -5)
>>> tuple(map(abs, alternates))
(1, 2, 3, 4, 5)
map函数非常重要,因为它依赖于序列抽象:我们不需要关心底层元组的结构,只需要能够独立访问每个元素,以便将它作为参数传入用于映射的函数中(这里是abs)。
2.3.4 序列迭代
映射本身就是通用计算模式的一个实例:在序列中迭代所有元素。为了在序列上映射函数,我们不仅仅需要选择特定的元素,还要依次选择每个元素。这个模式非常普遍,Python 拥有额外的控制语句来处理序列数据:for语句。
考虑一个问题,计算一个值在序列中出现了多少次。我们可以使用while循环实现一个函数来计算这个数量。
>>> def count(s, value):
"""Count the number of occurrences of value in sequence s."""
total, index = 0, 0
while index < len(s):
if s[index] == value:
total = total + 1
index = index + 1
return total
>>> count(digits, 8)
2
Python for语句可以通过直接迭代元素值来简化这个函数体,完全不需要引入index。例如(原文是For example,为双关语),我们可以写成:
>>> def count(s, value):
"""Count the number of occurrences of value in sequence s."""
total = 0
for elem in s:
if elem == value:
total = total + 1
return total
>>> count(digits, 8)
2
for语句按照以下过程来执行:
- 求出头部表达式
<expression>,它必须产生一个可迭代的值。 - 对于序列中的每个元素值,按顺序:
- 在局部环境中将变量名
<name>绑定到这个值上。 - 执行语句组
<suite>。
- 在局部环境中将变量名
步骤 1 引用了可迭代的值。序列是可迭代的,它们的元素可看做迭代的顺序。Python 的确拥有其他可迭代类型,但是我们现在只关注序列。术语“可迭代对象”的一般定义会在第四章的迭代器一节中出现。
这个求值过程的一个重要结果是,在for语句执行完毕之后,<name>会绑定到序列的最后一个元素上。这个for循环引入了另一种方式,其中局部环境可以由语句来更新。
序列解构。程序中的一个常见模式是,序列的元素本身就是序列,但是具有固定的长度。for语句可在头部中包含多个名称,将每个元素序列“解构”为各个元素。例如,我们拥有一个偶对(也就是二元组)的序列:
>>> pairs = ((1, 2), (2, 2), (2, 3), (4, 4))
下面的for语句的头部带有两个名词,会将每个名称x和y分别绑定到每个偶对的第一个和第二个元素上。
>>> for x, y in pairs:
if x == y:
same_count = same_count + 1
>>> same_count
2
这个绑定多个名称到定长序列中多个值的模式,叫做序列解构。它的模式和我们在赋值语句中看到的,将多个名称绑定到多个值的模式相同。
范围。range是另一种 Python 的内建序列类型,它表示一个整数范围。范围可以使用range函数来创建,它接受两个整数参数:所得范围的第一个数值和最后一个数值加一。
>>> range(1, 10) # Includes 1, but not 10
range(1, 10)
在范围上调用tuple构造器会创建与范围具有相同元素的元组,使元素易于查看。
>>> tuple(range(5, 8))
(5, 6, 7)
如果只提供了一个元素,它会解释为最后一个数值加一,范围开始于 0。
>>> total = 0
>>> for k in range(5, 8):
total = total + k
>>> total
18
常见的惯例是将单下划线字符用于for头部,如果这个名称在语句组中不会使用。
>>> for _ in range(3):
print('Go Bears!')
Go Bears!
Go Bears!
Go Bears!
要注意对解释器来说,下划线只是另一个名称,但是在程序员中具有固定含义,它表明这个名称不应出现在任何表达式中。
2.3.5 序列抽象
我们已经介绍了两种原生数据类型,它们实现了序列抽象:元组和范围。两个都满足这一章开始时的条件:长度和元素选择。Python 还包含了两种序列类型的行为,它们扩展了序列抽象。
成员性。可以测试一个值在序列中的成员性。Python 拥有两个操作符in和not in,取决于元素是否在序列中出现而求值为True和False。
>>> digits
(1, 8, 2, 8)
>>> 2 in digits
True
>>> 1828 not in digits
True
所有序列都有叫做index和count的方法,它会返回序列中某个值的下标(或者数量)。
切片。序列包含其中的子序列。我们在开发我们的嵌套偶对实现时观察到了这一点,它将序列切分为它的第一个元素和其余部分。序列的切片是原序列的任何部分,由一对整数指定。就像range构造器那样,第一个整数表示切片的起始下标,第二个表示结束下标加一。
Python 中,序列切片的表示类似于元素选择,使用方括号。冒号分割了起始和结束下标。任何边界上的省略都被当作极限值:起始下标为 0,结束下标是序列长度。
>>> digits[0:2]
(1, 8)
>>> digits[1:]
(8, 2, 8)
Python 序列抽象的这些额外行为的枚举,给我们了一个机会来反思数据抽象通常由什么构成。抽象的丰富性(也就是说它包含行为的多少)非常重要。对于使用抽象的用户,额外的行为很有帮助,另一方面,满足新类型抽象的丰富需求是个挑战。为了确保我们的递归列表实现支持这些额外的行为,需要一些工作量。另一个抽象丰富性的负面结果是,它们需要用户长时间学习。
序列拥有丰富的抽象,因为它们在计算中无处不在,所以学习一些复杂的行为是合理的。通常,多数用户定义的抽象应该尽可能简单。
扩展阅读。切片符号接受很多特殊情况,例如负的起始值,结束值和步长。Dive Into Python 3 中有一节叫做列表切片,完整描述了它。这一章中,我们只会用到上面描述的基本特性。
2.3.6 字符串
文本值可能比数值对计算机科学来说更基本。作为一个例子,Python 程序以文本编写和储存。Python 中原生的文本数据类型叫做字符串,相应的构造器是str。
关于字符串在 Python 中如何表示和操作有许多细节。字符串是丰富抽象的另一个示例,程序员需要满足一些实质性要求来掌握。这一节是字符串基本行为的摘要。
字符串字面值可以表达任意文本,被单引号或者双引号包围。
>>> 'I am string!'
'I am string!'
>>> "I've got an apostrophe"
"I've got an apostrophe"
>>> '您好'
'您好'
我们已经在代码中见过字符串了,在print的调用中作为文档字符串,以及在assert语句中作为错误信息。
字符串满足两个基本的序列条件,我们在这一节开始介绍过它们:它们拥有长度并且支持元素选择。
>>> city = 'Berkeley'
>>> len(city)
8
>>> city[3]
'k'
字符串的元素本身就是包含单一字符的字符串。字符是字母表中的任意单一字符,标点符号,或者其它符号。不像许多其它编程语言那样,Python 没有单独的字符类型,任何文本都是字符串,表示单一字符的字符串长度为 1、
就像元组,字符串可以通过加法和乘法来组合:
>>> city = 'Berkeley'
>>> len(city)
8
>>> city[3]
'k'
字符串的行为不同于 Python 中其它序列类型。字符串抽象没有实现我们为元组和范围描述的完整序列抽象。特别地,字符串上实现了成员性运算符in,但是与序列上的实现具有完全不同的行为。它匹配子字符串而不是元素。
>>> 'here' in "Where's Waldo?"
True
与之相似,字符串上的count和index方法接受子串作为参数,而不是单一字符。count的行为有细微差别,它统计字符串中非重叠字串的出现次数。
>>> 'Mississippi'.count('i')
4
>>> 'Mississippi'.count('issi')
1
多行文本。字符串并不限制于单行文本,三个引号分隔的字符串字面值可以跨越多行。我们已经在文档字符串中使用了三个引号。
>>> """The Zen of Python
claims, Readability counts.
Read more: import this."""
'The Zen of Python\nclaims, "Readability counts."\nRead more: import this.'
在上面的打印结果中,\n(叫做“反斜杠加 n”)是表示新行的单一元素。虽然它表示为两个字符(反斜杠和 n)。它在长度和元素选择上被认为是单个字符。
字符串强制。字符串可以从 Python 的任何对象通过以某个对象值作为参数调用str构造函数来创建,这个字符串的特性对于从多种类型的对象中构造描述性字符串非常实用。
>>> str(2) + ' is an element of ' + str(digits)
'2 is an element of (1, 8, 2, 8)'
str函数可以以任何类型的参数调用,并返回合适的值,这个机制是后面的泛用函数的主题。
方法。字符串在 Python 中的行为非常具有生产力,因为大量的方法都返回字符串的变体或者搜索其内容。一部分这些方法由下面的示例介绍。
>>> '1234'.isnumeric()
True
>>> 'rOBERT dE nIRO'.swapcase()
'Robert De Niro'
>>> 'snakeyes'.upper().endswith('YES')
True
扩展阅读。计算机中的文本编码是个复杂的话题。这一章中,我们会移走字符串如何表示的细节,但是,对许多应用来说,字符串如何由计算机编码的特定细节是必要的知识。Dive Into Python 3 的 4.1 ~ 4.3 节提供了字符编码和 Unicode 的描述。
2.3.7 接口约定
在复合数据的处理中,我们强调了数据抽象如何让我们设计程序而不陷入数据表示的细节,以及抽象如何为我们保留灵活性来尝试备用表示。这一节中,我们引入了另一种强大的设计原则来处理数据结构 -- 接口约定的用法。
接口约定使在许多组件模块中共享的数据格式,它可以混合和匹配来展示数据。例如,如果我们拥有多个函数,它们全部接受序列作为参数并且返回序列值,我们就可以把它们每一个用于上一个的输出上,并选择任意一种顺序。这样,我们就可以通过将函数链接成流水线,来创建一个复杂的过程,每个函数都是简单而专一的。
这一节有两个目的,来介绍以接口约定组织程序的概念,以及展示模块化序列处理的示例。
考虑下面两个问题,它们首次出现,并且只和序列的使用相关。
- 对前
n个斐波那契数中的偶数求和。 - 列出一个名称中的所有缩写字母,它包含每个大写单词的首字母。
这些问题是有关系的,因为它们可以解构为简单的操作,它们接受序列作为输入,并产出序列作为输出。而且,这些操作是序列上的计算的一般方法的实例。让我们思考第一个问题,它可以解构为下面的步骤:
enumerate map filter accumulate
----------- --- ------ ----------
naturals(n) fib iseven sum
下面的fib函数计算了斐波那契数(现在使用了for语句更新了第一章中的定义)。
>>> def fib(k):
"""Compute the kth Fibonacci number."""
prev, curr = 1, 0 # curr is the first Fibonacci number.
for _ in range(k - 1):
prev, curr = curr, prev + curr
return curr
谓词iseven可以使用整数取余运算符%来定义。
>>> def iseven(n):
return n % 2 == 0
map和filter函数是序列操作,我们已经见过了map,它在序列中的每个元素上调用函数并且收集结果。filter函数接受序列,并且返回序列中谓词为真的元素。两个函数都返回间接对象,map和filter对象,它们是可以转换为元组或求和的可迭代对象。
>>> nums = (5, 6, -7, -8, 9)
>>> tuple(filter(iseven, nums))
(6, -8)
>>> sum(map(abs, nums))
35
现在我们可以实现even_fib,第一个问题的解,使用map、filter和sum。
>>> def sum_even_fibs(n):
"""Sum the first n even Fibonacci numbers."""
return sum(filter(iseven, map(fib, range(1, n+1))))
>>> sum_even_fibs(20)
3382
现在,让我们思考第二个问题。它可以解构为序列操作的流水线,包含map和filter。
enumerate filter map accumulate
--------- ------ ----- ----------
words iscap first tuple
字符串中的单词可以通过字符串对象上的split方法来枚举,默认以空格分割。
>>> tuple('Spaces between words'.split())
('Spaces', 'between', 'words')
单词的第一个字母可以使用选择运算符来获取,确定一个单词是否大写的谓词可以使用内建谓词isupper定义。
>>> def first(s):
return s[0]
>>> def iscap(s):
return len(s) > 0 and s[0].isupper()\
这里,我们的缩写函数可以使用map和filter定义。
>>> def acronym(name):
"""Return a tuple of the letters that form the acronym for name."""
return tuple(map(first, filter(iscap, name.split())))
>>> acronym('University of California Berkeley Undergraduate Graphics Group')
('U', 'C', 'B', 'U', 'G', 'G')
这些不同问题的相似解法展示了如何使用通用的计算模式,例如映射、过滤和累计,来组合序列的接口约定上的操作。序列抽象让我们编写出这些简明的解法。
将程序表达为序列操作有助于我们设计模块化的程序。也就是说,我们的设计由组合相关的独立片段构建,每个片段都对序列进行转换。通常,我们可以通过提供带有接口约定的标准组件库来鼓励模块化设计,接口约定以灵活的方式连接这些组件。
生成器表达式。Python 语言包含第二个处理序列的途径,叫做生成器表达式。它提供了与map和reduce相似的功能,但是需要更少的函数定义。
生成器表达式组合了过滤和映射的概念,并集成于单一的表达式中,以下面的形式:
<map expression> for <name> in <sequence expression> if <filter expression>
为了求出生成器表达式,Python 先求出<sequence expression>,它必须返回一个可迭代值。之后,对于每个元素,按顺序将元素值绑定到<name>,求出过滤器表达式,如果它产生真值,就会求出映射表达式。
生成器表达式的求解结果值本身是个可迭代值。累计函数,比如tuple、sum、max和min可以将返回的对象作为参数。
>>> def acronym(name):
return tuple(w[0] for w in name.split() if iscap(w))
>>> def sum_even_fibs(n):
return sum(fib(k) for k in range(1, n+1) if fib(k) % 2 == 0)
生成器表达式是使用可迭代(例如序列)接口约定的特化语法。这些表达式包含了map和filter的大部分功能,但是避免了被调用函数的实际创建(或者,顺便也避免了环境帧的创建需要调用这些函数)。
归约。在我们的示例中,我们使用特定的函数来累计结果,例如tuple或者sum。函数式编程语言(包括 Python)包含通用的高阶累加器,具有多种名称。Python 在functools模块中包含reduce,它对序列中的元素从左到右依次调用二元函数,将序列归约为一个值。下面的表达式计算了五个因数的积。
>>> from operator import mul
>>> from functools import reduce
>>> reduce(mul, (1, 2, 3, 4, 5))
120
使用这个更普遍的累计形式,除了求和之外,我们也可以计算斐波那契数列中奇数的积,将序列用作接口约定。
>>> def product_even_fibs(n):
"""Return the product of the first n even Fibonacci numbers, except 0."""
return reduce(mul, filter(iseven, map(fib, range(2, n+1))))
>>> product_even_fibs(20)
123476336640
与map、filter和reduce对应的高阶过程的组合会再一次在第四章出现,在我们思考多台计算机之间的分布式计算方法的时候。
