15分钟成为 GIT 专家
通过一步一步的实践来探索 git 内部。

Git 可能看起来像一个复杂的系统。如果上 Googl e搜索。Google 会自动弹出一些最常搜索的标题:
为什么 Git 这么难。。。
Git 就是太难了。。。
我们能够停止假装 Git 很简单、很容易学习吗。。。
为什么 Git 如此复杂。。。
乍一看,这些问题好像都是真的,但是你一旦理解了内部的概念,使用 Git 工作会变成一件愉悦的体验。Git 的问题是它非常灵活。所有灵活的系统的特点就是复杂。我强烈的认为解决其复杂性的唯一办法就是深入它提供的用户接口下面,理解内部的模型和架构。一旦你这么做了,就不会有什么魔力和非预期的结果。使用起这些复杂的工具得心应手。
不管是以前使用过 Git 还是刚开始使用这个神奇的版本控制工具的开发者,阅读了本文以后都会收获颇丰。如果你是应一名有经验的 GIT 使用者,你会更好的理解 checkout -> modify -> commit 这个过程。如果你刚开始使用 Git,本文将给你一个很好的开端。
在本文中我将使用一些底层的命令来展示 Git 内部是怎么工作的。你不需要记住这些命令,因为在常规的工作流中几乎不会使用这些命令,但是这些命令在解释 Git 内部架构时不可或缺。
本文比较长,我相信你会按照以下两种方式阅读:
- 快速从顶部滑底部,看一下本文的目录标题
- 跟着本文的练习完整阅读本文
通过练习你可以增强在这里获得的信息。
Git 是一个文件夹
当你在一个文件夹中执行 git init 命令时,Git 会创建 .git 目录。所以我们打开一个终端,创建一个新的目录并在这里初始化一个空的 git 仓库:
$ mkdir git-playground && cd git-playground
$ git init
Initialized empty Git repository in path/to/git-playground/.git/
$ ls .git
HEAD config description hooks info objects refs
这是 Git 存储所有 commit 和其他用于操作这些 commit 相关信息的地方。当你克隆一个仓库的时候就是复制这个目录到你的文件夹,为仓库里的每一个分支创建一个远程跟踪分支,并根据 HEAD 文件检出一个初始的分支。我们将在稍后讨论在 Git 架构中 HEAD 文件的用途,但是这里需要记住的就是克隆一个仓库本质上就是仅仅从别的地方复制一份 .git 目录。
Git 是一个数据库
Git 是一个简单的 key-value 数据仓库。你可以将数据存储到仓库中并获得一个键值,通过这个键值你可以访问存储的数据。将数据存储到数据库的命令是 hash-object,这个命令会返回一个40个字符的哈希校验和,这个校验和会被用作键值。这个命令会在 git 仓库中创建一个称为 blob 的对象。我们向数据库中写入一个简单的字符串 f1 content :
$ F1CONTENT_BLOB_HASH=$( \
echo 'f1 content' | git hash-object -w --stdin )
$ echo $F1CONTENT_BLOB_HASH
a1deaae8f9ac984a5bfd0e8eecfbafaf4a90a3d0
如果你对 shell 不熟悉,上面这一段代码的主要命令是:
echo 'f1 content' | git hash-object -w --stdin
echo 命令输出 f1 content 字符串,通过管道操作符 | 我们将输出重定位到 git hash-object 命令。hash-object 的参数 -w 表示要存储这个对象;否则这个命令只是简单的告诉你键值是什么。 --stdin 告诉命令从 stdin 读取内容;如果不指定这一点, hash-object 希望最后输入一个文件路径。前面已经说到 git hash-object 命令会返回一个哈希值,我将这个值存储到 F1CONTENT_BLOB_HASH变量中。我们也可以将主命令和变量赋值像这样分开:
$ echo 'f1 content' | git hash-object -w --stdin
a1deaae8f9ac984a5bfd0e8eecfbafaf4a90a3d0
$ F1CONTENT_BLOB_HASH=a1deaae8f9ac984a5bfd0e8eecfbafaf4a90a3d0
但是为了方便,我将在后面的代码中使用简短的版本为变量赋值。这些变量会在需要哈希字符串的地方使用,它和 $ 符号拼接起来作为一个变量读取存储的数据。
通过键值读取数据可以使用 带有 -p 选项的 cat-file 命令。这个命令需要接收带读取数据的哈希值:
如我前面所说, .git 是一个文件夹,并且所有存储的值/对象都放在这个文件夹中。所以我们可以浏览一下 .git/objects 文件夹,你会看到 Git 创建了一个名称为 a1 的文件夹,这是哈希值的前两个字母:
$ ls .git/objects/ -l
**a1/**
info/
pack/
这就是 Git 存储对象的方式--每个 blob 一个文件夹。然而,Git 也可以将多个 blob 合并成一个文件生成一个 pack 文件,这些 pack 文件就存储在你前面看到的 pack 目录。Git 将这些 pack 对象相关的信息都存储到 info 目录。Git 基于 blob 的内容为每一个 blob 生成哈希值,所以存储在 Git 中的对象是不可修改的,因为修改内容就会改变哈希值。
我们往仓库中写入另外一个字符串 f2 content:
$ F2CONTENT_BLOB_HASH=$( \
**echo 'f2 content' | git hash-object -w --stdin )**
如你所预期的那样,你会看到 .git/objects/ 目录下现在有两条记录 9b/ 和 a1/ :
$ ls .git/objects/ -l
**9b/**
**a1/ **
info/
pack/
树(Tree)是一个内部组件
现在我们的仓库中有两个blob:
F1CONTENT_BLOB_HASH -> ‘f1 content’
F2CONTENT_BLOB_HASH -> ‘f2 content'
我们需要一种方式来将他们组织到一起,并且将每一个 blob 和一个文件名关联起来。这就是 tree 的作用。我们可以按照下面的语法通过 git mktree 为从而每一个 blob/文件 关联创建一个树:
[file-mode object-type object-hash file-name]
关于文件的 file mode 可以参考这个答案提供的解释。我们将使用 100644 模式,这一模式下 blob 就是一个常规文件每一个用户都可以读写。当检出文件到工作目录时,Git 会根据 tree 实体将相应的文件/目录设置成这个模式。
所以,这样就可以将两个 blob 和两个文件建立关联:
$ INITIAL_TREE_HASH=$( \
printf '%s %s %s\t%s\n' \
100644 blob $F1CONTENT_BLOB_HASH f1.txt \
100644 blob $F2CONTENT_BLOB_HASH f2.txt |
git mktree )
和 hash-object 一样,mktree 命令也会返回创建好的树对象的哈希值:
$ echo $INITIAL_TREE_HASH
e05d9daa03229f7a7f6456d3d091d0e685e6a9db
所以,现在我们的仓库中有这样一个树:

运行这个命令之后,git 在仓库中创建了第三个 tree 类型的对象。我们一起来看看:
$ ls .git/objects -l
e0 <--- initial tree object (INITIAL_TREE_HASH)
9b <--- 'f1 content' blob (F2CONTENT_BLOB_HASH)
a1 <--- 'f2 content' blob (F2CONTENT_BLOB_HASH)
当使用 mktree 命令的时候,我们也可以指定另外一个树对象(而不是一个 blob)作为参数。新创建的树会和目录而不是一个常规文件关联。例如,下面的命令会根据一个 subtree 创建一个和 nested-folder 目录关联的树:
printf ‘%s %s %s\t%s\n’ 040000 tree e05d9da nested-folder | git mktree
文件模式 040000 表明是一个目录,并且我们使用的类型 tree 而不是 blob。这就是 git 在项目结构中存储嵌套目录的方式。
Index 是安装树的地方
每一个使用 GIT 工作的人都应该很熟悉 index 或者 staging 区这两个概念,并且可能看到过这张图片:
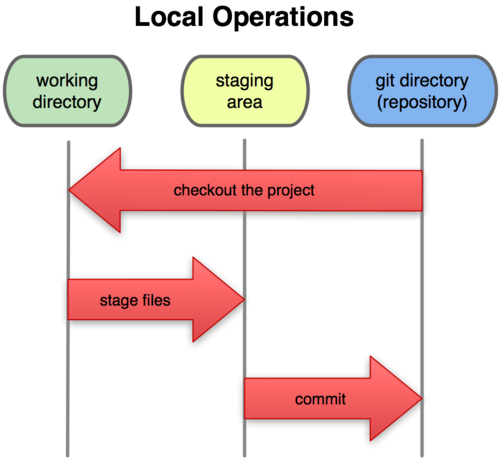
在右侧你可以看到 git repository,它用于存储 git 对象:blobs,trees,commits 和 tags。我们已经使用 hash-object 和 mktee 命令直接向仓库中添加了两个 blob 和一个树对象到仓库中。左侧的工作目录是你本地的文件系统(目录),也就是你检出所有项目文件的地方。中间这个区域我们称为 index 文件或者简称 index。它是一个二进制文件(通常存储在 .git/index),类似于树对象的结构。它持有一个排序好的文件路径列表,每一个文件路径都有权限以及 blob/tree 对象的 SHA1 值。
在这个地方,git 在作如下操作之前准备一个树:
- 将一个树写入仓库,或者
- 将一个树检出到工作目录
现在我们的仓库中已经有一个在上一章节创建的树。我们现在可以使用 read-tree 命令将这个树从仓库中读取到 index 文件:
$ git read-tree $INITIAL_TREE_HASH
所以现在我们期望 index 文件中有两个文件。我们可以使用 git ls-files -s 命令来检查当前 index 文件的结构:
$ git ls-files -s
100644 a1deaae8f9ac984a5bfd0e8eecfbafaf4a90a3d0 0 f1.txt
100644 9b96e21cb748285ebec53daec4afb2bdcb9a360a 0 f2.txt
由于我们还没有对 index 文件做任何修改,它和我们用于生成index文件的树完全一致。一旦我们在 index 文件中有了正确的结构,我们就可以通过带有 -a 选项的 checkout-index 命令将它检出到工作目录:
$ git checkout-index -a
$ ls
f1.txt f2.txt
$ cat f1.txt
f1 content
$ cat f2.txt
f2 content
对的!我们已经将没使用任何 commit 就添加到 git 仓库中的内容检出了。是不是很酷?

但是 index 文件并非总是停留在初始树的状态。你可能知道它可以通过这些命令改变,git add [file path] 和 git rm --cached [file path] 处理单个文件,git add . 和 git reset 处理一批已修改/已删除的文件。我们将这个知识用于实践,在仓库中创建一个新的树,这个树包含一个和文本文件 f3.txt 关联的 blob 文件。文件的内容就是字符串 f3 content。但是和前一节手动创建树不一样,我们将使用index文件来创建。
现在我们的 index 文件结构如下,
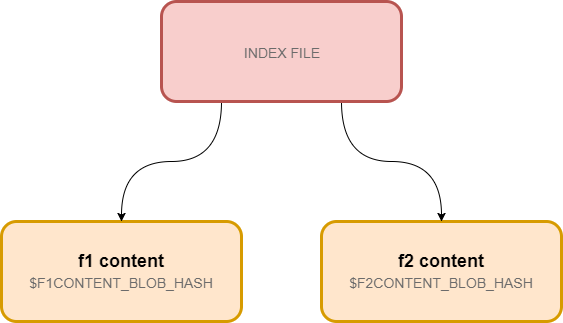
这就是我们应用修改的基准。你对 index 文件所做的所有修改在将树写入仓库之前都是暂时的。然而你添加的对象是立刻写入到仓库的。如果你放弃当前对树的修改,这些对象稍后会被垃圾回收搜集并删除。 这意味着如果你不小心丢弃了对某一个文件的修改,在 git 运行 GC 之前是可以恢复的。垃圾回收通常发生在有太多的未引用对象时才发生。
我们来删除工作目录中的两个文件:
$ rm f1.txt f2.txt
如果我们运行git status 我们会看到以下信息:
$ git status
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: f1.txt
new file: f2.txt
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
deleted: f1.txt
deleted: f2.txt
信息有点多。有两个文件被删除、两个新文件同时还是 “Initial commit”。我们来看看为什么。当你运行 git status 时,git做了两个比较:
- 将 index 文件和当前的工作目录比较 --变化是 “not staged for commit”
- 将 index 文件和 HEAD 提交比较 --变化是 “to be committed”
所以在这里我们看到 git 将两个已删除的文件报告为 “Changes not staged for commit”,我们已经知道这个信息是怎产生的--它将当前的工作目录和 index 文件比较发现工作目录丢失两个文件(因为我们刚才删除了)。
我们同时还看在 “Changes to be committed” 下面 git 报告了了两个新文件。这是因为到目前为止我们的仓库中还没有任何提交,所以这个 HEAD 文件(我们稍后做详细的解释)指向一个所谓的“空树”对象(没有任何文件)。所以 Git 以为我们刚刚创建了一个新的仓库,所以为什么它显示 “Initial commit”,并将 index 文件中的所有文件都当做新文件。
现在如果我们执行 git add . 它将修改 index 文件(删除了两个文件),然后再次执行 git status 就会显示没有任何修改,因为现在我们的工作目录和 index 文件中都没有文件:
$ git add .
$ git status
On branch master
Initial commit
nothing to commit (create/copy files and use "git add" to track)
我们继续通过创建新文件 f3.txt 来创建一个新的树。
$ echo ‘f3 content’ > f3.txt
$ git add f3.txt
如果现在运行 git status:
$ git status
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: f3.txt
我们发现检查到了一个新文件。同样,这个修改是报告在 "Changes to be committed" 下,所以现在 Git 是将 index 文件和 “空树” 作比较。所以认为 index 文件中已经有了新的文件 blob。我们来确认一下:
$ git ls-files -s
100644 5927d85c2470d49403f56ce27afd8f74b1a42589 0 f3.txt
# Save the hash of the f3.txt file blob
$ F3CONTENT_BLOB_HASH=5927d85c2470d49403f56ce27afd8f74b1a42589
好了,index 的结构是正确的,我们现在可以通过这个 index 在仓库中创建一个树。我们通过 write-tree 命令来完成:
$ LATEST_TREE_HASH=$( git write-tree )
很棒。我们刚才通过 index 创建了一个树。并且将新的树的哈希值存到了 LATEST_TREE_HASH 变量。我们已经通过手动将 f3 content blob 写入到仓库并且通过 mktree 来创建了一个树,但是使用 index 文件更方便。
有趣的是如果你现在运行 git status 你会发现git 仍然认为存在一个新文件 f3.txt:
$ git status
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: f3.txt
那是因为尽管我们已经创建了一个树并将它存入了仓库,但是我们还没有更新用于比较的 HEAD 文件。
所以加上我们新创建的树,仓库中有以下对象:

Commit就是对树的一次封装
在这一节中将变得更有趣。在我们日常的 Git 使用中,我们基本不会使用树或者 blob。我们和 commit 对象交互。所以 git 中的 commit 是什么?实际上,简单说它就是对树对象的封装:
- 允许给一个树(一组文件)添加消息
- 允许指定父 commit
现在我们的仓库中有两个树--initial tree 和 latest tree。我们通过 commit-tree 命令将第一个树封装成一个 commit(将树的哈希值传递给它):
INITIAL_COMMIT_HASH=$( \
echo 'initial commit' | git commit-tree $INITIAL_TREE_HASH )
在运行上面的命令之后:
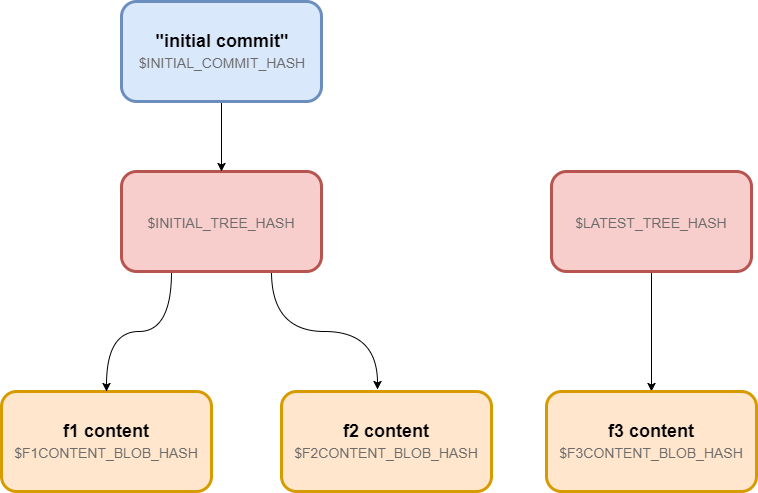
现在我么可以将这个commit检出到工作目录:
$ git checkout $INITIAL_COMMIT_HASH
A f3.txt
HEAD is now at a27a75a... initial commit
我们现在可以看到 f1.txt f2.txt 处于工作目录中:
$ ls
f1.txt f2.txt
$ cat f1.txt
f1 content
$ cat f2.txt
f2 content
当你运行 git checkout [commit-hash] 时,git 做了如下动作:
- 将 commit 点的树读入到 index 文件
- 将 index 文件检出到工作目录
- 使用 commit 的哈希值更新 HEAD 文件
这些都是我们在上一节手动执行的操作。
Git历史就是一串commit
所以现在我们知道了一个 commit 就是对一个树的封装。我也讲到一个 commit 可以有一个父 commit。我们最初有两个树并在上一节将其中一个封装成了一个commit,所以现在我们还有一个孤立的树。我们来将它封装成另外一个 commit 并指定其父 commit 为 initial commit。我们会使用和前一节相同的操作 commit-tree,不过需要通过-p 选项来指定父 commit。
$ LATEST_COMMIT_HASH=$( \
echo 'latest commit' |
git commit-tree $LATEST_TREE_HASH -p $INITIAL_COMMIT_HASH )
现在应该是这样:
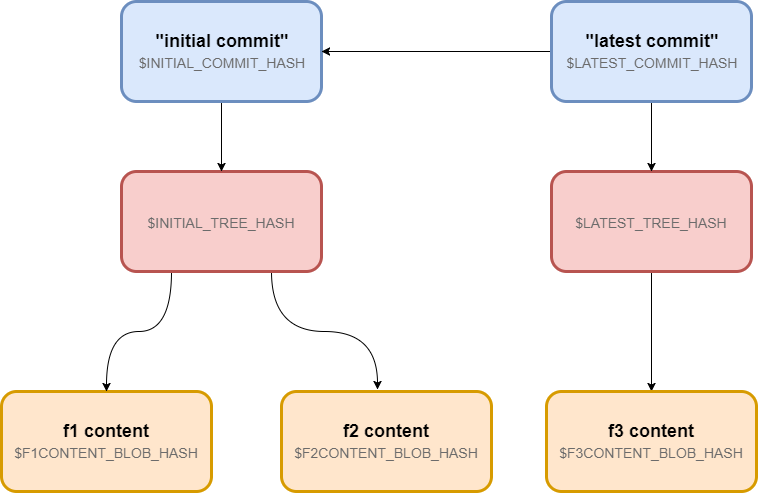
所以如果你现在将最后一次 commit 的哈希值传递给 git log 你会看到提交历史中有两条提交记录:
$ git log --pretty=oneline $LATEST_COMMIT_HASH
[some hash] latest commit
[some hash] initial commit
并且你可以在他们之间切换。这里是 initial commit:
$ git checkout $INITIAL_COMMIT_HASH
$ ls
f1.txt f2.txt
latest commit
$ git checkout $LATEST_COMMIT_HASH
$ ls
f3.txt
HEAD 是对已检出的 commit 的引用
HEAD 是存放在 .git/HEAD 的文本文件,它是对当前已检出 commit 的引用。由于我们在前面一节中通过 $LATEST_COMMIT_HASH 检出了最后的commit,此时 HEAD 文件包含的全部内容:
$ cat .git/HEAD
88d3b9901d62fc1de9219f388e700d98bdb97ba9
$ [ $LATEST_COMMIT_HASH == "88d3b9901d62..." ]; echo 'equal'
equal
然而,通常 HEAD 文件是通过分支引用来引用当前检出的 commit。当它直接引用一个 commit 的时候它是处于 detached state(分离状态)。但是即使当 HEAD 像这样通过分支持有一个引用:
ref: refs/heads/master
它仍然是引用一个 commit 的哈希值。
你现在知道了在执行 git status 命令时, Git 使用通过HEAD 引用的 commit 来产生一系列 index 文件和当前检出的树/commit 之间的修改。HEAD 的另外一个用途就是决定下一个 commit 的父 commit。
有趣的是,HEAD 文件对大多数操作都是如此重要以至于如果你手动清除其内容,Git 将认为不是一个 git 仓库并报错:
fatal: Not a git repository (or any of the parent directories): .git
分支是一个指向某一个commit的文本文件
所以现在我们的仓库中有两条 commit,形成了如下提交历史:

$ git log --pretty=oneline $LATEST_COMMIT_HASH
[some hash] latest commit
[some hash] initial commit
我们在已有的历史中引入一个分叉。我们将检出最初的 commit 并修改 f1.txt 文件内容。然后使用你已经习惯的 git commit 命令创建一条新的 commit:
$ git checkout $INITIAL_COMMIT_HASH
$ echo 'I am modified f1 content' > f1.txt
$ git add f1.txt
$ git commit -m "forked commit"
1 file changed, 1 insertion(+), 1 deletion(-)
以上的代码片段:
- 检出
"initial commit"将f1.txt和f2.txt添加到工作目录 - 将
f1.txt的内容也替换为字符串I am modified f1 content - 使用
git add更新index 文件
最后这个我们熟悉的git commit命令内部做了以下操作: - 从 index 文件创建一个树
- 将树写入仓库
- 创建一个 commit 对象将树封装起来
- 将
initial commit作为新创建 commit 的父commit,因为当前HEAD文件中的 commit 就是initial commit。
我们同样需要将新的 commit 的哈希值存储到变量中。由于 Git 根据当前的 commit 文件更新 HEAD,我们可以这样读取这个值:
FORKED_COMMIT_HASH=$( cat .git/HEAD )
所以现在我们的 git 仓库中是这样一些对象的:

由此生成以下提交历史:

由于分叉的出现我们现在有两条工作线。这意味着我们需要引入两条分支独立跟踪每一条工作线。我们创建 master 分支来跟踪从 latest commit以来的直线历史,创建 forked 分支来跟踪自 forked commit 以来的历史。
一个分支就是一个文本文件,它包含了一个commit的哈希值。它是 git引用的一部分--引用一个 commit 的一组对象。另外一个引用类型是轻量的 tag。Git 将所有的引用存储到 .git/refs 目录,将所有分支存储在 .git/refs/heads 目录。由于分支就是一个文本文件,我们可以使用 commit 的哈希值来创建一个分支。
所以下面的分支将指向主分支的 "latest commit"。
$ echo $LATEST_COMMIT_HASH > .git/refs/heads/master
这一个分支将指向 "forked" 分支的 "forked commit":
$ echo $FORKED_COMMIT_HASH > .git/refs/heads/forked

所以最终我们回到了你常常使用的工作流---我们现在可以在分支之间切换:
$ git checkout master
Switched to branch 'master'
$ git log --pretty=oneline
[some hash] latest commit
[some hash] first commit
$ ls -l
f3.txt
一起来看看另外一个 forked 分支:
$ git checkout forked
Switched to branch 'forked'
$ git log --pretty=oneline
f30305a8a23312f70ba985c8c644fcdca19dab95 forked commit
f30305a8a23312f70ba985c8c644fcdca19dab95 initial commit
$ git ls
f1.txt f2.txt
$ cat f1.txt
I am modified f1 content
一个 tag 就是指向某一个 commit 的文本文件
你兴许已经知道除了使用分支(一条工作线的)还可以使用 tag 来跟踪单独的 commit。Tag 通常用于标记重要的开发节点如版本发布。现在我们的仓库中有3个 commit。我们可以使用 tag 来给它们命名。和分支一样,一个 tag 就是一个文本文件,它包含了一个 commit 的哈希值,同样也是引用组的一部分。
你已经知道 git 将所有的引用都存储在 .git/refs 目录,所以tag都存储在 .git/refs/tags 子目录。由于它就是一个文本文件,我们可以创建一个文件并将 commit 的哈希值写入其中。
所以这个 tag 会指向 latest commit:
$ echo $FORKED_COMMIT_HASH > .git/refs/tags/forked
这个 tag 会指向 initial commit:
$ echo $INITIAL_COMMIT_HASH > .git/refs/tags/initial
一旦完成了这一步我们就可以使用 tag 在 commit 之间切换。这样就可以切换到 initial commit:
$ git checkout tags/initial
HEAD is now at 285aec7... second commit
$ cat f1.txt
f1 content
这样就切换到 forked commit:
$ git checkout tags/forked
$ cat f1.txt
I am modified f1 content
此外还有 "annotated-tag",它和我们现在使用的轻量级 tag有所不同。它是一个对象,可以像commit一样包含信息,并且是其他对象一起存放在仓库中。
本文译自Become a GIT pro by learning GIT architecture in 15 minutes
