计算与存储分离,为你大幅降低成本 https://promotion.aliyun.com/ntms/act/emractivity02.html
如果把计算与存储分离后,则集群规划则变得简单很多,基本不需要估算未来业务的规模了,真正做到按需使用。
摘要: Hadoop一出生就是存储与计算在一起的,前几年面试题中都问,Hadoop怎么保证高性能呢?其中一个原因是存储不动,计算(code)动,不同于传统的集中式的存储模式。那我们为什么还要谈存储计算分离呢?众观历史,分久必合、合久必分,在计算机历史中也很类似,如今,也许到了计算与存储分离的阶段。后面我们以实际的case说明,分离的好处与劣势。特别推荐 E-MapReduce产品。
1.58元起,快速体验 Hadoop & Spark 等,点击使用
为什么呢?
先说一个大家常在日常生活中遇到的经历:家里带宽自从升级到100mpbs,从来不保存电影,要看直接下载,基本几分钟就好了。这在几年前不可想象。其中有本地化的挑战:
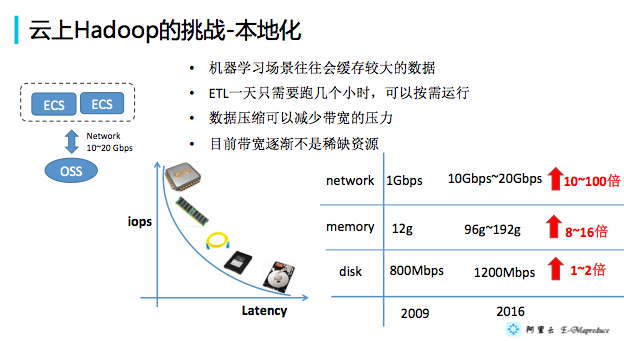
带宽的速度,特别是机房内带宽的速度,已经从1000mps、2000mps、10000mps,甚至100000mpbs。但是磁盘的速度基本没有太大的变化。因为硬件的变化,带来了软件架构的变化。
基本架构

架构其实比较简单,OSS作为默认的存储,Hadoop、Spark可以作为计算引擎直接分析OSS存储的数据。
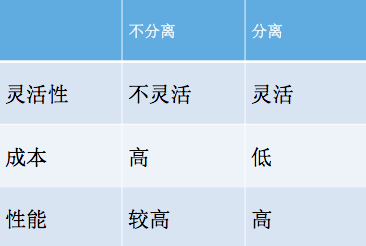
以上比较了计算与存储分离的优缺点。
灵活:在《E-MapReduce(Hadoop)10大类问题之集群规划》 一文中分析了集群规划问题,关键是匹配计算量与存储量,如果把计算与存储分离后,则集群规划则变得简单很多,基本不需要估算未来业务的规模了,真正做到按需使用。
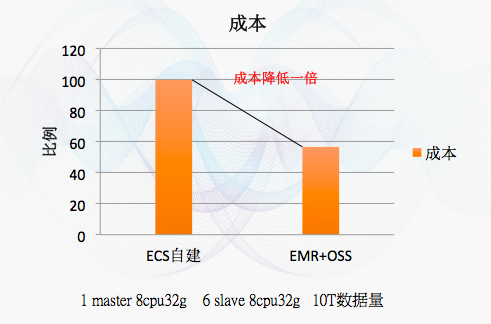
成本:存储与计算分离后,按照1 master 8cpu32g 6 slave 8cpu32g 10T数据量,大致成本下降一倍,在ecs自建的磁盘选择高效云盘。
性能:大约下降10%以内,对于一般的应用是可以接受的,后续详细说明。
分析
我们可以看到,emr+oss后,成本节约了一半,但是性能下降基本可以忽略不计。从性能图上看,emr+oss对比ecs自建hadoop对比:

也就是整体来讲,emr+oss比自建使用更少的资源,如果提高emr+oss的并发度,则时间上有可能超过ecs自建hadoop集群的。
//
存储与计算的分离 http://crad.ict.ac.cn/CN/abstract/abstract806.shtml
当前计算应用的发展对传统计算机体系结构提出了挑战.由计算资源和存储资源固定连接形成的系统已经不能适应动态计算的需求.从应用出发,提出计算资源和存储资源物理分离和逻辑分离的概念,并以此为基础,构造三维可重构计算环境可以解决这些问题.在这种环境中,用户程序、计算资源和存储资源可以根据应用的需求动态组合.由于摆脱了资源的地理位置和操作环境等方面的限制,计算过程将呈现出数据驱动的特点,从而实现按需计算,使计算系统可以在更大范围内为用户提供服务.
