官方原文地址:https://kafka.apache.org/0101/documentation.html#log
包含两个partition,名称为“my_topic”的Topic的日志包含两个目录(名称为my_topic_0和my_topic_1),其中包含该Topic的消息的数据文件。日志文件的格式是log entry的序列;每个log entry都是4字节的消息长度N加上后面N个字节的消息数据。每条消息都有一个64位的offset标识这条消息在这个Topic的Partition中的偏移量。消息在磁盘中的存储格式如下所示。每个日志文件都以它存储的第一条消息的offset命名。所以第一个文件会命名为00000000000.kafka,随后每个文件的文件名将是前一个文件的文件名加上S的正数,S是配置中指定的单个文件的大小。
消息的确切的二进制格式都有版本,它保持一个标准的接口,让消息集可以根据需要在Producer、Broker、Consumer之间传输而不需要重新拷贝或者转换,其格式如下:
On-disk format of a message
offset : 8 bytes
message length : 4 bytes (value: 4 + 1 + 1 + 8(if magic value > 0) + 4 + K + 4 + V)
crc : 4 bytes
magic value : 1 byte
attributes : 1 byte
timestamp : 8 bytes (Only exists when magic value is greater than zero)
key length : 4 bytes
key : K bytes
value length : 4 bytes
value : V bytes
使用消息的Offset作为消息ID是不常见的。我们初始的想法是在Producer生成一个GUID作为Message ID,并在Broker上维持ID和Offset之间的映射关系。但是因为Consumer需要为每个Server维持一个ID,那么GUID的全局唯一性就变得没什么意义了。此外,维持一个随机的ID和Offset的映射关系将给索引的构建带来巨大的负担,本质上需要一个完整的持久化的随机存取的数据结构。因此,为了简化查找结构,我们决定使用每个分区的原子计数器,它可以和分区ID加上ServerID来唯一标识一条消息。一旦使用了计数器,直接使用Offset进行跳转是顺其自然的,两者都是分区内单调递增的整数。由于偏移量从消费者API中隐藏起来,因此这个决定是最终的实现细节,所以我们采用更有效的方法。
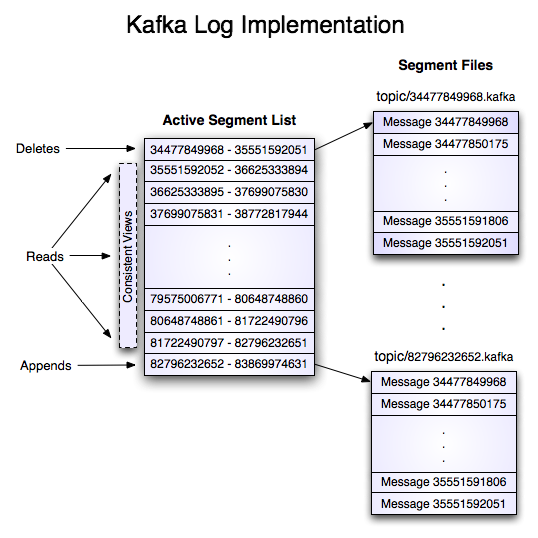
Writes
日志允许连续追加到最后一个文件。当文件达到配置的大小时(如1GB)将滚动到一个新文件。日志采用两个配置:M,配置达到多少条消息后进行刷盘;S,配置多长时间之后进行刷盘。这个持久化策略保证最多只丢失M条消息或者S秒之内的消息。
Reads
读取通过提供64位的offset和S-byte的chunk大小来实现。这将返回包含在S-byte的buffer的消息迭代。S比任意单条消息都大,但是如果在异常的超大消息的情况下,读取操作可以通过多次重试,每次都将buffer大小翻倍,直到消息被读取成功。最大消息大小和buffer大小可以配置,用于拒绝超过特定大小的消息,以限制客户端读取消息时需要拓展的buffer大小。buffer可能以不完整的消息作为结尾,这可以通过消息大小来轻松的检测到。
实际的读取操作首先需要定位offset所在的文件,再将offset转化为文件内相对的偏移量,然后从文件的这个偏移量开始读取数据。搜索操作通过内存中映射的文件的简单的二分查找完成。
日志提供了获取最近写入消息的能力以允许客户端从“当前时间”开始订阅。这在客户端无法在指定天数内消费掉消息的场景中非常有用。在这种情况下,如果客户端尝试消费一个不存在的offset将抛出OutOfRangeException异常并且可以根据场景重置或者失败。
下面是发送到Consumer的数据的格式:
MessageSetSend (fetch result)
total length : 4 bytes
error code : 2 bytes
message 1 : x bytes
...
message n : x bytes
MultiMessageSetSend (multiFetch result)
total length : 4 bytes
error code : 2 bytes
messageSetSend 1
...
messageSetSend n
Deletes
数据删除一次删除一个日志段。日志管理器允许通过插件的形式实现删除策略来选择那些文件是合适删除的。当前的删除策略是日志文件的修改时间已经过去N天,保留最近N GB数据的策略也是有用的。为了避免删除时锁定读取操作,我们采用copy-on-write的方式来实现,以保证一致性的视图。
Guarantees
日志提供了配置参数M,用于控制写入多少条消息之后进行一次刷盘。在日志恢复过程中遍历最新的日志段的所有消息并验证每一条消息是有效的。如果消息的大小和偏移量之和小于文件长度并且消息的CRC32和存储的CRC相同,那么消息是有效的。在异常事件被检测到时,日志会被截取到最后一条有效的消息的offset。
两种错误需要处理:因为Crash导致的written块丢失和无意义的block被添加到文件中。这样做的原因是,一般的操作系统不保证file inode和实际数据块之间的写入顺序,所以除了丢失written data,文件还会获得无意义的数据,在inode更新大小但是在block写入数据之前。CRC检测这个错误并防止损坏日志(unwritten的消息肯定会丢失)。
