到目前为止Kubernetes对基于cpu使用率的水平pod自动伸缩支持比较良好,但根据自定义metrics的HPA支持并不完善,并且使用起来也不方便。
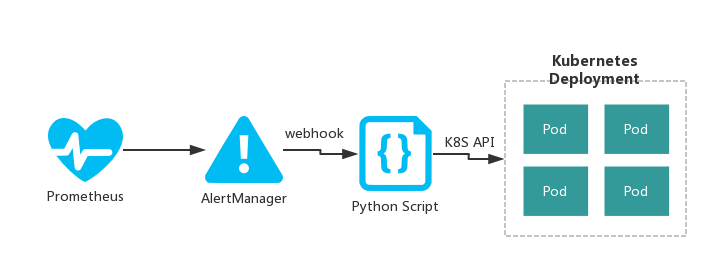
下面介绍一个基于Prometheus和Alertmanager实现Kubernetes Pod 自动伸缩的方案,该方案支持任意自定义metrics。思路比较简单:由Prometheus负责收集需要的性能指标(如:当前链接的并发数,当前cpu的使用率等),根据定义好的告警规则生成告警事件,然后将告警事件传递给Alertmanager,由alertmanager触发webhook来实现最终的pod伸缩功能,如下图所示:
Prometheus中Alert rules的配置示例:
ALERT HpaTrigger
IF app_active_task_count > 30
FOR 30m
LABELS {serverity = "page",trigger="hpa",action = "scale-out",value = "{{$value}}", deployment="test", namespace = "{{$labels.namespace}}"}
ANNOTATIONS {
summary = "Instance {{$labels.namespace}}: scale-out",
description = "{{$labels.namespace}} auto scale-out"
}
上述规则表示应用的活动任务数持续30分钟都大于30的话,就需要创建新的pod以应对过多的任务数。但此处并不会直接触发水平Pod自动伸缩功能,prometheus根据告警规则只会生成一个告警事件,并将该事件传递给alertmanager,由alertmanager决定如何处理该告警。
Alertmanager配置示例:
global:
route:
receiver: 'email' #全局配置,默认将收到的告警事件路由给email接收器
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
routes:
- receiver: 'auto-hpa' #将trigger=hpa的告警路由给auto-hpa
match:
trigger: hpa
receivers:
- name: 'email'
email_configs:
- to: ops@test.com
from: monitor@test.com
smarthost: smtpserver:port
auth_username: "username"
auth_identity: "username"
auth_password: "password"
require_tls: true
- name: "auto-hpa"
webhook_configs:
- url: 'http://YOUR_WEBHOOK_IP:PORT/hpa' #自定义webhook url地址。
send_resolved: true
Alertmanager接受到相应的告警之后,会将获取到的具体metics值(此处metric name为app_active_task_count)和在告警规则中定义的LABELS信息合并为一个json数据,以POST方式发送给我我们定义好的webhook url。
webhook Python脚本示例:
from flask import Flask,request
import json
app = Flask(__name__)
@app.route("/hpa",methods=["POST"])
def hpa():
content = request.get_json()
#分析content字段,提取相关数据,调用k8s api实现水平pod自动伸缩的功能
#.......
#.......
print content
if __name__ == "__main__":
app.run("0.0.0.0")
这里我省略了具体调用k8s api实现pod伸缩的逻辑。Alertmanager将所有的信息以json格式post给我们自定义的脚本了,具体怎么处理,就看业务需求了。
