springboot : 二级缓存
标签(空格分隔): springboot ehcache hazelcast 缓存 @Cacheable
因为ehcache比较出名,而且之前一个再工作过的一个公司也用过,所以本来是想重温一下ehcache的,没想到一不小心发现了hazelcast,根据hazelcast vs ehcache的描述和Red Hat Infinispan/JBoss vs Hazelcast IMDG Benchmark中的比较结果,觉得hazelcast应该是一个相当不错的东西,所以干脆研究了一下它,不过真的是非常的粗浅了。
架构
官网上有个架构图
原理
一般来说架构和原理是相关的,但是我并没有从上面图中体会到太多的东西,倒是从一份白皮书An Architect’s View of Hazelcast中知道"Hazelcast can be treated as an implementation of the familiar ConcurrentHashMap that can be accessed from multiple JVMs (Java Virtual Machine), including JVMs that are spread out across the network.",这可能就是本质的东西吧。
对于没有深入研究hazelcast的原理这件事情我是耿耿于怀的,但是实在是没有太多时间,以后有空再从hazelcast的重要的配置入手分析一下hazelcast一些关键机制的原理。
简单的使用
因为研究这个东西的目的是想用它缓存通过spring data jpa访问的东西,所以参考了文章JPA Caching With Hazelcast, Hibernate, and Spring Boot。
用文中提到的github的代码做试验会碰到各种问题,一般情况下如果碰到有这种问题的例子我是直接放弃的(吐槽一下,中文文章比比皆是这种情况),但是针对这个话题实在找不到其它的更好的文章了,而且确实又觉得hazelcast可能是个好东西,值得一试,所以只好把一些坑填掉,顺便做了一点小结写在这里。
坑1
这个其实和文章没关系,没有研究这个坑是eclipse还是eclipse内置的maven的问题,pom.xml中出现了"Multiple annotations found at this line",参考Eclipse | Maven : Multiple annotations found at this line,"manually go to the org/apache folder and delete everything and then follow step 1"就能解决这个问题。
这个问题我在很多项目都碰到过,以前好像有时候不处理也没问题,但是针对这个项目,不解决这个问题,文章中的pom.xml的一些依赖是解决不了的,实验是做不下去的。
坑2
Entity中的变量名是firstName,但是sql语句中对应的字段变成first_name,导致数据库操作失败。参考Spring Boot + JPA : Column name annotation ignored,application.properties(文章中用的是yml格式的配置,稍微改一下就好了)加上:
spring.jpa.hibernate.naming.implicit-strategy=org.hibernate.boot.model.naming.ImplicitNamingStrategyLegacyJpaImpl
spring.jpa.hibernate.naming.physical-strategy=org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
坑3
如果使用的是文章中提到的
docker run -d --name hazelcast-mgmt -p 38080:8080 hazelcast/management-center:latest
pull下来并执行的hazelcast-mgmt,那么最新版本的hazelcast-mgmt访问url应该是
http://你运行hazelcast-mgmt的主机的ip:38080/hazelcast-mancenter
而不是文章提到的 http://ip:38080/mancenter 。
这个很重要,因为除了没办法通过浏览器访问hazelcast mancenter之外,如果hazelcast.xml的这个url配置错了,各个hazelcast实例就没有办法和管理中心通信,hazelcast-mgmt的存在就毫无意义了。
坑4
对于hazelcast集群来说,如果hazelcast是在docker容器中跑的,那么每个hazelcast实例应该做的配置在文章提出的解决方案是使用network配置的public-address项,但是实际上是行不通的,需要参考 docker hazelcast cluster中的说明,使用
docker run -e JAVA_OPTS="-Dhazelcast.local.publicAddress=192.168.158.146:5702" -d --name hazelcast2 -p 5702:5701 hazelcast/hazelcast
docker run -e JAVA_OPTS="-Dhazelcast.local.publicAddress=192.168.158.146:5701" -d --name hazelcast -p 5701:5701 hazelcast/hazelcast
启动两个hazelcast,才能成功看到一个hazelcast集群工作的。
重点是 -e JAVA_OPTS="-Dhazelcast.local.publicAddress=192.168.158.146:5702" 启动参数,这个东西其实和文章中说的配置应该是一回事,但是不知道是不是版本问题,文章中的方案就是不能用。
实际上如果不是用docker就不会有这个问题,因为假如不需要使用hazelcast-mancenter对集群进行监视的话,在不使用docker的情况下是不用做任何配置也能搭起一个hazelcast集群的。
坑5
hazelcast集群挂掉的情况下,如果在HazelcastInstance这个Bean中没有使用 ClientConfig.getNetworkConfig().setConnectionAttemptLimit(Integer.MAX_VALUE) ,是没办法最大程度的保证(虽然无法完全)hazelcast集群挂掉后重启还能用的。如果没有这个配置,会出现所有涉及数据库访问的请求在集群挂掉重启后都会失败。
其它需要注意的
除了上面说的需要注意之外,@Cacheable的使用也是要特别注意的。@Cacheable的原理可以从下面图窥探一二。
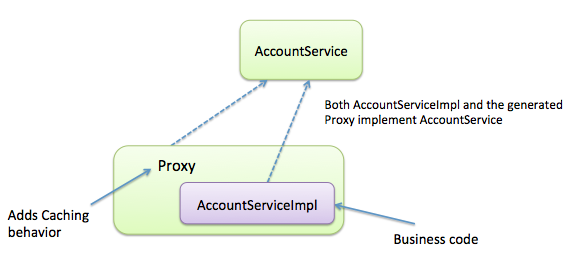
其中Proxy是核心的东西,函数加了@Cacheable之后能对它的返回值做缓存关键的原理就是Proxy,Proxy对函数进行了封装,达到缓存中有东西就读缓存没东西才调用函数的效果。需要注意的就是@Cacheable注解的函数必须在一个Bean中,如果用New出来的对象访问被@Cacheable注解的函数,是没办法让Proxy起作用的,因为New是不认识@Cacheable注解的。
