方便修改贴github地址: spark-knowledge系列
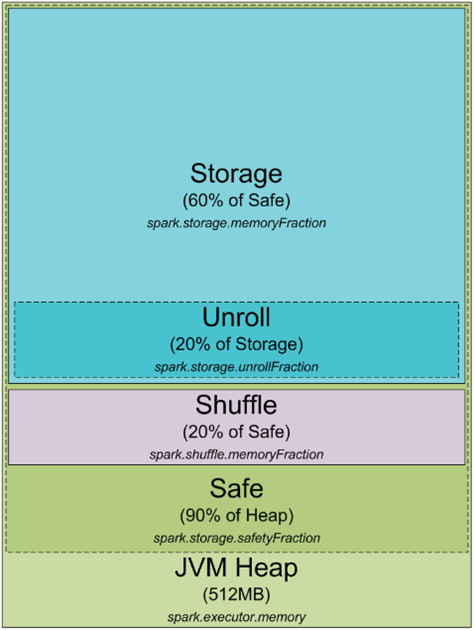
spark进程是以JVM进程运行的,可以通过-Xmx和-Xms配置堆栈大小,它是如何使用堆栈呢?下面是spark内存分配图。
image
storage memory
spark默认JVM堆为512MB,为了避免OOM错误,只使用90%。通过spark.storage.safetyFraction来设置。spark通过内存来存储需要处理的数据,使用安全空间的60%,通过 spark.storage.memoryFraction来控制。如果我们想知道spark可以缓存多少数据?假设使用executors数为N,那么缓存数据为N*90%*60%*512MB。
shuffle memory
shuffle memory的内存为“Heap Size” * spark.shuffle.safetyFraction * spark.shuffle.memoryFraction。默认spark.shuffle.safetyFraction 是 0.8 , spark.shuffle.memoryFraction是0.2 ,因此shuffle memory为 0.8*0.2*512MB = 0.16*512MB
unroll memory
unroll memory的内存为spark.storage.unrollFraction * spark.storage.memoryFraction * spark.storage.safetyFraction,即0.2 * 0.6 * 0.9 * 512MB = 0.108 * 512MB。unroll memory用作数据序列化和反序列化。
