count 优化
案例,在一条SQL语句中同时查出2006年和2007年电影的数量
错误方式:
1、 select count(release_year='2006' or release_year='2007') from film;
无法分开计算2006和2007年的电影数量
2、select count(*) from film where release_year='2006' and release_year='2007';
release_year不可能同时为2006和2007,因此逻辑上有错误
正确写法:
select count(release_year='2006' or null) as '2006film', count(release_year='2007' or null) as '2007film' from film;
max 优化
给需要计算max列添加索引
子查询优化
通常情况下,需要将子查询优化为join查询,但在优化时要注意关联键是否有一对多的关系,要注意重复数据
例如
select p.*, y.yarn_ratio from new_products as p join new_product_yarn_ratios as y on y.product_id=p.id \G
会返回200条数据,里面就有重复的.
这时候需要用到关键字distinct:
select distinct p.*, y.yarn_ratio from new_products as p join new_product_yarn_ratios as y on y.product_id=p.id \G
,这时候返回195条。
group by查询优化
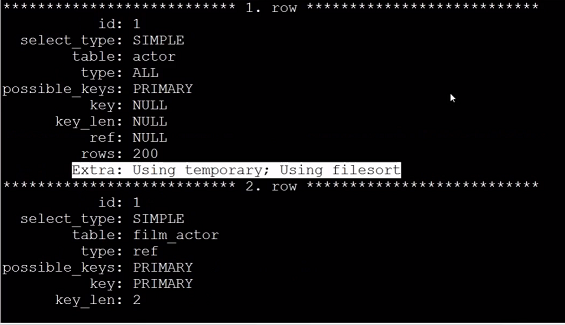
案例:查询演员的参演次数
explain select actor.first_name, actor.last_name, count(*)
from sakila.film_actor
inner join sakila.actor using(actor_id)
group by film_actor.actor_id;
执行方案:
改写后:
explain select actor.first_name, actor.last_name, c.cnt
from sakila.actor inner join (
select actor_id, count(*) as cnt from sakila.film_actor group by
actor_id
) as c using(actor_id);
执行方案:
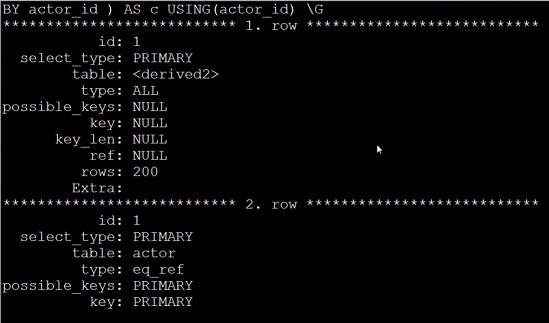
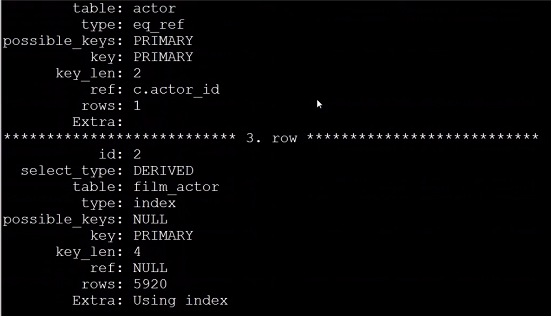
改写后,虽然也存在200行的表扫描,但是已经没有使用临时表,减少了IO,响应的也提高了效率
limit查询优化
limit常用于分页处理,时常会伴随order by从句使用,因此大多时候会使用filesorts,这样会造成大量的IO问题
案例:select film_id, description from sakila.film order by title limit 50, 5;
执行分析:
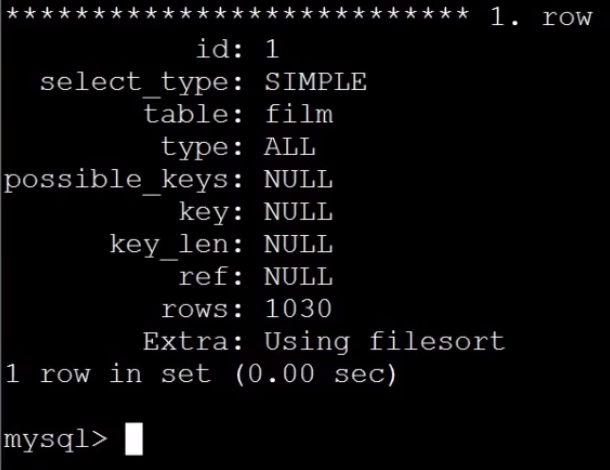
优化步骤1:使用有索引的列或主键进行order by操作
select film_id, description from sakila.film order by film_id limit 50, 5;
执行分析:
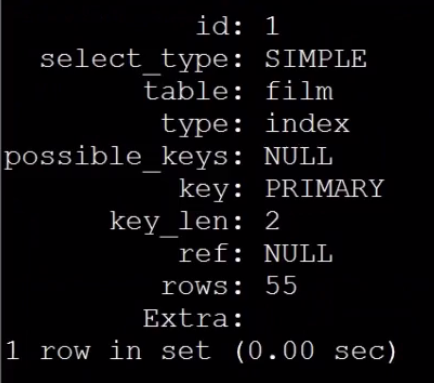
优化步骤2:记录上次返回的主键,在下次查询时使用主键范围过滤
select film_id, description from sakila.film where film_id > 600 and film_id <= 605 order by film_id limit 50, 5;
执行分析:
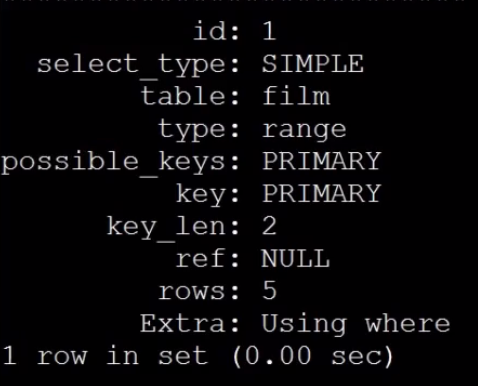
这样,每次扫描的行数都固定为5列。但是这样子对于一些主键不是连续的就会存在一些问题,为解决这个问题,可以建一列辅助列保证其实自增的即可。
参考网站:
